This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
But even though technologies like Building Information Modelling (BIM) have finally introduced symbolic representation, in many ways, AECO still clings to outdated, analog practices and documents. Here, one of the challenges involves digitizing the national specifics of regulatory documents and building codes in multiple languages.
The need for streamlined datatransformations As organizations increasingly adopt cloud-based data lakes and warehouses, the demand for efficient datatransformation tools has grown. This makes sure your data models are well-documented, versioned, and straightforward to manage within a collaborative environment.
This middleware consists of custom code that runs data flows to stitch datatransformations, search queries, and AI enrichments in varying combinations tailored to use cases, datasets, and requirements. Ingest flows are created to enrich data as its added to an index. An index constructed from the processed documents.
Together with price-performance, Amazon Redshift offers capabilities such as serverless architecture, machine learning integration within your data warehouse and secure data sharing across the organization. dbt Cloud is a hosted service that helps data teams productionize dbt deployments.
Data collections are the ones and zeroes that encode the actionable insights (patterns, trends, relationships) that we seek to extract from our data through machine learning and data science. Datasphere is a data discovery tool with essential functionalities: recommendations, data marketplace, and business content (i.e.,
Get started with our technical documentation. Joel Farvault is Principal Specialist SA Analytics for AWS with 25 years’ experience working on enterprise architecture, data governance and analytics, mainly in the financial services industry.
How dbt Core aids data teams test, validate, and monitor complex datatransformations and conversions Photo by NASA on Unsplash Introduction dbt Core, an open-source framework for developing, testing, and documenting SQL-based datatransformations, has become a must-have tool for modern data teams as the complexity of data pipelines grows.
Great Expectations can be integrated directly into existing data pipelines to define, test, and document expectations about the appearance of transformed or converted data. Data quality rules are codified into structured Expectation Suites by Great Expectations instead of relying on ad-hoc scripts or manual checks.
Selecting the strategies and tools for validating datatransformations and data conversions in your data pipelines. Introduction Datatransformations and data conversions are crucial to ensure that raw data is organized, processed, and ready for useful analysis.
Common challenges and practical mitigation strategies for reliable datatransformations. Photo by Mika Baumeister on Unsplash Introduction Datatransformations are important processes in data engineering, enabling organizations to structure, enrich, and integrate data for analytics , reporting, and operational decision-making.
For example, automatically importing mappings from developers’ Excel sheets, flat files, Access and ETL tools into a comprehensive mappings inventory, complete with auto generated and meaningful documentation of the mappings, is a powerful way to support overall data governance. Data quality is crucial to every organization.
With CloudSearch, you can search large collections of data such as webpages, document files, forum posts, or product information. You send your documents to OpenSearch Serverless, which indexes them for search using the OpenSearch REST API. With OpenSearch Serverless , you get improved, out-of-the-box, hands-free operation.
Adding datatransformation details to metadata can be challenging because of the dispersed nature of this information across data processing pipelines, making it difficult to extract and incorporate into table-level metadata. The AWS Glue crawler will then populate the additional metadata in AWS Glue Data Catalog.
Data processes that depended upon the previously defective data will likely need to be re-initiated, especially if their functioning was at risk or compromised by the defected data. These processes could include reports, campaigns, or financial documentation. Accuracy should be measured through source documentation (i.e.,
These acquisitions usher in a new era of “ self-service ” by automating complex operations so customers can focus on building great data-driven apps instead of managing infrastructure. Datacoral powers fast and easy datatransformations for any type of data via a robust multi-tenant SaaS architecture that runs in AWS.
Building a Data Culture Within a Finance Department. Our finance users tell us that their first exposure to the Alation Data Catalog often comes soon after the launch of organization-wide datatransformation efforts. After all, finance is one of the greatest consumers of data within a business.
Get started with our technical documentation. Joel Farvault is Principal Specialist SA Analytics for AWS with 25 years’ experience working on enterprise architecture, data governance and analytics, mainly in the financial services industry.
Build data validation rules directly into ingestion layers so that insufficient data is stopped at the gate and not detected after damage is done. Use lineage tooling to trace data from source to report. Understanding how datatransforms and where it breaks is crucial for audibility and root-cause resolution.
dbt is an open source, SQL-first templating engine that allows you to write repeatable and extensible datatransforms in Python and SQL. dbt is predominantly used by data warehouses (such as Amazon Redshift ) customers who are looking to keep their datatransform logic separate from storage and engine.
In this post, we delve into a case study for a retail use case, exploring how the Data Build Tool (dbt) was used effectively within an AWS environment to build a high-performing, efficient, and modern data platform. It does this by helping teams handle the T in ETL (extract, transform, and load) processes.
Business terms and data policies should be implemented through standardized and documented business rules. Compliance with these business rules can be tracked through data lineage, incorporating auditability and validation controls across datatransformations and pipelines to generate alerts when there are non-compliant data instances.
We’re excited to announce the general availability of the open source adapters for dbt for all the engines in CDP — Apache Hive , Apache Impala , and Apache Spark, with added support for Apache Livy and Cloudera Data Engineering. The Open Data Lakehouse . Cloudera builds dbt adaptors for all engines in the open data lakehouse.
Instead of invoking the open-source scikit-learn or Keras calls to build models, your team now goes from Pandas datatransforms straight to … the API calls for AWS AutoPilot or GCP Vertex AI. It does not exist in the code. AutoML drives this point home. And it’s available to everyone. What if we go the other way?
OpenSearch is an open source, distributed search engine suitable for a wide array of use-cases such as ecommerce search, enterprise search (content management search, document search, knowledge management search, and so on), site search, application search, and semantic search. OpenSearch also includes capabilities to ingest and analyze data.
The techniques for managing organisational data in a standardised approach that minimises inefficiency. Extraction, Transform, Load (ETL). The extraction of raw data, transforming to a suitable format for business needs, and loading into a data warehouse. Datatransformation.
Given the importance of sharing information among diverse disciplines in the era of digital transformation, this concept is arguably as important as ever. The aim is to normalize, aggregate, and eventually make available to analysts across the organization data that originates in various pockets of the enterprise.
With Amazon AppFlow, you can run data flows at nearly any scale and at the frequency you chooseon a schedule, in response to a business event, or on demand. You can configure datatransformation capabilities such as filtering and validation to generate rich, ready-to-use data as part of the flow itself, without additional steps.
In recent years, driven by the commoditization of data storage and processing solutions, the industry has seen a growing number of systematic investment management firms switch to alternative data sources to drive their investment decisions. The bulk of our data scientists are heavy users of Jupyter Notebook. or later.
Amazon Q Developer can now generate complex data integration jobs with multiple sources, destinations, and datatransformations. Generated jobs can use a variety of datatransformations, including filter, project, union, join, and custom user-supplied SQL.
This integration empowers developers and data scientists alike with advanced capabilities for code completion, generation, and troubleshooting. Whether you’re tackling datatransformation challenges or refining intricate machine learning models, our Copilot is designed to be your reliable partner in innovation.
SUPER data type columns in Amazon Redshift contain semi-structured data like JSON documents. Previously, data masking in Amazon Redshift only worked with regular table columns, but now you can apply masking policies specifically to elements within SUPER columns. All columns should masked for them.
Take Grammarly as an example: This popular program checks the grammar, tone, and style of documents. Getting this AI properly trained required a huge learning dataset with countless documents that were tagged according to specific criteria. Accurately prepared data is the base of AI. What will it take to build your MVP?
Today’s healthcare providers use a wide variety of applications and data across a broad ecosystem of partners to manage their daily workflows. Integrating these applications and data is critical to their success, allowing them to deliver patient care efficiently and effectively.
ELT tools such as IBM® DataStage® facilitate fast and secure transformations through parallel processing engines. In 2023, the average enterprise receives hundreds of disparate data streams, making efficient and accurate datatransformations crucial for traditional and new AI model development.
However, you might face significant challenges when planning for a large-scale data warehouse migration. As part of the success criteria for operational service levels, you need to document the expected service levels for the new Amazon Redshift data warehouse environment. Platform architects define a well-architected platform.
Increased data variety, balancing structured, semi-structured and unstructured data, as well as data originating from a widening array of external sources. Reducing the IT bottleneck that creates barriers to data accessibility. Hybrid on-premises/cloud environments that complicate data integration and preparation.
By leveraging Hive to apply Ranger FGAC, Spark obtains secure access to the data in a protected staging area. Since Spark has direct access to the staged data, any Spark APIs can be used, from complex datatransformations to data science and machine learning. . so stay tuned! .
Few actors in the modern data stack have inspired the enthusiasm and fervent support as dbt. This datatransformation tool enables data analysts and engineers to transform, test and documentdata in the cloud data warehouse. But what does this mean from a practitioner perspective?
Solution overview The following diagram illustrates the solution architecture: The solution uses AWS Glue as an ETL engine to extract data from the source Amazon RDS database. Built-in datatransformations then scrub columns containing PII using pre-defined masking functions. PII detection and scrubbing.
With Amazon AppFlow, you can run data flows at nearly any scale at the frequency you choose—on a schedule, in response to a business event, or on demand. You can configure datatransformation capabilities such as filtering and validation to generate rich, ready-to-use data as part of the flow itself, without additional steps.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. A data store lets a business connect existing data with new data and discover new insights with real-time analytics and business intelligence. Track models and drive transparent processes.
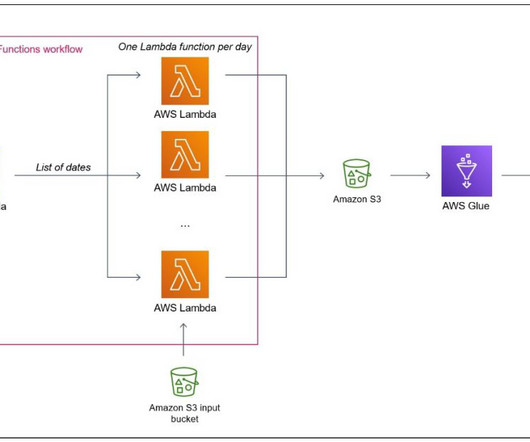
It has not been specifically designed for heavy datatransformation tasks. Additionally, check out the official documentation of AWS Glue , Lambda , and Step Functions. You also use AWS Glue to consolidate the files produced by the parallel tasks. Note that Lambda is a general purpose serverless engine.
Detailed Data and Model Lineage Tracking*: Ensures comprehensive tracking and documentation of datatransformations and model lifecycle events, enhancing reproducibility and auditability.
We will create a glue studio job, add events and venue data from the SFTP server, carry out datatransformations and load transformeddata to s3. For further details on the SFTP connector, see the SFTP Connector for Glue documentation. Select Visual ETL in the central pane.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content