This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis.
This is both frustrating for companies that would prefer making ML an ordinary, fuss-free value-generating function like software engineering, as well as exciting for vendors who see the opportunity to create buzz around a new category of enterprise software. All ML projects are software projects.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that you can use to analyze your data at scale. He brings extensive experience on Software Development, Architecture and Analytics from industries like finance, telecom, retail and healthcare.
Whether the reporting is being done by an end user, a data science team, or an AI algorithm, the future of your business depends on your ability to use data to drive better quality for your customers at a lower cost. So, when it comes to collecting, storing, and analyzing data, what is the right choice for your enterprise?
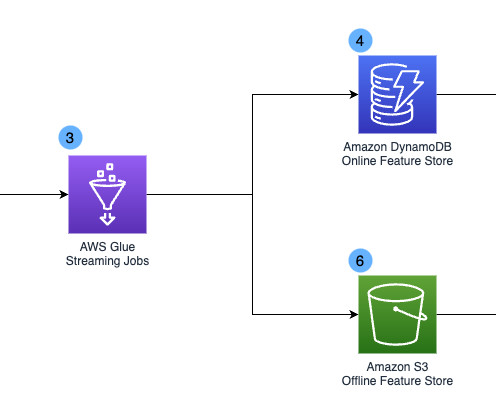
Your generated jobs can use a variety of datatransformations, including filters, projections, unions, joins, and aggregations, giving you the flexibility to handle complex data processing requirements. To learn more, refer to Amazon Q data integration in AWS Glue.
In this post, we show you how to establish the data ingestion pipeline between Google Analytics 4, Google Sheets, and an Amazon Redshift Serverless workgroup. With Amazon AppFlow, you can run data flows at nearly any scale and at the frequency you chooseon a schedule, in response to a business event, or on demand.
Diagram 1: Overall architecture of the solution, using AWS Step Functions, Amazon Redshift and Amazon S3 The following AWS services were used to shape our new ETL architecture: Amazon Redshift A fully managed, petabyte-scale datawarehouse service in the cloud. Our infrastructure was defined as code using the AWS CDK.
With quality data at their disposal, organizations can form datawarehouses for the purposes of examining trends and establishing future-facing strategies. Industry-wide, the positive ROI on quality data is well understood. Business/Data Analyst: The business analyst is all about the “meat and potatoes” of the business.
Amazon Q Developer can also help you connect to third-party, software as a service (SaaS), and custom sources. Amazon Q Developer can now generate complex data integration jobs with multiple sources, destinations, and datatransformations. He is responsible for building software artifacts to help customers.
How dbt Core aids data teams test, validate, and monitor complex datatransformations and conversions Photo by NASA on Unsplash Introduction dbt Core, an open-source framework for developing, testing, and documenting SQL-based datatransformations, has become a must-have tool for modern data teams as the complexity of data pipelines grows.
dbt is an open source, SQL-first templating engine that allows you to write repeatable and extensible datatransforms in Python and SQL. dbt is predominantly used by datawarehouses (such as Amazon Redshift ) customers who are looking to keep their datatransform logic separate from storage and engine.
According to Gartner, DataOps also aims “to deliver value faster by creating predictable delivery and change management of data, data models, and related artifacts.” DataKitchen, which specializes in DataOps observability and automation software, maintains that DataOps is not simply “DevOps for data.”
There are countless examples of big datatransforming many different industries. There is no disputing the fact that the collection and analysis of massive amounts of unstructured data has been a huge breakthrough. Data virtualization is becoming more popular due to its huge benefits. Maximizing customer engagement.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud. With Amazon Redshift, you can analyze all your data to derive holistic insights about your business and your customers. You can also schedule stored procedures to automate data processing on Amazon Redshift. Satesh Sonti is a Sr.
To speed up the self-service analytics and foster innovation based on data, a solution was needed to provide ways to allow any team to create data products on their own in a decentralized manner. To create and manage the data products, smava uses Amazon Redshift , a cloud datawarehouse.
Dafiti’s data infrastructure relies heavily on ETL and ELT processes, with approximately 2,500 unique processes run daily. Amazon Redshift at Dafiti Amazon Redshift is a fully managed datawarehouse service, and was adopted by Dafiti in 2017. About the Authors Valdiney Gomes is Data Engineering Coordinator at Dafiti.
dbt allows data teams to produce trusted data sets for reporting, ML modeling, and operational workflows using SQL, with a simple workflow that follows software engineering best practices like modularity, portability, and continuous integration/continuous development (CI/CD). The Open Data Lakehouse . Introduction.
It is comprised of commodity cloud object storage, open data and open table formats, and high-performance open-source query engines. To help organizations scale AI workloads, we recently announced IBM watsonx.data , a data store built on an open data lakehouse architecture and part of the watsonx AI and data platform.
Data operations (or data production) is a series of pipeline procedures that take raw data, progress through a series of processing and transformation steps, and output finished products in the form of dashboards, predictions, datawarehouses or whatever the business requires. Their product is the data.
Amazon AppFlow , a fully managed data integration service, has been at the forefront of streamlining data transfer between AWS services, software as a service (SaaS) applications, and now Google BigQuery. Architecture Let’s review the architecture to transfer data from Google BigQuery to Amazon S3 using Amazon AppFlow.
In response, Lenovo launched a new line of entry-level gaming laptops and desktops it now brands as Lenovo LOQ that caters to a new gamer’s first foray into gaming, says Girish Hoogar, global head of engineering for Lenovo’s cloud and software business in its Intelligent Devices Group.
As data volumes and use cases scale especially with AI and real-time analytics trust must be an architectural principle, not an afterthought. Comparison of modern data architectures : Architecture Definition Strengths Weaknesses Best used when Datawarehouse Centralized, structured and curated data repository.
This is a guest post by Khandu Shinde, Staff Software Engineer and Edward Paget, Senior Software Engineering at Chime Financial. However, our legacy datawarehouse-based solution was not equipped for this challenge. He enjoys being at the intersection of big data and programming language theory.
Iceberg is a 100% open-table format, developed through the Apache Software Foundation , which helps users avoid vendor lock-in and implement an open lakehouse. . These connections empower analysts and data scientists to easily collaborate on the same data, with their choice of tools and engines. Cloudera Machine Learning .
We are excited to announce the general availability of Apache Iceberg in Cloudera Data Platform (CDP). Iceberg is a 100% open table format, developed through the Apache Software Foundation , and helps users avoid vendor lock-in. Supercharge your data lakehouse, make it open. Read why the future of data lakehouses is open.
It has been well published since the State of DevOps 2019 DORA Metrics were published that with DevOps, companies can deploy software 208 times more often and 106 times faster, recover from incidents 2,604 times faster, and release 7 times fewer defects. For users that require a unified view of software quality, this is unacceptable.
The modern data stack is a combination of various software tools used to collect, process, and store data on a well-integrated cloud-based data platform. It is known to have benefits in handling data due to its robustness, speed, and scalability. Extract, load, Transform (ELT) tools. Better Data Culture.
Having run a data engineering program at Insight for several years, we’ve identified three broad categories of data engineers: Software engineers who focus on building data pipelines. In some cases, they work to deploy data science models into production with an eye towards optimization, scalability and maintainability.
As we review datatransformation and modernization strategies with our clients, we find many are investigating Snowflake as a datawarehouse solution due to its ease of use, speed, and increased flexibility over a traditional datawarehouse offering.
In the world of software engineering and development, organizations use project management tools like Atlassian Jira Cloud. This post shows you how to use Amazon AppFlow and AWS Glue to create a fully automated data ingestion pipeline that will synchronize your Jira data into your data lake. Choose Update.
The integration of Talend Cloud and Talend Stitch with Amazon Redshift Serverless can help you achieve successful business outcomes without datawarehouse infrastructure management. In this post, we demonstrate how Talend easily integrates with Redshift Serverless to help you accelerate and scale data analytics with trusted data.
Data may be stored in its raw original form or optimized into a different format suitable for consumption by specialized engines. Data could be persisted in open data formats, democratizing its consumption, as well as replicated automatically which helped you sustain high availability.
How to scale AL and ML with built-in governance A fit-for-purpose data store built on an open lakehouse architecture allows you to scale AI and ML while providing built-in governance tools. A data store lets a business connect existing data with new data and discover new insights with real-time analytics and business intelligence.
Efficiency : Datatransformation tasks that previously took weeks or months can now be accomplished within minutes, optimizing efficiency. Anshul Sharma is a Software Development Engineer in AWS Glue Team. Cost efficiency : Building and maintaining custom connectors can be expensive.
Here at Sisense, we think about this flow in five linear layers: Raw This is our data in its raw form within a datawarehouse. We follow an ELT ( E xtract, L oad, T ransform) practice, as opposed to ETL, in which we opt to transform the data in the warehouse in the stages that follow.
Advanced datatransformation with Custom Code. With our latest release, you can leverage Python code from Jupyter Notebooks to connect to services such as Amazon SageMaker, Amazon Comprehend, and Amazon Translate to transform and augment data inside your ElastiCube models. If so, it’s your lucky day.
Apache Hive is a distributed, fault-tolerant datawarehouse system that enables analytics at a massive scale. Spark SQL is an Apache Spark module for structured data processing. Melody Yang is a Senior Big Data Solutions Architect for Amazon EMR at AWS. or later installed.
IBM software products are embedding watsonx capabilities across digital labor, IT automation, security, sustainability, and application modernization to help unlock new levels of business value for clients. It is supported by querying, governance, and open data formats to access and share data across the hybrid cloud.
Data access is enabled through the smart implementation of cloud, which in turn allows for faster and more informed decision-making. We had our cloud environment, enterprise services [and Software-as-a-Service] infrastructure all set up so we could get services out centrally…across the whole U.S.,”
Looking at the diagram, we see that Business Intelligence (BI) is a collection of analytical methods applied to big data to surface actionable intelligence by identifying patterns in voluminous data. As we move from right to left in the diagram, from big data to BI, we notice that unstructured datatransforms into structured data.
It seamlessly integrates with Amazon RDS for Db2, watsonx.data SaaS, and other IBM and AWS services like IBM data fabric, Amazon S3, Amazon EMR and AWS Glue. This allows you to scale all analytics and AI workloads across the enterprise with trusted data.
For many organizations, a centralized data platform will fall short as it gives data teams much less autonomy over managing increasingly diverse and voluminous datasets. A centralized data engineering team focuses on building a governed self-serviced infrastructure, while domain teams use the services to build full-stack data products.
He is deeply passionate about applying ML/DL and big data techniques to solve real-world problems. Aditya Shah is a Software Development Engineer at AWS. Melody Yang is a Senior Big Data Solution Architect for Amazon EMR at AWS. Her areas of interests are open-source frameworks and automation, data engineering and DataOps.
In today’s data-driven landscape, businesses are constantly seeking innovative solutions to harness the power of analytics effectively. Embedded BI tools have emerged as a transformative force, seamlessly integrating analytical capabilities directly into existing software applications.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content