This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Their terminal operations rely heavily on seamless data flows and the management of vast volumes of data. Recently, EUROGATE has developed a digital twin for its container terminal Hamburg (CTH), generating millions of data points every second from Internet of Things (IoT)devices attached to its container handling equipment (CHE).
The need for streamlined datatransformations As organizations increasingly adopt cloud-based data lakes and warehouses, the demand for efficient datatransformation tools has grown. This approach helps in managing storage costs while maintaining the flexibility to analyze historical trends when needed.
This post is a continuation of How SOCAR built a streaming data pipeline to process IoTdata for real-time analytics and control. SOCAR has deployed in-car devices that capture data using AWS IoT Core. This data was then stored in Amazon Relational Database Service (Amazon RDS).
Building this single source of truth was the only way the airport would have the capacity to augment the data with a digital twin, IoT sensor data, and predictive analytics, he says. Identifying and eliminating Excel flat files alone was very time consuming.
If storing operational data in a data warehouse is a requirement, synchronization of tables between operational data stores and Amazon Redshift tables is supported. In scenarios where datatransformation is required, you can use Redshift stored procedures to modify data in Redshift tables.
With the ability to browse metadata, you can understand the structure and schema of the data source, identify relevant tables and fields, and discover useful data assets you may not be aware of. She joined AWS in 2021 and brings three years of startup experience leading products in IoTdata platforms.
Kinesis Data Analytics for Apache Flink In our example, we perform the following actions on the streaming data: Connect to an Amazon Kinesis Data Streams data stream. View the stream data. Transform and enrich the data. Manipulate the data with Python. Navigate to the AWS IoT Core console.
Here are a few examples that we have seen of how this can be done: Batch ETL with Azure Data Factory and Azure Databricks: In this pattern, Azure Data Factory is used to orchestrate and schedule batch ETL processes. Azure Blob Storage serves as the data lake to store raw data. Azure Machine Learning).
Such a solution should use the latest technologies, including Internet of Things (IoT) sensors, cloud computing, and machine learning (ML), to provide accurate, timely, and actionable data. To take advantage of this data and build an effective inventory management and forecasting solution, retailers can use a range of AWS services.
But the features in Power BI Premium are now more powerful than the functionality in Azure Analysis Services, so while the service isn’t going away, Microsoft will offer an automated migration tool in the second half of this year for customers who want to move their data models into Power BI instead. Azure Data Factory.
The solution consists of the following interfaces: IoT or mobile application – A mobile application or an Internet of Things (IoT) device allows the tracking of a company vehicle while it is in use and transmits its current location securely to the data ingestion layer in AWS.
The world is moving faster than ever, and companies processing large amounts of rapidly changing or growing data need to evolve to keep up — especially with the growth of Internet of Things (IoT) devices all around us. Let’s look at a few ways that different industries take advantage of streaming data.
With nearly 800 locations, RaceTrac handles a substantial volume of data, encompassing 260 million transactions annually, alongside data feeds from store cameras and internet of things (IoT) devices embedded in fuel pumps. This empowers data users to make decisions informed by data and in real-time with increased confidence.”
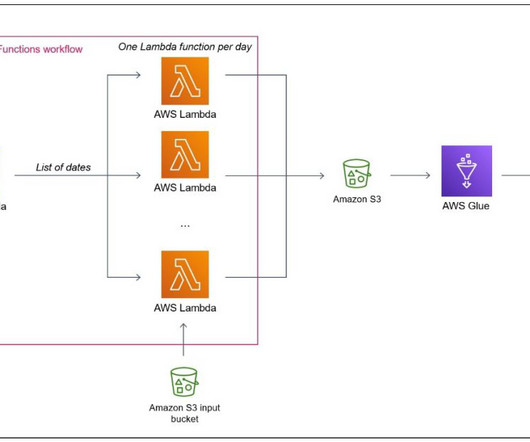
It has not been specifically designed for heavy datatransformation tasks. He enjoys supporting customers in their digital transformation journey, using big data and machine learning to help solve their business challenges. You also use AWS Glue to consolidate the files produced by the parallel tasks.
In the second blog of the Universal Data Distribution blog series , we explored how Cloudera DataFlow for the Public Cloud (CDF-PC) can help you implement use cases like data lakehouse and data warehouse ingest, cybersecurity, and log optimization, as well as IoT and streaming data collection.
Looking at the diagram, we see that Business Intelligence (BI) is a collection of analytical methods applied to big data to surface actionable intelligence by identifying patterns in voluminous data. As we move from right to left in the diagram, from big data to BI, we notice that unstructured datatransforms into structured data.
Looking at the diagram, we see that Business Intelligence (BI) is a collection of analytical methods applied to big data to surface actionable intelligence by identifying patterns in voluminous data. As we move from right to left in the diagram, from big data to BI, we notice that unstructured datatransforms into structured data.
This “revolution” stems from breakthrough advancements in artificial intelligence, robotics, and the Internet of Things (IoT). In this example, I walk through how a manufacturer could build a real-time predictive maintenance pipeline that assigns a probability of failure to IoT devices within the factory.
In this post, we demonstrate how Amazon Redshift can act as the data foundation for your generative AI use cases by enriching, standardizing, cleansing, and translating streaming data using natural language prompts and the power of generative AI.
Last year almost 200 data leaders attended DI Day, demonstrating an abundant thirst for knowledge and support to drive datatransformation projects throughout their diverse organisations. This year we expect to see organisations continue to leverage the power of data to deliver business value and growth.
Data collection and processing are handled by a third-party smart sensor manufacturer application residing in Amazon Virtual Private Cloud (Amazon VPC) private subnets behind a Network Load Balancer. The AWS Glue Data Catalog contains the table definitions for the smart sensor data sources stored in the S3 buckets.
He helps customers innovate their business with AWS Analytics, IoT, and AI/ML services. He has a specialty in big data services and technologies and an interest in building customer business outcomes together. Jiseong Kim is a Senior Data Architect at AWS ProServe.
Elevate your datatransformation journey with Dataiku’s comprehensive suite of solutions. Innovations in 2024 Augmented Reality Data Visualization: Domo introduces augmented reality features for immersive data visualization experiences, enhancing user engagement and understanding.
However, you might face significant challenges when planning for a large-scale data warehouse migration. Data engineers are crucial for schema conversion and datatransformation, and DBAs can handle cluster configuration and workload monitoring. Platform architects define a well-architected platform.
Furthermore, these tools boast customization options, allowing users to tailor data sources to address areas critical to their business success, thereby generating actionable insights and customizable reports. Best BI Tools for Data Analysts 3.1 Key Features: Extensive library of pre-built connectors for diverse data sources.
This adds an additional ETL step, making the data even more stale. Data lakehouse was created to solve these problems. The data warehouse storage layer is removed from lakehouse architectures. Instead, continuous datatransformation is performed within the BLOB storage. Each node can be different from the others.
He helps customers innovate their business with AWS Analytics, IoT, and AI/ML services. He has a specialty in big data services and technologies and an interest in building customer business outcomes together. Jiseong Kim is a Senior Data Architect at AWS ProServe.
Data Extraction : The process of gathering data from disparate sources, each of which may have its own schema defining the structure and format of the data and making it available for processing. This can include tasks such as data ingestion, cleansing, filtering, aggregation, or standardization.
Firehose is integrated with over 20 AWS services, so you can deliver real-time data from Amazon Kinesis Data Streams , Amazon Managed Streaming for Apache Kafka , Amazon CloudWatch Logs , AWS Internet of Things (AWS IoT) , AWS WAF , Amazon Network Firewall Logs , or from your custom applications (by invoking the Firehose API) into Iceberg tables.
This post explores the strategies the Airties team employed during this transformation, the challenges they overcame, and how they achieved a more efficient, scalable, and maintenance-free streaming infrastructure.
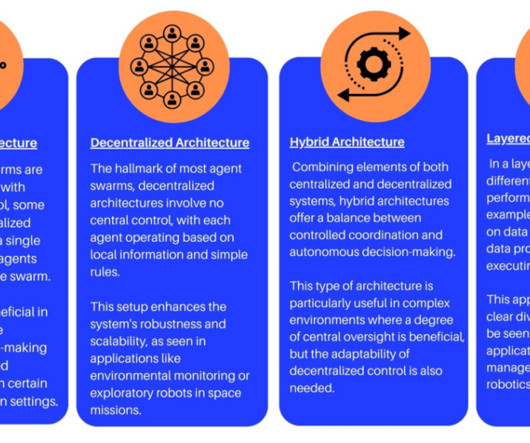
The Agent Swarm evolution has been propelled by advancements in computing, artificial intelligence (AI), machine learning (ML), and the Internet of Things (IoT). Gather/Insert data on market trends, customer behavior, inventory levels, or operational efficiency.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content