This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The need for streamlined datatransformations As organizations increasingly adopt cloud-based data lakes and warehouses, the demand for efficient datatransformation tools has grown. Using Athena and the dbt adapter, you can transform raw data in Amazon S3 into well-structured tables suitable for analytics.
In fact, by putting a single label like AI on all the steps of a data-driven business process, we have effectively not only blurred the process, but we have also blurred the particular characteristics that make each step separately distinct, uniquely critical, and ultimately dependent on specialized, specific technologies at each step.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. or a later version) database.
Your generated jobs can use a variety of datatransformations, including filters, projections, unions, joins, and aggregations, giving you the flexibility to handle complex data processing requirements. Next, the merged data is filtered to include only a specific geographic region.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that you can use to analyze your data at scale. Building event-driven applications with Amazon EventBridge and Lambda. Scheduling SQL scripts to simplify data load, unload, and refresh of materialized views.
Whether the reporting is being done by an end user, a data science team, or an AI algorithm, the future of your business depends on your ability to use data to drive better quality for your customers at a lower cost. So, when it comes to collecting, storing, and analyzing data, what is the right choice for your enterprise?
Amazon AppFlow is a fully managed integration service that you can use to securely transfer data from software as a service (SaaS) applications, such as Google BigQuery, Salesforce, SAP, HubSpot, and ServiceNow, to Amazon Web Services (AWS) services such as Amazon Simple Storage Service (Amazon S3) and Amazon Redshift, in just a few clicks.
Diagram 1: Overall architecture of the solution, using AWS Step Functions, Amazon Redshift and Amazon S3 The following AWS services were used to shape our new ETL architecture: Amazon Redshift A fully managed, petabyte-scale datawarehouse service in the cloud. The following Diagram 2 shows this workflow.
AWS Database Migration Service (AWS DMS) is used to securely transfer the relevant data to a central Amazon Redshift cluster. The data in the central datawarehouse in Amazon Redshift is then processed for analytical needs and the metadata is shared to the consumers through Amazon DataZone.
Managing large-scale datawarehouse systems has been known to be very administrative, costly, and lead to analytic silos. The good news is that Snowflake, the cloud data platform, lowers costs and administrative overhead. When did you begin a technology partnership with Snowflake and why?
Federated queries allow querying data across Amazon RDS for MySQL and PostgreSQL data sources without the need for extract, transform, and load (ETL) pipelines. If storing operational data in a datawarehouse is a requirement, synchronization of tables between operational data stores and Amazon Redshift tables is supported.
The recent announcement of the Microsoft Intelligent Data Platform makes that more obvious, though analytics is only one part of that new brand. Azure Data Factory. Azure Data Lake Analytics. Datawarehouses are designed for questions you already know you want to ask about your data, again and again.
How dbt Core aids data teams test, validate, and monitor complex datatransformations and conversions Photo by NASA on Unsplash Introduction dbt Core, an open-source framework for developing, testing, and documenting SQL-based datatransformations, has become a must-have tool for modern data teams as the complexity of data pipelines grows.
There are countless examples of big datatransforming many different industries. There is no disputing the fact that the collection and analysis of massive amounts of unstructured data has been a huge breakthrough. How does Data Virtualization complement Data Warehousing and SOA Architectures?
You will load the eventdata from the SFTP site, join it to the venue data stored on Amazon S3, apply transformations, and store the data in Amazon S3. The event and venue files are from the TICKIT dataset. For Node parents , select Rename Venue data and Rename Eventdata.
The extraction of raw data, transforming to a suitable format for business needs, and loading into a datawarehouse. Datatransformation. This process helps to transform raw data into clean data that can be analysed and aggregated. Data analytics and visualisation.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud. With Amazon Redshift, you can analyze all your data to derive holistic insights about your business and your customers. You can also schedule stored procedures to automate data processing on Amazon Redshift. Satesh Sonti is a Sr.
In this post, we delve into a case study for a retail use case, exploring how the Data Build Tool (dbt) was used effectively within an AWS environment to build a high-performing, efficient, and modern data platform. It does this by helping teams handle the T in ETL (extract, transform, and load) processes.
These nodes can implement analytical platforms like data lake houses, datawarehouses, or data marts, all united by producing data products. Education and enablement – Conduct learning interventions to upskill teams on understanding and using the data as a product approach.
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your datawarehouse. These upstream data sources constitute the data producer components.
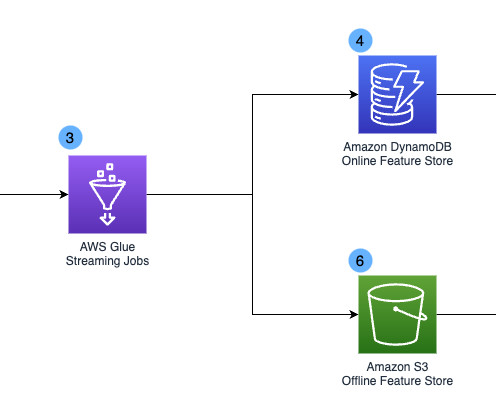
Problem statement In order to keep up with the rapid movement of fraudsters, our decision platform must continuously monitor user events and respond in real-time. However, our legacy datawarehouse-based solution was not equipped for this challenge. Amazon DynamoDB is another data source for our Streaming 2.0
To speed up the self-service analytics and foster innovation based on data, a solution was needed to provide ways to allow any team to create data products on their own in a decentralized manner. To create and manage the data products, smava uses Amazon Redshift , a cloud datawarehouse.
Cloudera users can securely connect Rill to a source of event stream data, such as Cloudera DataFlow , model data into Rill’s cloud-based Druid service, and share live operational dashboards within minutes via Rill’s interactive metrics dashboard or any connected BI solution. Cloudera DataWarehouse). Apache Hive.
Amazon AppFlow , a fully managed data integration service, has been at the forefront of streamlining data transfer between AWS services, software as a service (SaaS) applications, and now Google BigQuery. Architecture Let’s review the architecture to transfer data from Google BigQuery to Amazon S3 using Amazon AppFlow.
DataOps in practice To make the most of DataOps, enterprises must evolve their data management strategies to deal with data at scale and in response to real-world events as they happen, according to Dunning and Friedman. They also note DataOps fits well with microservices architectures.
With quality data at their disposal, organizations can form datawarehouses for the purposes of examining trends and establishing future-facing strategies. Industry-wide, the positive ROI on quality data is well understood. Here, it all comes down to the datatransformation error rate.
As data volumes and use cases scale especially with AI and real-time analytics trust must be an architectural principle, not an afterthought. Comparison of modern data architectures : Architecture Definition Strengths Weaknesses Best used when Datawarehouse Centralized, structured and curated data repository.
In the second blog of the Universal Data Distribution blog series , we explored how Cloudera DataFlow for the Public Cloud (CDF-PC) can help you implement use cases like data lakehouse and datawarehouse ingest, cybersecurity, and log optimization, as well as IoT and streaming data collection.
Datatransformation plays a pivotal role in providing the necessary data insights for businesses in any organization, small and large. To gain these insights, customers often perform ETL (extract, transform, and load) jobs from their source systems and output an enriched dataset.
Performance and scalability of both the data pipeline and API endpoint were key success criteria. The data pipeline needed to have sufficient performance to allow for fast turnaround in the event that data issues needed to be corrected.
With these features, you can now build data pipelines completely in standard SQL that are serverless, more simple to build, and able to operate at scale. Typically, datatransformation processes are used to perform this operation, and a final consistent view is stored in an S3 bucket or folder.
You can do this by updating the CloudFormation stack with a flag that includes the CDC and datatransformation steps. This will enable both the CDC steps and the datatransformation steps for the Jira data. The DataBrew job performs datatransformation and filtering tasks. Choose Update.
Curated foundation models, such as those created by IBM or Microsoft, help enterprises scale and accelerate the use and impact of the most advanced AI capabilities using trusted data. In addition to natural language, models are trained on various modalities, such as code, time-series, tabular, geospatial and IT eventsdata.
When it comes to data modeling, function determines form. Let’s say you want to subject a dataset to some form of anomaly detection; your model might take the form of a singular event stream that can be read by an anomaly detection service. This design philosophy was adapted from our friends at Fishtown Analytics.).
Additionally, the scale is significant because the multi-tenant data sources provide a continuous stream of testing activity, and our users require quick data refreshes as well as historical context for up to a decade due to compliance and regulatory demands. Finally, data integrity is of paramount importance.
Few actors in the modern data stack have inspired the enthusiasm and fervent support as dbt. This datatransformation tool enables data analysts and engineers to transform, test and document data in the cloud datawarehouse. But what does this mean from a practitioner perspective?
This solution decouples the ETL and analytics workloads from our transactional data source Amazon Aurora, and uses Amazon Redshift as the datawarehouse solution to build a data mart. We use Amazon Redshift as the datawarehouse to implement the data mart solution. Under Transforms , choose SQL Query.
His expertise lies in assisting customers with migrating intricate enterprise systems and databases to AWS, constructing enterprise data warehousing and data lake platforms. He is deeply passionate about applying ML/DL and big data techniques to solve real-world problems. Aditya Shah is a Software Development Engineer at AWS.
Kinesis Data Analytics for Apache Flink In our example, we perform the following actions on the streaming data: Connect to an Amazon Kinesis Data Streams data stream. View the stream data. Transform and enrich the data. Manipulate the data with Python.
The key components of a data pipeline are typically: Data Sources : The origin of the data, such as a relational database , datawarehouse, data lake , file, API, or other data store. This can include tasks such as data ingestion, cleansing, filtering, aggregation, or standardization.
This field guide to data mapping will explore how data mapping connects volumes of data for enhanced decision-making. Why Data Mapping is Important Data mapping is a critical element of any data management initiative, such as data integration, data migration, datatransformation, data warehousing, or automation.
Unlocking the full potential of your data is about more than just visualizing it. True datatransformation comes from applying insights to make impactful business decisions. I understand that I can withdraw my consent at any time. Privacy Policy.
The answer depends on your specific business needs and the nature of the data you are working with. Both methods have advantages and disadvantages: Replication involves periodically copying data from a source system to a datawarehouse or reporting database. Empower your team to add new data sources on the fly.
These tools excel at data integration, consolidating information from various financial systems (ERP, CRM, legacy) into a central hub. This eliminates data fragmentation, a major obstacle for AI. Additionally, they provide robust datatransformation capabilities.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content