This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This middleware consists of custom code that runs data flows to stitch datatransformations, search queries, and AI enrichments in varying combinations tailored to use cases, datasets, and requirements. Ingest flows are created to enrich data as its added to an index. An index constructed from the processed documents.
Data collections are the ones and zeroes that encode the actionable insights (patterns, trends, relationships) that we seek to extract from our data through machinelearning and data science. incorporates the business context of the data and data products that are being recommended and delivered).
Within seconds of transactional data being written into Amazon Aurora (a fully managed modern relational database service offering performance and high availability at scale), the data is seamlessly made available in Amazon Redshift for analytics and machinelearning. If this number is 0, then the test is successful.
Think about what the model results tell you: “Maybe a random forest isn’t the best tool to split this data, but XLNet is.” ” If none of your models performed well, that tells you that your dataset–your choice of raw data, feature selection, and feature engineering–is not amenable to machinelearning.
In the fast-evolving landscape of data science and machinelearning, efficiency is not just desirable—it’s essential. Imagine a world where every data practitioner, from seasoned data scientists to budding developers, has an intelligent assistant at their fingertips.
With CloudSearch, you can search large collections of data such as webpages, document files, forum posts, or product information. You send your documents to OpenSearch Serverless, which indexes them for search using the OpenSearch REST API. With OpenSearch Serverless , you get improved, out-of-the-box, hands-free operation.
How dbt Core aids data teams test, validate, and monitor complex datatransformations and conversions Photo by NASA on Unsplash Introduction dbt Core, an open-source framework for developing, testing, and documenting SQL-based datatransformations, has become a must-have tool for modern data teams as the complexity of data pipelines grows.
Great Expectations can be integrated directly into existing data pipelines to define, test, and document expectations about the appearance of transformed or converted data. Data quality rules are codified into structured Expectation Suites by Great Expectations instead of relying on ad-hoc scripts or manual checks.
Amazon Redshift is used to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes. Amazon EMR provides a big data environment for data processing, interactive analysis, and machinelearning using open source frameworks such as Apache Spark, Apache Hive, and Presto.
Build data validation rules directly into ingestion layers so that insufficient data is stopped at the gate and not detected after damage is done. Use lineage tooling to trace data from source to report. Understanding how datatransforms and where it breaks is crucial for audibility and root-cause resolution.
We’re excited to announce the general availability of the open source adapters for dbt for all the engines in CDP — Apache Hive , Apache Impala , and Apache Spark, with added support for Apache Livy and Cloudera Data Engineering. The Open Data Lakehouse . Cloudera builds dbt adaptors for all engines in the open data lakehouse.
AI and machinelearning (ML) are not just catchy buzzwords; they’re vital to the future of our planet and your business. Doing it right can mean the difference between thriving in the new world of data and disappearing from it. Take Grammarly as an example: This popular program checks the grammar, tone, and style of documents.
With Amazon AppFlow, you can run data flows at nearly any scale and at the frequency you chooseon a schedule, in response to a business event, or on demand. You can configure datatransformation capabilities such as filtering and validation to generate rich, ready-to-use data as part of the flow itself, without additional steps.
Given the importance of sharing information among diverse disciplines in the era of digital transformation, this concept is arguably as important as ever. The aim is to normalize, aggregate, and eventually make available to analysts across the organization data that originates in various pockets of the enterprise.
By leveraging Hive to apply Ranger FGAC, Spark obtains secure access to the data in a protected staging area. Since Spark has direct access to the staged data, any Spark APIs can be used, from complex datatransformations to data science and machinelearning. . so stay tuned! .
With Amazon AppFlow, you can run data flows at nearly any scale at the frequency you choose—on a schedule, in response to a business event, or on demand. You can configure datatransformation capabilities such as filtering and validation to generate rich, ready-to-use data as part of the flow itself, without additional steps.
However, when a data producer shares data products on a data mesh self-serve web portal, it’s neither intuitive nor easy for a data consumer to know which data products they can join to create new insights. This is especially true in a large enterprise with thousands of data products.
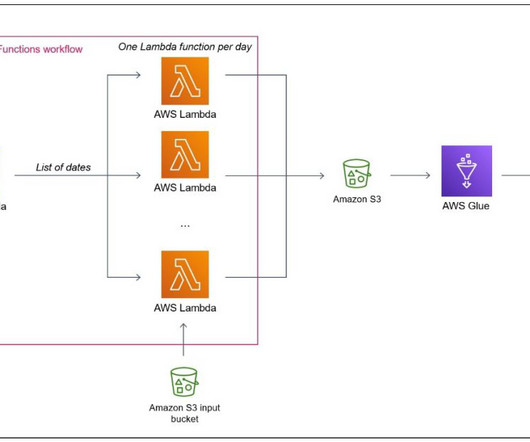
It has not been specifically designed for heavy datatransformation tasks. Step Functions helps developers use AWS services to build distributed applications, automate processes, orchestrate microservices, and create data and machinelearning (ML) pipelines. Note that Lambda is a general purpose serverless engine.
There are three technological advances driving this data consumption and, in turn, the ability for employees to leverage this data to deliver business value 1) exploding data production 2) scalable big data computation, and 3) the accessibility of advanced analytics, machinelearning (ML) and artificial intelligence (AI).
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. An AI governance framework ensures the ethical, responsible and transparent use of AI and machinelearning (ML). Capture and document model metadata for report generation.
By using AWS Glue to integrate data from Snowflake, Amazon S3, and SaaS applications, organizations can unlock new opportunities in generative artificial intelligence (AI) , machinelearning (ML) , business intelligence (BI) , and self-service analytics or feed data to underlying applications.
Detailed Data and Model Lineage Tracking*: Ensures comprehensive tracking and documentation of datatransformations and model lifecycle events, enhancing reproducibility and auditability. Developers are provided open inference protocol APIs for traditional ML models and with an OpenAI compatible API for LLMs.
In today’s data-driven world, seamless integration and transformation of data across diverse sources into actionable insights is paramount. With AWS Glue, you can discover and connect to hundreds of diverse data sources and manage your data in a centralized data catalog.
Migrating to Amazon Redshift offers organizations the potential for improved price-performance, enhanced data processing, faster query response times, and better integration with technologies such as machinelearning (ML) and artificial intelligence (AI). Platform architects define a well-architected platform.
We all want to solve the interesting data challenges, build analytics, generate graph embeddings and train smart machinelearning models over our knowledge graph data. This leads to lots of small data fetches to/from GraphDB over the network. Custom code also tends to over-fetch data that is not required.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machinelearning (ML) and new generative AI capabilities powered by foundation models. While they require task-specific labeled data for fine tuning, they also offer clients the best cost performance trade-off for non-generative use cases.
Overview of AWS Glue AWS Glue is a serverless data integration service that makes it easier to discover, prepare, and combine data for analytics, machinelearning (ML), and application development. Follow the documentation to clean up the Google resources.
A metadata management framework combines organizational structure and a set of tools to create a data asset taxonomy. Document type: describes creation, storage, and use during business processes. Scale effectively: Leverage taxonomies to ensure consistent modeling outcomes when introducing new data sets or changing business demands.
This can be done using the initiatePrint action: embeddedDashboard.initiatePrint(); The following code sample shows a loading animation, SDK code status, and dashboard interaction monitoring, along with initiating dashboard print from the application: Embedding demo $(document).ready(function()
With Snowflake’s newest feature release, Snowpark , developers can now quickly build and scale data-driven pipelines and applications in their programming language of choice, taking full advantage of Snowflake’s highly performant and scalable processing engine that accelerates the traditional data engineering and machinelearning life cycles.
Ronobijay: Sure, I think it would, you know, what used to be anathema till a few months back, you know, datatransformation is real now, right? We would have to visit a branch possibly, you know, multiple locations, submit multiple documents. So earlier customers would spend a week or two, trying to open a bank account.
Redshift Serverless automatically provisions and intelligently scales data warehouse capacity to deliver fast performance for even the most demanding and unpredictable workloads, and you pay only for what you use. Solution overview The integration of Talend with Amazon Redshift adds new features and capabilities.
As data inconsistencies grew, so did skepticism about the accuracy of the data. Decision-makers hesitated to rely on data-driven insights, fearing the consequences of potential errors. Accurate data lineage rebuilt trust among decision-makers. Ensuring compliance with healthcare regulations became a daunting task.
Many thanks to AWP Pearson for the permission to excerpt “Manual Feature Engineering: Manipulating Data for Fun and Profit” from the book, MachineLearning with Python for Everyone by Mark E. Missing values can be filled in based on expert knowledge, heuristics, or by some machinelearning techniques.
A well-governed data landscape enables data users in the public sector to better understand the driving forces and needs to support public policy – and measure impact once a change is made. Efficient Access To Data. Citizens, companies, and government employees need access to data and documents.
This concludes creating data sources on the AWS Glue job canvas. Next, we add transformations by combining data from these different tables. Transform the data Complete the following steps to add datatransformations: On the AWS Glue job canvas, choose the plus sign. Choose Run to run the job.
This field guide to data mapping will explore how data mapping connects volumes of data for enhanced decision-making. Why Data Mapping is Important Data mapping is a critical element of any data management initiative, such as data integration, data migration, datatransformation, data warehousing, or automation.
Modern Data Sources Painlessly connect with modern data such as streaming, search, big data, NoSQL, cloud, document-based sources. Quickly link all your data from Amazon Redshift, MongoDB, Hadoop, Snowflake, Apache Solr, Elasticsearch, Impala, and more. addresses). Read carefully. Instead, software can be used.
Enterprise organizations collect massive volumes of unstructured data, such as images, handwritten text, documents, and more. They also still capture much of this data through manual processes. The way to leverage this for business insight is to digitize that data.
The company, which employs 100,000 globally, relies primarily on Azure for cloud and data services, has deployed a variety of ERP packages, and maintains a mature Snowflake data lakehouse.
Solution overview Setting up observability signal data for analysis involves many steps, including instrumenting application code, creating complex queries, creating visualizations and dashboards, configuring appropriate alerts, and often machinelearning-based anomaly detectors.
Data engineers and analysts often need to automate their data processing workflows and queries to maintain up-to-date data pipelines and reports. Amazon SageMaker Unified Studio provides a unified environment for data, analytics, machinelearning (ML), and AI workloads.
Streaming pipelines used Spark Streaming to ingest real-time data from Kafka, writing raw datasets to an Amazon Simple Storage Service (Amazon S3) data lake while simultaneously loading them into BigQuery and Google Cloud Storage to build logical data layers.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content