This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We live in a data-rich, insights-rich, and content-rich world. Data collections are the ones and zeroes that encode the actionable insights (patterns, trends, relationships) that we seek to extract from our data through machinelearning and data science.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis.
The following requirements were essential to decide for adopting a modern data mesh architecture: Domain-oriented ownership and data-as-a-product : EUROGATE aims to: Enable scalable and straightforward data sharing across organizational boundaries. Eliminate centralized bottlenecks and complex data pipelines.
Much has been written about struggles of deploying machinelearning projects to production. As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. However, the concept is quite abstract.
With Amazon AppFlow, you can run data flows at nearly any scale and at the frequency you chooseon a schedule, in response to a business event, or on demand. You can configure datatransformation capabilities such as filtering and validation to generate rich, ready-to-use data as part of the flow itself, without additional steps.
Taking the broadest possible interpretation of data analytics , Azure offers more than a dozen services — and that’s before you include Power BI, with its AI-powered analysis and new datamart option , or governance-oriented approaches such as Microsoft Purview. Azure Data Factory. Azure Data Lake Analytics.
You can use it for big data analytics and machinelearning workloads. Azure Databricks Delta Live Table s: These provide a more straightforward way to build and manage Data Pipelines for the latest, high-quality data in Delta Lake. It provides data prep, management, and enterprise data warehousing tools.
Diagram 1: Overall architecture of the solution, using AWS Step Functions, Amazon Redshift and Amazon S3 The following AWS services were used to shape our new ETL architecture: Amazon Redshift A fully managed, petabyte-scale datawarehouse service in the cloud. The following Diagram 2 shows this workflow.
In the beginning, CDP ran only on AWS with a set of services that supported a handful of use cases and workload types: CDP DataWarehouse: a kubernetes-based service that allows business analysts to deploy datawarehouses with secure, self-service access to enterprise data. New Services.
As data volumes and use cases scale especially with AI and real-time analytics trust must be an architectural principle, not an afterthought. Comparison of modern data architectures : Architecture Definition Strengths Weaknesses Best used when Datawarehouse Centralized, structured and curated data repository.
The framework ensures that your datatransformations comply with rigorous specifications from the moment they are created through every iteration of your pipeline. Great Expectations can enable a wide range of datatransformations and conversion operations.
How dbt Core aids data teams test, validate, and monitor complex datatransformations and conversions Photo by NASA on Unsplash Introduction dbt Core, an open-source framework for developing, testing, and documenting SQL-based datatransformations, has become a must-have tool for modern data teams as the complexity of data pipelines grows.
Where DataOps fits Enterprises today are increasingly injecting machinelearning into a vast array of products and services and DataOps is an approach geared toward supporting the end-to-end needs of machinelearning. The DataOps approach is not limited to machinelearning,” they add.
Given the importance of sharing information among diverse disciplines in the era of digital transformation, this concept is arguably as important as ever. The aim is to normalize, aggregate, and eventually make available to analysts across the organization data that originates in various pockets of the enterprise.
My vision is that I can give the keys to my businesses to manage their data and run their data on their own, as opposed to the Data & Tech team being at the center and helping them out,” says Iyengar, director of Data & Tech at Straumann Group North America. The company’s Findability.ai
Enterprise data is brought into data lakes and datawarehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. Maintaining lists of possible values for the columns requires continuous updates.
We’re excited to announce the general availability of the open source adapters for dbt for all the engines in CDP — Apache Hive , Apache Impala , and Apache Spark, with added support for Apache Livy and Cloudera Data Engineering. The Open Data Lakehouse . Cloudera builds dbt adaptors for all engines in the open data lakehouse.
The general availability covers Iceberg running within some of the key data services in CDP, including Cloudera DataWarehouse ( CDW ), Cloudera Data Engineering ( CDE ), and Cloudera MachineLearning ( CML ). Cloudera Data Engineering (Spark 3) with Airflow enabled. Cloudera MachineLearning .
Federated queries allow querying data across Amazon RDS for MySQL and PostgreSQL data sources without the need for extract, transform, and load (ETL) pipelines. If storing operational data in a datawarehouse is a requirement, synchronization of tables between operational data stores and Amazon Redshift tables is supported.
They can use their own toolsets or rely on provided blueprints to ingest the data from source systems. Once released, consumers use datasets from different providers for analysis, machinelearning (ML) workloads, and visualization. The difference lies in when and where datatransformation takes place.
Large-scale datawarehouse migration to the cloud is a complex and challenging endeavor that many organizations undertake to modernize their data infrastructure, enhance data management capabilities, and unlock new business opportunities. This makes sure the new data platform can meet current and future business goals.
It is comprised of commodity cloud object storage, open data and open table formats, and high-performance open-source query engines. To help organizations scale AI workloads, we recently announced IBM watsonx.data , a data store built on an open data lakehouse architecture and part of the watsonx AI and data platform.
Today’s general availability announcement covers Iceberg running within key data services in the Cloudera Data Platform (CDP) — including Cloudera Data Warehousing ( CDW ), Cloudera Data Engineering ( CDE ), and Cloudera MachineLearning ( CML ). Supercharge your data lakehouse, make it open.
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your datawarehouse. These upstream data sources constitute the data producer components.
Amazon AppFlow , a fully managed data integration service, has been at the forefront of streamlining data transfer between AWS services, software as a service (SaaS) applications, and now Google BigQuery. Architecture Let’s review the architecture to transfer data from Google BigQuery to Amazon S3 using Amazon AppFlow.
Amazon Redshift is a popular cloud datawarehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machinelearning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
These nodes can implement analytical platforms like data lake houses, datawarehouses, or data marts, all united by producing data products. Her special areas of interest are data analytics, machinelearning/AI, and application modernization.
As the volume and complexity of analytics workloads continue to grow, customers are looking for more efficient and cost-effective ways to ingest and analyse data. This enables organizations to streamline data integration and analytics with OpenSearch Service. Select the secret you created, and on the Actions menu, choose Delete.
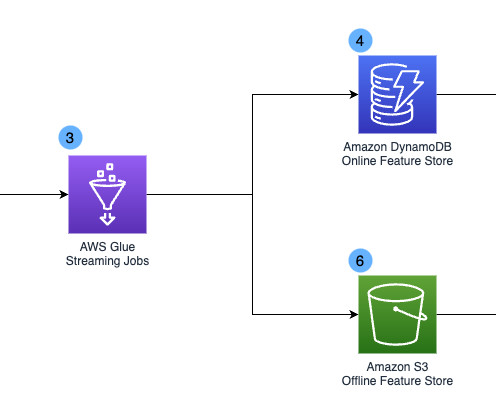
However, our legacy datawarehouse-based solution was not equipped for this challenge. However, with a minimum data freshness of 10 minutes, this architecture inherently didn’t align with the near real-time fraud detection use case. Solution overview The following diagram illustrates the design of the Chime Streaming 2.0
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it straightforward and cost-effective to analyze your data. Amazon Redshift ML is a feature of Amazon Redshift that enables you to build, train, and deploy machinelearning (ML) models directly within the Redshift environment.
Datatransforms businesses. That’s where the data lifecycle comes into play. Managing data and its flow, from the edge to the cloud, is one of the most important tasks in the process of gaining data intelligence. . The firm also worked on creating a solid pipeline from the datawarehouse to the data lake.
In today’s data-driven world, seamless integration and transformation of data across diverse sources into actionable insights is paramount. With AWS Glue, you can discover and connect to hundreds of diverse data sources and manage your data in a centralized data catalog.
In legacy analytical systems such as enterprise datawarehouses, the scalability challenges of a system were primarily associated with computational scalability, i.e., the ability of a data platform to handle larger volumes of data in an agile and cost-efficient way. Introduction.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machinelearning (ML) and new generative AI capabilities powered by foundation models. Automated development: Automates data preparation, model development, feature engineering and hyperparameter optimization using AutoAI.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. An AI governance framework ensures the ethical, responsible and transparent use of AI and machinelearning (ML). It can be used with both on-premise and multi-cloud environments.
The integration of Talend Cloud and Talend Stitch with Amazon Redshift Serverless can help you achieve successful business outcomes without datawarehouse infrastructure management. In this post, we demonstrate how Talend easily integrates with Redshift Serverless to help you accelerate and scale data analytics with trusted data.
Data teams dealing with larger, faster-moving cloud datasets needed more robust tools to perform deeper analyses and set the stage for next-level applications like machinelearning and natural language processing. SkullCandy’s big data journey began by building a datawarehouse to aggregate their transaction data, reviews.
Advanced datatransformation with Custom Code. With our latest release, you can leverage Python code from Jupyter Notebooks to connect to services such as Amazon SageMaker, Amazon Comprehend, and Amazon Translate to transform and augment data inside your ElastiCube models. If so, it’s your lucky day.
They defined it as : “ A data lakehouse is a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of datawarehouses, enabling business intelligence (BI) and machinelearning (ML) on all data. ”.
Although Jira Cloud provides reporting capability, loading this data into a data lake will facilitate enrichment with other business data, as well as support the use of business intelligence (BI) tools and artificial intelligence (AI) and machinelearning (ML) applications. Choose Update.
The API retrieves data at runtime from an Amazon Aurora PostgreSQL-Compatible Edition database for end-user consumption. To populate the database, the Infomedia team developed a data pipeline using Amazon Simple Storage Service (Amazon S3) for data storage, AWS Glue for datatransformations, and Apache Hudi for CDC and record-level updates.
Overview of AWS Glue AWS Glue is a serverless data integration service that makes it easier to discover, prepare, and combine data for analytics, machinelearning (ML), and application development. Cost efficiency : Building and maintaining custom connectors can be expensive.
The datawarehouse and analytical data stores moved to the cloud and disaggregated into the data mesh. Today, the brightest minds in our industry are targeting the massive proliferation of data volumes and the accompanying but hard-to-find value locked within all that data. Architectures became fabrics.
Looking at the diagram, we see that Business Intelligence (BI) is a collection of analytical methods applied to big data to surface actionable intelligence by identifying patterns in voluminous data. As we move from right to left in the diagram, from big data to BI, we notice that unstructured datatransforms into structured data.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content