This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
1) What Is Data Quality Management? 4) Data Quality Best Practices. 5) How Do You Measure Data Quality? 6) Data Quality Metrics Examples. 7) Data Quality Control: Use Case. 8) The Consequences Of Bad Data Quality. 9) 3 Sources Of Low-Quality Data. 10) Data Quality Solutions: Key Attributes.
Amazon DataZone is a data management service that makes it faster and easier for customers to catalog, discover, share, and govern data stored across AWS, on premises, and from third-party sources. Using Amazon DataZone lets us avoid building and maintaining an in-house platform, allowing our developers to focus on tailored solutions.
Such a solution should use the latest technologies, including Internet of Things (IoT) sensors, cloud computing, and machine learning (ML), to provide accurate, timely, and actionable data. To take advantage of this data and build an effective inventory management and forecasting solution, retailers can use a range of AWS services.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that you can use to analyze your data at scale. Redshift Data API provides a secure HTTP endpoint and integration with AWS SDKs. Calls to the Data API are asynchronous.
Through a visual designer, you can configure custom AI search flowsa series of AI-drivendata enrichments performed during ingestion and search. Each processor applies a type of datatransform such as encoding text into vector embeddings, or summarizing search results with a chatbot AI service.
As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. Why: Data Makes It Different. Not only is data larger, but models—deep learning models in particular—are much larger than before.
The need to integrate diverse data sources has grown exponentially, but there are several common challenges when integrating and analyzing data from multiple sources, services, and applications. First, you need to create and maintain independent connections to the same data source for different services.
ChatGPT> DataOps, or data operations, is a set of practices and technologies that organizations use to improve the speed, quality, and reliability of their data analytics processes. The goal of DataOps is to help organizations make better use of their data to drive business decisions and improve outcomes.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
AI is transforming how senior data engineers and data scientists validate datatransformations and conversions. Artificial intelligence-based verification approaches aid in the detection of anomalies, the enforcement of data integrity, and the optimization of pipelines for improved efficiency.
Common challenges and practical mitigation strategies for reliable datatransformations. Photo by Mika Baumeister on Unsplash Introduction Datatransformations are important processes in data engineering, enabling organizations to structure, enrich, and integrate data for analytics , reporting, and operational decision-making.
Organizations with legacy, on-premises, near-real-time analytics solutions typically rely on self-managed relational databases as their data store for analytics workloads. Near-real-time streaming analytics captures the value of operational data and metrics to provide new insights to create business opportunities.
Additionally, this forecasting system needs to provide data enrichment steps including byproducts, serve as the master data around the semiconductor management, and enable further use cases at the BMW Group. To enable this use case, we used the BMW Group’s cloud-native data platform called the Cloud Data Hub.
As the world is gradually becoming more dependent on data, the services, tools and infrastructure are all the more important for businesses in every sector. Data management has become a fundamental business concern, and especially for businesses that are going through a digital transformation. What is data management?
In today’s data-driven world, the ability to seamlessly integrate and utilize diverse data sources is critical for gaining actionable insights and driving innovation. Use case Consider a large ecommerce company that relies heavily on data-driven insights to optimize its operations, marketing strategies, and customer experiences.
Data mesh is a new approach to data management. Companies across industries are using a data mesh to decentralize data management to improve data agility and get value from data. This is especially true in a large enterprise with thousands of data products.
For more information on this foundation, refer to A Detailed Overview of the Cost Intelligence Dashboard. It seamlessly consolidates data from various data sources within AWS, including AWS Cost Explorer (and forecasting with Cost Explorer ), AWS Trusted Advisor , and AWS Compute Optimizer.
Under the Transparency in Coverage (TCR) rule , hospitals and payors to publish their pricing data in a machine-readable format. For more information, refer to Delivering Consumer-friendly Healthcare Transparency in Coverage On AWS. Create separate folders for each hospital inside the S3 bucket.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it straightforward and cost-effective to analyze your data. Generative AI models can derive new features from your data and enhance decision-making.
We live in a world of data: There’s more of it than ever before, in a ceaselessly expanding array of forms and locations. Dealing with Data is your window into the ways data teams are tackling the challenges of this new world to help their companies and their customers thrive. What is data integrity? Data integrity risks.
Amazon Redshift , a warehousing service, offers a variety of options for ingesting data from diverse sources into its high-performance, scalable environment. This native feature of Amazon Redshift uses massive parallel processing (MPP) to load objects directly from data sources into Redshift tables.
If you can’t make sense of your business data, you’re effectively flying blind. Insights hidden in your data are essential for optimizing business operations, finetuning your customer experience, and developing new products — or new lines of business, like predictive maintenance. Azure Data Factory.
Infomedia Ltd (ASX:IFM) is a leading global provider of DaaS and SaaS solutions that empowers the data-driven automotive ecosystem. In this post, we share how Infomedia built a serverless data pipeline with change data capture (CDC) using AWS Glue and Apache Hudi.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing ETL (extract, transform, and load), business intelligence (BI), and reporting tools.
Although Jira Cloud provides reporting capability, loading this data into a data lake will facilitate enrichment with other business data, as well as support the use of business intelligence (BI) tools and artificial intelligence (AI) and machine learning (ML) applications.
Alerts and notifications play a crucial role in maintaining data quality because they facilitate prompt and efficient responses to any data quality issues that may arise within a dataset. It simplifies your experience of monitoring and evaluating the quality of your data.
To build a data-driven business, it is important to democratize enterprise data assets in a data catalog. With a unified data catalog, you can quickly search datasets and figure out data schema, data format, and location. You can refer to Table & SQL Connectors for more information.
In our last blog , we delved into the seven most prevalent data challenges that can be addressed with effective data governance. Today we will share our approach to developing a data governance program to drive datatransformation and fuel a data-driven culture. Don’t try to do everything at once!
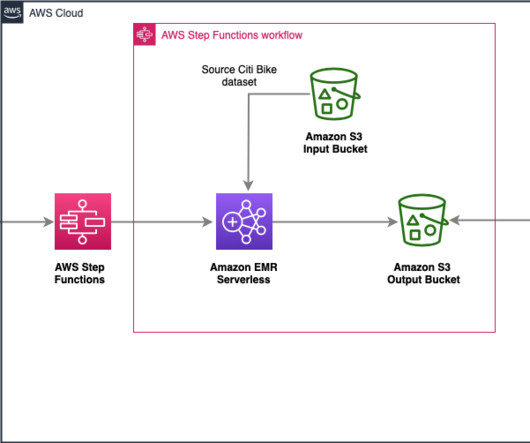
You can run analytics workloads at any scale with automatic scaling that resizes resources in seconds to meet changing data volumes and processing requirements. AWS Step Functions is a serverless orchestration service that enables developers to build visual workflows for applications as a series of event-driven steps.
This allows you to simplify security and governance over transactional data lakes by providing access controls at table-, column-, and row-level permissions with your Apache Spark jobs. Many large enterprise companies seek to use their transactional data lake to gain insights and improve decision-making.
Data is a key enabler for your business. Many AWS customers have integrated their data across multiple data sources using AWS Glue , a serverless data integration service, in order to make data-driven business decisions. Are there recommended approaches to provisioning components for data integration?
You can’t talk about data analytics without talking about data modeling. The reasons for this are simple: Before you can start analyzing data, huge datasets like data lakes must be modeled or transformed to be usable. Building the right data model is an important part of your data strategy.
Attempting to learn more about the role of big data (here taken to datasets of high volume, velocity, and variety) within business intelligence today, can sometimes create more confusion than it alleviates, as vital terms are used interchangeably instead of distinctly. Big data challenges and solutions.
Today, in order to accelerate and scale data analytics, companies are looking for an approach to minimize infrastructure management and predict computing needs for different types of workloads, including spikes and ad hoc analytics. Prerequisites To complete the integration, you need a Redshift Serverless data warehouse.
What Is Data Governance In The Public Sector? Effective data governance for the public sector enables entities to ensure data quality, enhance security, protect privacy, and meet compliance requirements. With so much focus on compliance, democratizing data for self-service analytics can present a challenge.
Chances are, you’ve heard of the term “modern data stack” before. In this article, I will explain the modern data stack in detail, list some benefits, and discuss what the future holds. What Is the Modern Data Stack? It is known to have benefits in handling data due to its robustness, speed, and scalability.
A closer look at the importance (and transformational value) of your organisation’s data landscape. After decades in the background, data is currently king of the business world. Over 70% of digital transformations fail, and most CDOs last less than two-and-half years. What is a data landscape?
In the era of data, organizations are increasingly using data lakes to store and analyze vast amounts of structured and unstructured data. Data lakes provide a centralized repository for data from various sources, enabling organizations to unlock valuable insights and drive data-driven decision-making.
In today’s data-driven landscape, businesses are constantly seeking innovative solutions to harness the power of analytics effectively. Embedded BI tools have emerged as a transformative force, seamlessly integrating analytical capabilities directly into existing software applications.
These initiatives utilize interconnected devices and automated machines that create a hyperbolic increase in data volumes. This type of growth has stressed legacy data management systems and makes it nearly impossible to implement a profitable data-centered solution. High-level example of a common machine learning lifecycle.
Healthcare is changing, and it all comes down to data. Data & analytics represents a major opportunity to tackle these challenges. Indeed, many healthcare organizations today are embracing digital transformation and using data to enhance operations. How can data help change how care is delivered?
Many thanks to AWP Pearson for the permission to excerpt “Manual Feature Engineering: Manipulating Data for Fun and Profit” from the book, Machine Learning with Python for Everyone by Mark E. Feature engineering is useful for data scientists when assessing tradeoff decisions regarding the impact of their ML models.
Where they have, I have normally found the people holding these roles to be better informed about data matters than their peers. Prelude… I recently came across an article in Marketing Week with the clickbait-worthy headline of Why the rise of the chief data officer will be short-lived (their choice of capitalisation).
By leveraging data analysis to solve high-value business problems, they will become more efficient. This is in contrast to traditional BI, which extracts insight from data outside of the app. that gathers data from many sources. These tools prep that data for analysis and then provide reporting on it from a central viewpoint.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content