This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This improvement streamlines the ability to access and manage your Airflow environments and their integration with external systems, and allows you to interact with your workflows programmatically. Airflow REST API The Airflow REST API is a programmatic interface that allows you to interact with Airflow’s core functionalities.
The need for streamlined datatransformations As organizations increasingly adopt cloud-based data lakes and warehouses, the demand for efficient datatransformation tools has grown. Next, use the dbt Cloud interactive development environment (IDE) to deploy your project.
Together with price-performance, Amazon Redshift offers capabilities such as serverless architecture, machine learning integration within your data warehouse and secure data sharing across the organization. dbt Cloud is a hosted service that helps data teams productionize dbt deployments. Choose Test Connection.
How dbt Core aids data teams test, validate, and monitor complex datatransformations and conversions Photo by NASA on Unsplash Introduction dbt Core, an open-source framework for developing, testing, and documenting SQL-based datatransformations, has become a must-have tool for modern data teams as the complexity of data pipelines grows.
The rise of SaaS business intelligence tools is answering that need, providing a dynamic vessel for presenting and interacting with essential insights in a way that is digestible and accessible. The future is bright for logistics companies that are willing to take advantage of big data.
Extrinsic Control Deficit: Many of these changes stem from tools and processes beyond the immediate control of the data team. Unregulated ETL/ELT Processes: The absence of stringent data quality tests in ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) processes further exacerbates the problem.
from the business interactions), but if not available, then through confirmation techniques of an independent nature. It will indicate whether data is void of significant errors. Also known as data validation, integrity refers to the structural testing of data to ensure that the data complies with procedures.
Amazon Athena provides interactive analytics service for analyzing the data in Amazon Simple Storage Service (Amazon S3). Amazon Redshift is used to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes.
Developers need to onboard new data sources, chain multiple datatransformation steps together, and explore data as it travels through the flow. Interactivity when needed while saving costs. To meet this need we’ve introduced a new concept called test sessions with the DataFlow Designer. .
It’s also an analytics suite that you can use to perform interactive log analytics, real-time application monitoring, security analytics and more. OpenSearch also includes capabilities to ingest and analyze data. For example, the following creates a collection called test with one shard and no replicas.
A modern data platform entails maintaining data across multiple layers, targeting diverse platform capabilities like high performance, ease of development, cost-effectiveness, and DataOps features such as CI/CD, lineage, and unit testing. It does this by helping teams handle the T in ETL (extract, transform, and load) processes.
Airflow has been adopted by many Cloudera Data Platform (CDP) customers in the public cloud as the next generation orchestration service to setup and operationalize complex data pipelines. It was critical to make the interactions as intuitive as possible to avoid slowing down the flow of the user.
They use various AWS analytics services, such as Amazon EMR, to enable their analysts and data scientists to apply advanced analytics techniques to interactively develop and test new surveillance patterns and improve investor protection. starts_with(OutputKey,'eksclusterEKSConfig')].OutputValue" OutputKey=='HiveSecretName'].OutputValue"
Allows them to iteratively develop processing logic and test with as little overhead as possible. Plays nice with existing CI/CD processes to promote a data pipeline to production. Provides monitoring, alerting, and troubleshooting for production data pipelines.
Each CDH dataset has three processing layers: source (raw data), prepared (transformeddata in Parquet), and semantic (combined datasets). It is possible to define stages (DEV, INT, PROD) in each layer to allow structured release and test without affecting PROD.
To grow the power of data at scale for the long term, it’s highly recommended to design an end-to-end development lifecycle for your data integration pipelines. The following are common asks from our customers: Is it possible to develop and test AWS Glue data integration jobs on my local laptop?
However, you might face significant challenges when planning for a large-scale data warehouse migration. This will enable right-sizing the Redshift data warehouse to meet workload demands cost-effectively. Additional considerations – Factor in additional tasks beyond schema conversion.
As creators and experts in Apache Druid, Rill understands the data store’s importance as the engine for real-time, highly interactive analytics. Cloudera Data Warehouse). Efficient batch data processing. Complex datatransformations. Figure 1: Rill and Cloudera Architecture. Apache Hive. Windowing functions.
We introduce you to Amazon Managed Service for Apache Flink Studio and get started querying streaming datainteractively using Amazon Kinesis Data Streams. Traditionally, such a legacy call center analytics platform would be built on a relational database that stores data from streaming sources.
The problem is that a new unique identifier of a test example won’t be anywhere in the tree. Feature extraction means moving from low-level features that are unsuitable for learning—practically speaking, we get poor testing results—to higher-level features which are useful for learning. Separate out a hold-out test set.
Be sure test cases represent the diversity of app users. As an AI product manager, here are some important data-related questions you should ask yourself: What is the problem you’re trying to solve? What datatransformations are needed from your data scientists to prepare the data? The perfect fit.
Comprehensive safeguards, including authentication and authorization, ensure that only users with configured access can interact with the model endpoint. The service also meets enterprise-grade security and compliance standards, recording all model interactions for governance and audit.
DataBrew is a visual data preparation tool that enables you to clean and normalize data without writing any code. The over 200 transformations it provides are now available to be used in an AWS Glue Studio visual job. Create a DataBrew recipe Start by registering the data store for the claims file.
The general availability covers Iceberg running within some of the key data services in CDP, including Cloudera Data Warehouse ( CDW ), Cloudera Data Engineering ( CDE ), and Cloudera Machine Learning ( CML ). In the final stage of our ETL pipeline, we load new data into this partition. Using CDW with Iceberg.
Apache Spark unifies batch processing, real-time processing, stream analytics, machine learning, and interactive query in one-platform. The Test and Development queue have fixed resource limits. Background. Why choose K8s for Apache Spark. All other queues are only limited by the size of the cluster. Acknowledgments.
For data pipeline orchestration, the Apache Airflow UI is a user-friendly tool that provides detailed views into your data pipeline. When it comes to pipeline health management, each service that your tasks are interacting with could be storing or publishing logs to different locations, such as an S3 bucket or Amazon CloudWatch logs.
Building a starter version of anything can often be straightforward, but building something with enterprise-grade scale, security, resiliency, and performance typically requires knowledge of and adherence to battle-tested best practices, and using the right tools and features in the right scenario. Data Vault 2.0
You can also use the datatransformation feature of Data Firehose to invoke a Lambda function to perform datatransformation in batches. This solution includes a Lambda function that continuously updates the Amazon Location tracker with simulated location data from fictitious journeys.
In this post, we discuss why AWS recommends moving from Kinesis Data Analytics for SQL Applications to Amazon Kinesis Data Analytics for Apache Flink to take advantage of Apache Flink’s advanced streaming capabilities. Kinesis Data Analytics Studio allows us to create a notebook, which is a web-based development environment.
Within a large enterprise, there is a huge amount of data accumulated over the years – many decisions have been made and different methods have been tested. This is one of the main diagnostic tests. The doctor needs to know how to collect the data from this image. This process requires great expertise.
Few actors in the modern data stack have inspired the enthusiasm and fervent support as dbt. This datatransformation tool enables data analysts and engineers to transform, test and document data in the cloud data warehouse. Jason: What’s the value of using dbt with the data catalog ?
As data science is growing in popularity and importance , if your organization uses data science, you’ll need to pay more attention to picking the right tools for this. An example of a data science tool is Dataiku. Business Intelligence Tools: Business intelligence (BI) tools are used to visualize your data.
For these workloads, data lake vendors usually recommend extracting data into flat files to be used solely for model training and testing purposes. This adds an additional ETL step, making the data even more stale. Data lakehouse was created to solve these problems. Each node can be different from the others.
Solutions Architect – AWS SafeGraph is a geospatial data company that curates over 41 million global points of interest (POIs) with detailed attributes, such as brand affiliation, advanced category tagging, and open hours, as well as how people interact with those places. These versions are all exposed to users via their UI.
While they require task-specific labeled data for fine tuning, they also offer clients the best cost performance trade-off for non-generative use cases. offers a Prompt Lab, where users can interact with different prompts using prompt engineering on generative AI models for both zero-shot prompting and few-shot prompting.
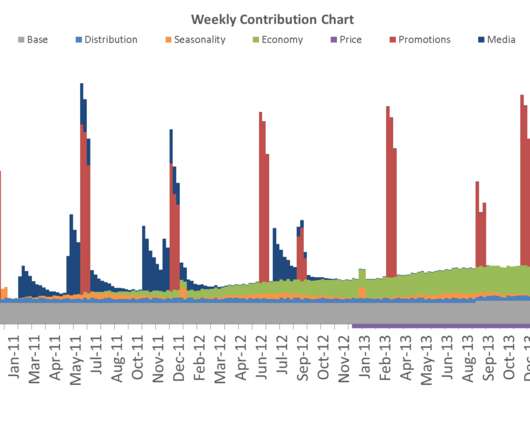
Before the data is put into the model comes a process called feature engineering – transforming the original data columns to impose certain business assumptions or simply increase model accuracy. The classical approach is to assume the adstock function (typically linear ) and test out various values of ?
dbt is an open source, SQL-first templating engine that allows you to write repeatable and extensible datatransforms in Python and SQL. dbt is predominantly used by data warehouses (such as Amazon Redshift ) customers who are looking to keep their datatransform logic separate from storage and engine.
The initiative has enhanced coordination, as automation APIs facilitate interaction with security tools as well as streamline coordination and enhance mitigation responses. This is a new way to interact with the web and search. This enabled the team to expose the technology to a small group of senior leaders to test.
After the data lands in Amazon S3, smava uses the AWS Glue Data Catalog and crawlers to automatically catalog the available data, capture the metadata, and provide an interface that allows querying all data assets. The data products from the Business Vault and Data Mart stages are now available for consumers.
Modak Nabu relies on a framework of “Botworks”, a series of micro-jobs to accomplish various datatransformation steps from ingestion to profiling, and indexing. Cloudera Data Engineering within CDP provides : Fully managed Spark-on-Kubernetes service that hides the complexity running production DE workloads at scale.
Through meticulous testing and research, we’ve curated a list of the ten best BI tools, ensuring accessibility and efficacy for businesses of all sizes. In essence, the core capabilities of the best BI tools revolve around four essential functions: data integration, datatransformation, data visualization, and reporting.
Showpad built new customer-facing embedded dashboards within Showpad eOSTM and migrated its legacy dashboards to Amazon QuickSight , a unified BI service providing modern interactive dashboards, natural language querying, paginated reports, machine learning (ML) insights, and embedded analytics at scale.
AWS Glue establishes a secure connection to HubSpot using OAuth for authorization and TLS for data encryption in transit. AWS Glue also supports the ability to apply complex datatransformations, enabling efficient data integration and preparation to meet your needs. Choose Next. Choose Connect App. Choose Next.
This is in contrast to traditional BI, which extracts insight from data outside of the app. As rich, data-driven user experiences are increasingly intertwined with our daily lives, end users are demanding new standards for how they interact with their business data. Yes—but basic dashboards won’t be enough.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content