This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
1) What Is Data Quality Management? 4) Data Quality Best Practices. 5) How Do You Measure Data Quality? 6) Data Quality Metrics Examples. 7) Data Quality Control: Use Case. 8) The Consequences Of Bad Data Quality. 9) 3 Sources Of Low-Quality Data. 10) Data Quality Solutions: Key Attributes.
At Atlanta’s Hartsfield-Jackson International Airport, an IT pilot has led to a wholesale data journey destined to transform operations at the world’s busiest airport, fueled by machine learning and generative AI. That enables the analytics team using Power BI to create a single visualization for the GM.”
Table of Contents 1) Benefits Of Big Data In Logistics 2) 10 Big Data In Logistics Use Cases Big data is revolutionizing many fields of business, and logistics analytics is no exception. The complex and ever-evolving nature of logistics makes it an essential use case for big data applications. Did you know?
In addition to using native managed AWS services that BMS didn’t need to worry about upgrading, BMS was looking to offer an ETL service to non-technical business users that could visually compose datatransformation workflows and seamlessly run them on the AWS Glue Apache Spark-based serverless data integration engine.
In this data-driven world, building a team of data analysts can be a challenge. Implementing datavisualization and analytics dashboards can be the beginning of the datatransformation journey.
In 2024, datavisualization companies play a pivotal role in transforming complex data into captivating narratives. This blog provides an insightful exploration of the leading entities shaping the datavisualization landscape.
Under the Transparency in Coverage (TCR) rule , hospitals and payors to publish their pricing data in a machine-readable format. The data in the machine-readable files can provide valuable insights to understand the true cost of healthcare services and compare prices and quality across hospitals.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. Together, these capabilities enable terminal operators to enhance efficiency and competitiveness in an industry that is increasingly datadriven.
Data lineage is the journey data takes from its creation through its transformations over time. Tracing the source of data is an arduous task. With all these diverse data sources, and if systems are integrated, it is difficult to understand the complicated data web they form much less get a simple visual flow.
Data integration is the foundation of robust data analytics. It encompasses the discovery, preparation, and composition of data from diverse sources. In the modern data landscape, accessing, integrating, and transformingdata from diverse sources is a vital process for data-driven decision-making.
OpenSearch also includes capabilities to ingest and analyze data. API-driven Interactions : All interactions in OpenSearch are API-driven, eliminating the need for manual file changes or Zookeeper configurations. As part of the migration, reconsider your data model. You then set a replica count using number_of_replicas.
Organizations with legacy, on-premises, near-real-time analytics solutions typically rely on self-managed relational databases as their data store for analytics workloads. Near-real-time streaming analytics captures the value of operational data and metrics to provide new insights to create business opportunities.
The Ten Standard Tools To Develop Data Pipelines In Microsoft Azure. While working in Azure with our customers, we have noticed several standard Azure tools people use to develop data pipelines and ETL or ELT processes. We counted ten ‘standard’ ways to transform and set up batch data pipelines in Microsoft Azure.
Part 2: Introducing Data Journeys. Observability is a methodology for providing visibility of every journey that data takes from source to customer value across every tool, environment, data store, team, and customer so that problems are detected and addressed immediately.
In today’s data-driven world, seamless integration and transformation of data across diverse sources into actionable insights is paramount. With AWS Glue, you can discover and connect to hundreds of diverse data sources and manage your data in a centralized data catalog.
We all know that data is becoming more and more essential for businesses, as the volume of data keeps growing. Dresner reported that nearly 97% of respondents in their Big Data Analytics Market Study consider Big Data to be either important or critical to their businesses. Become data-driven to succeed.
The need to integrate diverse data sources has grown exponentially, but there are several common challenges when integrating and analyzing data from multiple sources, services, and applications. First, you need to create and maintain independent connections to the same data source for different services.
In today’s data-driven world, the ability to seamlessly integrate and utilize diverse data sources is critical for gaining actionable insights and driving innovation. Use case Consider a large ecommerce company that relies heavily on data-driven insights to optimize its operations, marketing strategies, and customer experiences.
If you can’t make sense of your business data, you’re effectively flying blind. Insights hidden in your data are essential for optimizing business operations, finetuning your customer experience, and developing new products — or new lines of business, like predictive maintenance. Azure Data Factory.
As businesses strive to make informed decisions, the amount of data being generated and required for analysis is growing exponentially. This trend is no exception for Dafiti , an ecommerce company that recognizes the importance of using data to drive strategic decision-making processes. We started with 115 dc2.large
It seamlessly consolidates data from various data sources within AWS, including AWS Cost Explorer (and forecasting with Cost Explorer ), AWS Trusted Advisor , and AWS Compute Optimizer. Overview of the BMW Cloud Data Hub At the BMW Group, Cloud Data Hub (CDH) is the central platform for managing company-wide data and data solutions.
Alerts and notifications play a crucial role in maintaining data quality because they facilitate prompt and efficient responses to any data quality issues that may arise within a dataset. It simplifies your experience of monitoring and evaluating the quality of your data.
Different communication infrastructure types such as mesh network and cellular can be used to send load information on a pre-defined schedule or event data in real time to the backend servers residing in the utility UDN (Utility Data Network).
Amazon Redshift , a warehousing service, offers a variety of options for ingesting data from diverse sources into its high-performance, scalable environment. This native feature of Amazon Redshift uses massive parallel processing (MPP) to load objects directly from data sources into Redshift tables.
Building a data-driven business includes choosing the right software and implementing best practices around its use. Every year when budget time rolls around, many organizations find themselves asking the same question: “what are we going to do about our data?” Organizations have too much data. This is a summary article.
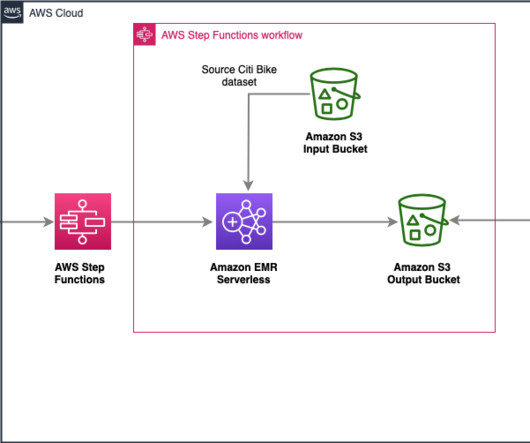
You can run analytics workloads at any scale with automatic scaling that resizes resources in seconds to meet changing data volumes and processing requirements. AWS Step Functions is a serverless orchestration service that enables developers to build visual workflows for applications as a series of event-driven steps.
Data is a key enabler for your business. Many AWS customers have integrated their data across multiple data sources using AWS Glue , a serverless data integration service, in order to make data-driven business decisions. Are there recommended approaches to provisioning components for data integration?
In today’s data-driven landscape, businesses are constantly seeking innovative solutions to harness the power of analytics effectively. Embedded BI tools have emerged as a transformative force, seamlessly integrating analytical capabilities directly into existing software applications.
The energy at the conference was amazing – over 2,000 attendees and 100 vendors gathered to find our inner data heroes. And the Great BI Bake-Off is a perfect example: Four vendors (selected by their Gartner search popularity) took the stage in a live showdown of data viz expertise. Rita Sallam Introduces the Data Prep Rodeo.
In recent years, driven by the commoditization of data storage and processing solutions, the industry has seen a growing number of systematic investment management firms switch to alternative data sources to drive their investment decisions. Each team is the sole owner of its AWS account.
Chances are, you’ve heard of the term “modern data stack” before. In this article, I will explain the modern data stack in detail, list some benefits, and discuss what the future holds. What Is the Modern Data Stack? It is known to have benefits in handling data due to its robustness, speed, and scalability.
You can’t talk about data analytics without talking about data modeling. The reasons for this are simple: Before you can start analyzing data, huge datasets like data lakes must be modeled or transformed to be usable. Building the right data model is an important part of your data strategy.
Data flow lineage is crucial for anyone handling data within organizations. In essence, data flow lineage is indispensable for ensuring transparency, maintaining data quality, achieving compliance, enabling efficient troubleshooting, conducting impact analysis, and enhancing collaboration within organizations.
We just announced the general availability of Cloudera DataFlow Designer , bringing self-service data flow development to all CDP Public Cloud customers. In this blog post we will put these capabilities in context and dive deeper into how the built-in, end-to-end data flow life cycle enables self-service data pipeline development.
Attempting to learn more about the role of big data (here taken to datasets of high volume, velocity, and variety) within business intelligence today, can sometimes create more confusion than it alleviates, as vital terms are used interchangeably instead of distinctly. Big data challenges and solutions.
Collecting and using data to make informed decisions is the new foundation for businesses. The key term here is usable : Anyone can be data rich, and collect vast troves of data. This is where metadata, or the data about data, comes into play. A metadata management framework does the same for your data analysts.
Data product managers are in high demand these days. This makes it more important for aspiring data product managers to stay ahead of the competition. So what sets data product managers apart from the pack? This post will unpack the top 7 traits that successful data product managers have in common. Sounds exciting?
In the era of data, organizations are increasingly using data lakes to store and analyze vast amounts of structured and unstructured data. Data lakes provide a centralized repository for data from various sources, enabling organizations to unlock valuable insights and drive data-driven decision-making.
Many thanks to AWP Pearson for the permission to excerpt “Manual Feature Engineering: Manipulating Data for Fun and Profit” from the book, Machine Learning with Python for Everyone by Mark E. Feature engineering is useful for data scientists when assessing tradeoff decisions regarding the impact of their ML models.
In this post, we share how the AWS Data Lab helped Tricentis to improve their software as a service (SaaS) Tricentis Analytics platform with insights powered by Amazon Redshift. Although Tricentis has amassed such data over a decade, the data remains untapped for valuable insights.
Amazon DataZone now launched authentication supports through the Amazon Athena JDBC driver, allowing data users to seamlessly query their subscribed data lake assets via popular business intelligence (BI) and analytics tools like Tableau, Power BI, Excel, SQL Workbench, DBeaver, and more.
We live in a data-rich, insights-rich, and content-rich world. Data collections are the ones and zeroes that encode the actionable insights (patterns, trends, relationships) that we seek to extract from our data through machine learning and data science. Plus, AI can also help find key insights encoded in data.
Amazon DataZone is a data management service that makes it faster and easier for customers to catalog, discover, share, and govern data stored across AWS, on premises, and from third-party sources. Using Amazon DataZone lets us avoid building and maintaining an in-house platform, allowing our developers to focus on tailored solutions.
Although Jira Cloud provides reporting capability, loading this data into a data lake will facilitate enrichment with other business data, as well as support the use of business intelligence (BI) tools and artificial intelligence (AI) and machine learning (ML) applications.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content