This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The need for streamlined datatransformations As organizations increasingly adopt cloud-based data lakes and warehouses, the demand for efficient datatransformation tools has grown. This approach helps in managing storage costs while maintaining the flexibility to analyze historical trends when needed.
Together with price-performance, Amazon Redshift offers capabilities such as serverless architecture, machine learning integration within your data warehouse and secure data sharing across the organization. dbt Cloud is a hosted service that helps data teams productionize dbt deployments. or a later version) database.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. With a unified catalog, enhanced analytics capabilities, and efficient datatransformation processes, were laying the groundwork for future growth.
Maintaining reusable database sessions to help optimize the use of database connections, preventing the API server from exhausting the available connections and improving overall system scalability. Building event-driven applications with Amazon EventBridge and Lambda.
There are countless examples of big datatransforming many different industries. There is no disputing the fact that the collection and analysis of massive amounts of unstructured data has been a huge breakthrough. How is Data Virtualization performance optimized? In forecasting future events.
Accurately predicting demand for products allows businesses to optimize inventory levels, minimize stockouts, and reduce holding costs. Solution overview In today’s highly competitive business landscape, it’s essential for retailers to optimize their inventory management processes to maximize profitability and improve customer satisfaction.
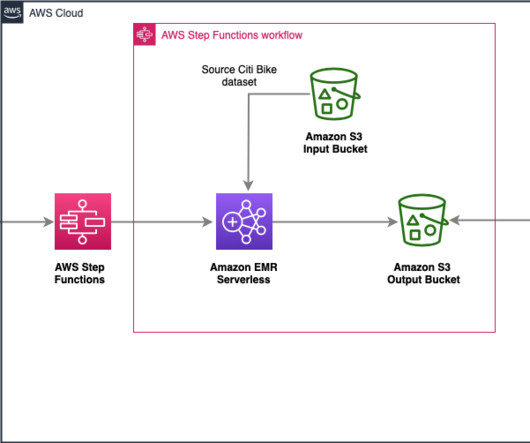
We used the AWS Step Function state machines to define, orchestrate, and execute our data pipelines. Amazon EventBridge We used Amazon EventBridge, the serverless event bus service, to define the event-based rules and schedules that would trigger our AWS Step Functions state machines.
With auto-copy, automation enhances the COPY command by adding jobs for automatic ingestion of data. If storing operational data in a data warehouse is a requirement, synchronization of tables between operational data stores and Amazon Redshift tables is supported.
Let’s look at a few ways that different industries take advantage of streaming data. How industries can benefit from streaming data. Automotive: Monitoring connected, autonomous cars in real time to optimize routes to avoid traffic and for diagnosis of mechanical issues. Optimizing object storage.
You will load the eventdata from the SFTP site, join it to the venue data stored on Amazon S3, apply transformations, and store the data in Amazon S3. The event and venue files are from the TICKIT dataset. For Node parents , select Rename Venue data and Rename Eventdata.
Using EventBridge integration, filtered positional updates are published to an EventBridge event bus. Amazon Location device position events arrive on the EventBridge default bus with source: ["aws.geo"] and detail-type: ["Location Device Position Event"]. In this model, the Lambda function is invoked for each incoming event.
What is the difference between business analytics and data analytics? Business analytics is a subset of data analytics. Data analytics is used across disciplines to find trends and solve problems using data mining , data cleansing, datatransformation, data modeling, and more.
You can use Amazon Data Firehose to aggregate and deliver log events from your applications and services captured in Amazon CloudWatch Logs to your Amazon Simple Storage Service (Amazon S3) bucket and Splunk destinations, for use cases such as data analytics, security analysis, application troubleshooting etc.
Furthermore, it allows for necessary actions to be taken, such as rectifying errors in the data source, refining datatransformation processes, and updating data quality rules. An EventBridge rule receives an event notification from the AWS Glue Data Quality evaluations including the results.
Amazon AppFlow is a fully managed integration service that you can use to securely transfer data from software as a service (SaaS) applications, such as Google BigQuery, Salesforce, SAP, HubSpot, and ServiceNow, to Amazon Web Services (AWS) services such as Amazon Simple Storage Service (Amazon S3) and Amazon Redshift, in just a few clicks.
By providing real-time visibility into the performance and behavior of data-related systems, DataOps observability enables organizations to identify and address issues before they become critical, and to optimize their data-related workflows for maximum efficiency and effectiveness.
This means there are no unintended data errors, and it corresponds to its appropriate designation (e.g., Here, it all comes down to the datatransformation error rate. In other words, it measures the time between when data is expected and the moment when it is readily available for use. date, month, and year).
In the second blog of the Universal Data Distribution blog series , we explored how Cloudera DataFlow for the Public Cloud (CDF-PC) can help you implement use cases like data lakehouse and data warehouse ingest, cybersecurity, and log optimization, as well as IoT and streaming data collection.
Cloudera users can securely connect Rill to a source of event stream data, such as Cloudera DataFlow , model data into Rill’s cloud-based Druid service, and share live operational dashboards within minutes via Rill’s interactive metrics dashboard or any connected BI solution. Cloudera Data Warehouse). Apache Hive.
Additionally, there are major rewrites to deliver developer-focused improvements, including static type checking, enhanced runtime validation, strong consistency in call patterns, and optimizedevent chaining. is modernized by using promises for all actions, so developers can use async and await functions for better event management.
Different communication infrastructure types such as mesh network and cellular can be used to send load information on a pre-defined schedule or eventdata in real time to the backend servers residing in the utility UDN (Utility Data Network).
This service supports a range of optimized AI models, enabling seamless and scalable AI inference. By leveraging the NVIDIA NeMo platform and optimized versions of open-source models like Llama 3 and Mistral, businesses can harness the latest advancements in natural language processing, computer vision, and other AI domains.
Our customers must also have secure access to their data from anywhere – from on-premises to hybrid clouds and multiple public clouds. We must integrate and optimize the end-to-end data lifecycle for our customers, empowering them to focus on what really matters – extracting value from their data.
It supports modern analytical data lake operations such as create table as select (CTAS), upsert and merge, and time travel queries. Athena also supports the ability to create views and perform VACUUM (snapshot expiration) on Apache Iceberg tables to optimize storage and performance.
Datatransformation plays a pivotal role in providing the necessary data insights for businesses in any organization, small and large. To gain these insights, customers often perform ETL (extract, transform, and load) jobs from their source systems and output an enriched dataset.
If you can’t make sense of your business data, you’re effectively flying blind. Insights hidden in your data are essential for optimizing business operations, finetuning your customer experience, and developing new products — or new lines of business, like predictive maintenance. Azure Data Factory.
Oracle GoldenGate for Oracle Database and Big Data adapters Oracle GoldenGate is a real-time data integration and replication tool used for disaster recovery, data migrations, high availability. GoldenGate provides special tools called S3 event handlers to integrate with Amazon S3 for data replication.
Due to this low complexity, the solution uses AWS serverless services to ingest the data, transform it, and make it available for analytics. The serverless architecture features auto scaling, high availability, and a pay-as-you-go billing model to increase agility and optimize costs.
Additionally, a TCO calculator generates the TCO estimation of an optimized EMR cluster for facilitating the migration. Transform the YARN job history logs from JSON to CSV After obtaining YARN logs, you run a YARN log organizer, yarn-log-organizer.py, which is a parser to transform JSON-based logs to CSV files.
Once a draft has been created or opened, developers use the visual Designer to build their data flow logic and validate it using interactive test sessions. In the Designer, you have the ability to start and stop each step of the data pipeline, resulting in events being queued up in the connections that link the processing steps together.
Amazon Redshift enables you to use SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and machine learning (ML) to deliver the best price-performance at scale. Shashank Tewari is a Senior Technical Account Manager at AWS.
YuniKorn is designed for Big Data app workloads, and it natively supports to run Spark/Flink/Tensorflow, etc efficiently in K8s. YuniKorn is optimized for performance, it is suitable for high throughput and large scale environments. YuniKorn scheduler provides an optimal solution to manage resource quotas by using resource queues.
It’s a pantry because all the data one needs is readily available and easily accessible, with labels that are immediately recognized and understood by the users of the application. In tech speak, this means the semantic layer is optimized for the intended audience.
Stored procedures are commonly used to encapsulate logic for datatransformation, data validation, and business-specific logic. It inserts a record in the procedure_log table in the event of an exception. It also has an EXCEPTION block and inserts a record in the procedure_log table in the event of an exception.
As part of the solution workflow, EventBridge receives an event for each PCA solution analysis output file. Kinesis Data Firehose uses Lambda to perform datatransformation and compression, storing the file in a compressed columnar format (Parquet) in the target S3 bucket. step 3) on the Amazon S3 console.
With EMR Serverless, you don’t have to configure, optimize, secure, or operate clusters to run applications with these frameworks. You can run analytics workloads at any scale with automatic scaling that resizes resources in seconds to meet changing data volumes and processing requirements.
When it comes to data modeling, function determines form. Let’s say you want to subject a dataset to some form of anomaly detection; your model might take the form of a singular event stream that can be read by an anomaly detection service. filling in nulls, changing time zones, formatting strings, conditional logic, etc.)
We use Apache Spark as our main data processing engine and have over 1,000 Spark applications running over massive amounts of data every day. These Spark applications implement our business logic ranging from datatransformation, machine learning (ML) model inference, to operational tasks. Their costs were climbing.
DataBrew is a visual data preparation tool that enables you to clean and normalize data without writing any code. The over 200 transformations it provides are now available to be used in an AWS Glue Studio visual job. We can use knowledge of the data to optimize the join by filtering the data we really need.
When you start the process of designing your data model for Amazon Keyspaces, it’s essential to possess a comprehensive understanding of your access patterns, similar to the approach used in other NoSQL databases. Additionally, you can configure OpenSearch Ingestion to apply datatransformations before delivery.
The key idea behind incremental queries is to use metadata or change tracking mechanisms to identify the new or modified data since the last query. By identifying these changes, the query engine can optimize the query to process only the relevant data, significantly reducing the processing time and resource requirements.
Curated foundation models, such as those created by IBM or Microsoft, help enterprises scale and accelerate the use and impact of the most advanced AI capabilities using trusted data. In addition to natural language, models are trained on various modalities, such as code, time-series, tabular, geospatial and IT eventsdata.
Finally, CFM uses an AWS Graviton architecture to optimize even more cost and performance (as highlighted in the screenshot below). Another advantage was improved security, particularly the ability to contain the potential impact area in the event of credential leaks or account compromises.
Additionally, the scale is significant because the multi-tenant data sources provide a continuous stream of testing activity, and our users require quick data refreshes as well as historical context for up to a decade due to compliance and regulatory demands. Finally, data integrity is of paramount importance.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content