This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The Airflow REST API facilitates a wide range of use cases, from centralizing and automating administrative tasks to building event-driven, data-aware data pipelines. Event-driven architectures – The enhanced API facilitates seamless integration with external events, enabling the triggering of Airflow DAGs based on these events.
The need for streamlined datatransformations As organizations increasingly adopt cloud-based data lakes and warehouses, the demand for efficient datatransformation tools has grown. This approach helps in managing storage costs while maintaining the flexibility to analyze historical trends when needed.
Together with price-performance, Amazon Redshift offers capabilities such as serverless architecture, machine learning integration within your data warehouse and secure data sharing across the organization. dbt Cloud is a hosted service that helps data teams productionize dbt deployments. or a later version) database.
Your generated jobs can use a variety of datatransformations, including filters, projections, unions, joins, and aggregations, giving you the flexibility to handle complex data processing requirements. In this post, we discuss how Amazon Q data integration transforms ETL workflow development.
How dbt Core aids data teams test, validate, and monitor complex datatransformations and conversions Photo by NASA on Unsplash Introduction dbt Core, an open-source framework for developing, testing, and documenting SQL-based datatransformations, has become a must-have tool for modern data teams as the complexity of data pipelines grows.
Upload your data, click through a workflow, walk away. If you’re a professional data scientist, you already have the knowledge and skills to test these models. Get your results in a few hours. Why would you want autoML to build models for you? It buys time and breathing room. And it made sense.
The goal of DataOps Observability is to provide visibility of every journey that data takes from source to customer value across every tool, environment, data store, data and analytic team, and customer so that problems are detected, localized and raised immediately. A data journey spans and tracks multiple pipelines.
Developers need to onboard new data sources, chain multiple datatransformation steps together, and explore data as it travels through the flow. This allows developers to make changes to their processing logic on the fly while running some testdata through their flow and validating that their changes work as intended.
Build data validation rules directly into ingestion layers so that insufficient data is stopped at the gate and not detected after damage is done. Use lineage tooling to trace data from source to report. Understanding how datatransforms and where it breaks is crucial for audibility and root-cause resolution.
Also known as data validation, integrity refers to the structural testing of data to ensure that the data complies with procedures. This means there are no unintended data errors, and it corresponds to its appropriate designation (e.g., Here, it all comes down to the datatransformation error rate.
What is the difference between business analytics and data analytics? Business analytics is a subset of data analytics. Data analytics is used across disciplines to find trends and solve problems using data mining , data cleansing, datatransformation, data modeling, and more.
The advent of rapid adoption of serverless data lake architectures—with ever-growing datasets that need to be ingested from a variety of sources, followed by complex datatransformation and machine learning (ML) pipelines—can present a challenge. These event changes are also routed to the same SNS topic.
Our approach The migration initiative consisted of two main parts: building the new architecture and migrating data pipelines from the existing tool to the new architecture. Often, we would work on both in parallel, testing one component of the architecture while developing another at the same time.
All this contributes to your overall data integrity profile. Logical data integrity is designed to guard against human error. We’ll explore this concept in detail in the testing section below. Data integrity: A process and a state. There are two means for ensuring data integrity: process and testing.
Allows them to iteratively develop processing logic and test with as little overhead as possible. Plays nice with existing CI/CD processes to promote a data pipeline to production. Provides monitoring, alerting, and troubleshooting for production data pipelines.
A modern data platform entails maintaining data across multiple layers, targeting diverse platform capabilities like high performance, ease of development, cost-effectiveness, and DataOps features such as CI/CD, lineage, and unit testing. It does this by helping teams handle the T in ETL (extract, transform, and load) processes.
Using EventBridge integration, filtered positional updates are published to an EventBridge event bus. Amazon Location device position events arrive on the EventBridge default bus with source: ["aws.geo"] and detail-type: ["Location Device Position Event"]. In this model, the Lambda function is invoked for each incoming event.
The techniques for managing organisational data in a standardised approach that minimises inefficiency. Extraction, Transform, Load (ETL). The extraction of raw data, transforming to a suitable format for business needs, and loading into a data warehouse. Datatransformation. Microsoft Azure.
Traditionally, such a legacy call center analytics platform would be built on a relational database that stores data from streaming sources. Datatransformations through stored procedures and use of materialized views to curate datasets and generate insights is a known pattern with relational databases.
It has not been specifically designed for heavy datatransformation tasks. To load the time series for a specific point into a pandas data frame, you can use the awswrangler library from your Python code: import awswrangler as wr import pandas as pd # Retrieving the data directly from Amazon S3 df = wr.s3.read_parquet("s3://
On many occasions, they need to apply business logic to the data received from the source SaaS platform before pushing it to the target SaaS platform. AnyCompany’s marketing team hosted an event at the Anaheim Convention Center, CA. The marketing team created leads based on the event in Adobe Marketo. Let’s take an example.
Cloudera users can securely connect Rill to a source of event stream data, such as Cloudera DataFlow , model data into Rill’s cloud-based Druid service, and share live operational dashboards within minutes via Rill’s interactive metrics dashboard or any connected BI solution. Cloudera Data Warehouse). Apache Hive.
Be sure test cases represent the diversity of app users. As an AI product manager, here are some important data-related questions you should ask yourself: What is the problem you’re trying to solve? What datatransformations are needed from your data scientists to prepare the data? The perfect fit.
The upstream data pipeline is a robust system that integrates various data sources, including Amazon Kinesis and Amazon Managed Streaming for Apache Kafka (Amazon MSK) for handling clickstream events, Amazon Relational Database Service (Amazon RDS) for delta transactions, and Amazon DynamoDB for delta game-related information.
Angel-Johnson says she, too, has a heightened level of concern around security issues and more specifically data protection. I thought I was hired for digital transformation but what is really needed is a datatransformation,” she says. To get there, Angel-Johnson has embarked on a master data management initiative.
Duplicating data from a production database to a lower or lateral environment and masking personally identifiable information (PII) to comply with regulations enables development, testing, and reporting without impacting critical systems or exposing sensitive customer data. PII detection and scrubbing.
The data products from the Business Vault and Data Mart stages are now available for consumers. smava decided to use Tableau for business intelligence, data visualization, and further analytics. The datatransformations are managed with dbt to simplify the workflow governance and team collaboration.
Kinesis Data Firehose is a fully managed service for delivering near-real-time streaming data to various destinations for storage and performing near-real-time analytics. You can perform analytics on VPC flow logs delivered from your VPC using the Kinesis Data Firehose integration with Datadog as a destination.
Tricentis is the global leader in continuous testing for DevOps, cloud, and enterprise applications. Speed changes everything, and continuous testing across the entire CI/CD lifecycle is the key. Tricentis instills that confidence by providing software tools that enable Agile Continuous Testing (ACT) at scale.
Datatransformation plays a pivotal role in providing the necessary data insights for businesses in any organization, small and large. To gain these insights, customers often perform ETL (extract, transform, and load) jobs from their source systems and output an enriched dataset.
The Test and Development queue have fixed resource limits. YuniKorn is also compatible with the management commands and utilities, such as cordon nodes, retrieving events via kubectl, etc. Cloudera’s CDP platform offers Cloudera Data Engineering experience which is powered by Apache YuniKorn (Incubating). Acknowledgments.
Detailed Data and Model Lineage Tracking*: Ensures comprehensive tracking and documentation of datatransformations and model lifecycle events, enhancing reproducibility and auditability.
With these features, you can now build data pipelines completely in standard SQL that are serverless, more simple to build, and able to operate at scale. Typically, datatransformation processes are used to perform this operation, and a final consistent view is stored in an S3 bucket or folder.
The problem is that a new unique identifier of a test example won’t be anywhere in the tree. Feature extraction means moving from low-level features that are unsuitable for learning—practically speaking, we get poor testing results—to higher-level features which are useful for learning. Separate out a hold-out test set.
DataBrew is a visual data preparation tool that enables you to clean and normalize data without writing any code. The over 200 transformations it provides are now available to be used in an AWS Glue Studio visual job. Apache Spark is the engine that runs the jobs created on AWS Glue Studio.
Within a large enterprise, there is a huge amount of data accumulated over the years – many decisions have been made and different methods have been tested. We minimized the time between the event (and what the journalist wanted to say about it) and the moment the reader or viewer could consume it.
Customers rely on data from different sources such as mobile applications, clickstream events from websites, historical data, and more to deduce meaningful patterns to optimize their products, services, and processes. If you’re testing on a different Amazon MWAA version, update the requirements file accordingly.
Few actors in the modern data stack have inspired the enthusiasm and fervent support as dbt. This datatransformation tool enables data analysts and engineers to transform, test and document data in the cloud data warehouse. But what does this mean from a practitioner perspective?
We use Apache Spark as our main data processing engine and have over 1,000 Spark applications running over massive amounts of data every day. These Spark applications implement our business logic ranging from datatransformation, machine learning (ML) model inference, to operational tasks. Their costs were climbing.
Transform the YARN job history logs from JSON to CSV After obtaining YARN logs, you run a YARN log organizer, yarn-log-organizer.py, which is a parser to transform JSON-based logs to CSV files. The parser also has other capabilities, including sorting events by time, removing dedicates, and merging multiple logs. Choose Delete.
You can examine various events from the stack creation process on the Events tab. Select the connection again and on the Actions menu, choose Test connection. Testing the connection can take approximately 1 minute. You will see the message “Successfully connected to the data store with connection blog-redshift-connection.”
In this post, we discuss why AWS recommends moving from Kinesis Data Analytics for SQL Applications to Amazon Kinesis Data Analytics for Apache Flink to take advantage of Apache Flink’s advanced streaming capabilities. View the stream data. Transform and enrich the data. Manipulate the data with Python.
It may well be that one thing that a CDO needs to get going is a datatransformation programme. This may purely be focused on cultural aspects of how an organisation records, shares and otherwise uses data. It may be to build a new (or a first) Data Architecture. Establishing a regular Data Audit.
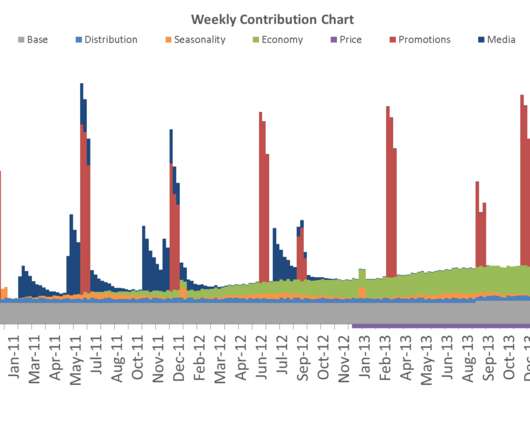
More often than I would like to admit, I have heard the following phrase from a client: “We do not have the data for the five media campaigns we ran last year, but we have data for the other four. The classical approach is to assume the adstock function (typically linear ) and test out various values of ?
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content