This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Why: Data Makes It Different. In contrast, a defining feature of ML-powered applications is that they are directly exposed to a large amount of messy, real-world data which is too complex to be understood and modeled by hand. However, the concept is quite abstract. Can’t we just fold it into existing DevOps best practices?
response = client.create( key="test", value="Test value", description="Test description" ) print(response) print("nListing all variables.") variables = client.list() print(variables) print("nGetting the test variable.") Creating a test variable. Creating a test variable. Creating a test variable.
The data in Amazon Redshift is transactionally consistent and updates are automatically and continuously propagated. Together with price-performance, Amazon Redshift offers capabilities such as serverless architecture, machine learning integration within your data warehouse and secure data sharing across the organization.
The need for streamlined datatransformations As organizations increasingly adopt cloud-based data lakes and warehouses, the demand for efficient datatransformation tools has grown. This approach helps in managing storage costs while maintaining the flexibility to analyze historical trends when needed.
Complex Data TransformationsTest Planning Best Practices Ensuring data accuracy with structured testing and best practices Photo by Taylor Vick on Unsplash Introduction Datatransformations and conversions are crucial for data pipelines, enabling organizations to process, integrate, and refine raw data into meaningful insights.
In this post, well see the fundamental procedures, tools, and techniques that data engineers, data scientists, and QA/testing teams use to ensure high-quality data as soon as its deployed. First, we look at how unit and integration tests uncover transformation errors at an early stage. PyTest, JUnit,NUnit).
Managing tests of complex datatransformations when automated datatesting tools lack important features? Photo by Marvin Meyer on Unsplash Introduction Datatransformations are at the core of modern business intelligence, blending and converting disparate datasets into coherent, reliable outputs.
Common challenges and practical mitigation strategies for reliable datatransformations. Photo by Mika Baumeister on Unsplash Introduction Datatransformations are important processes in data engineering, enabling organizations to structure, enrich, and integrate data for analytics , reporting, and operational decision-making.
At Atlanta’s Hartsfield-Jackson International Airport, an IT pilot has led to a wholesale data journey destined to transform operations at the world’s busiest airport, fueled by machine learning and generative AI. Applying AI to elevate ROI Pruitt and Databricks recently finished a pilot test with Microsoft called Smart Flow.
When it comes to the use of modern big data technologies by hospitals, it is about health care and saving lives. These systems rely heavily on big data to improve efficiency and cost-effectiveness. It is simple and convenient to use outsourcing IT services when you need to get a perfect big data solution. Conclusion.
How dbt Core aids data teams test, validate, and monitor complex datatransformations and conversions Photo by NASA on Unsplash Introduction dbt Core, an open-source framework for developing, testing, and documenting SQL-based datatransformations, has become a must-have tool for modern data teams as the complexity of data pipelines grows.
How GX helps data teams validate, test, and monitor complex data pipelines Introduction Data flows from diverse sources, and transformations are becoming increasingly complex. Great Expectations can enable a wide range of datatransformations and conversion operations.
Ever increasing demands for transformation. Growing cybersecurity, data privacy threats. According to Evanta’s 2022 CIO Leadership Perspectives study, CIOs’ second top priority within the IT function is around data and analytics, with CIOs seeing advancing organizational use of data as key to reaching enterprise objectives.
For each service, you need to learn the supported authorization and authentication methods, data access APIs, and framework to onboard and testdata sources. This approach simplifies your data journey and helps you meet your security requirements. Choose Add data. For Database , enter your database name.
A common task for a data scientist is to build a predictive model. You know the drill: pull some data, carve it up into features, feed it into one of scikit-learn’s various algorithms. Collectively, your attempts teach you about your data and its relation to the problem you’re trying to solve.
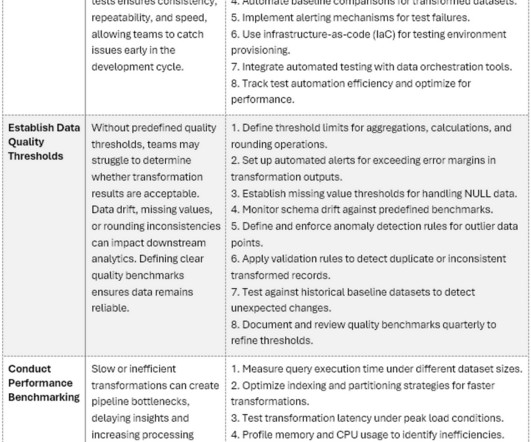
Its EssentialVerifying DataTransformations (Part4) Uncovering the leading problems in datatransformation workflowsand practical ways to detect and preventthem In Parts 13 of this series of blogs, categories of datatransformations were identified as among the top causes of data quality defects in data pipeline workflows.
AI is transforming how senior data engineers and data scientists validate datatransformations and conversions. Artificial intelligence-based verification approaches aid in the detection of anomalies, the enforcement of data integrity, and the optimization of pipelines for improved efficiency.
Table of Contents 1) Benefits Of Big Data In Logistics 2) 10 Big Data In Logistics Use Cases Big data is revolutionizing many fields of business, and logistics analytics is no exception. The complex and ever-evolving nature of logistics makes it an essential use case for big data applications. Did you know?
Your generated jobs can use a variety of datatransformations, including filters, projections, unions, joins, and aggregations, giving you the flexibility to handle complex data processing requirements. In this post, we discuss how Amazon Q data integration transforms ETL workflow development.
What Is Data Quality Management (DQM)? Data quality management is a set of practices that aim at maintaining a high quality of information. It goes all the way from the acquisition of data and the implementation of advanced data processes, to an effective distribution of data.
Data operations (or data production) is a series of pipeline procedures that take raw data, progress through a series of processing and transformation steps, and output finished products in the form of dashboards, predictions, data warehouses or whatever the business requires. Their product is the data.
Observability is a methodology for providing visibility of every journey that data takes from source to customer value across every tool, environment, data store, team, and customer so that problems are detected and addressed immediately. to monitor your data operations. DataOps Industry Challenges. This call is from the CEO?his
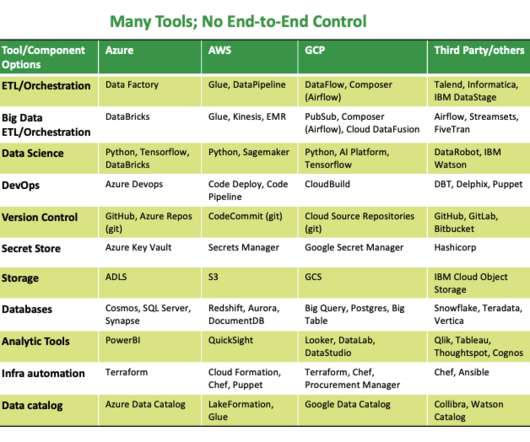
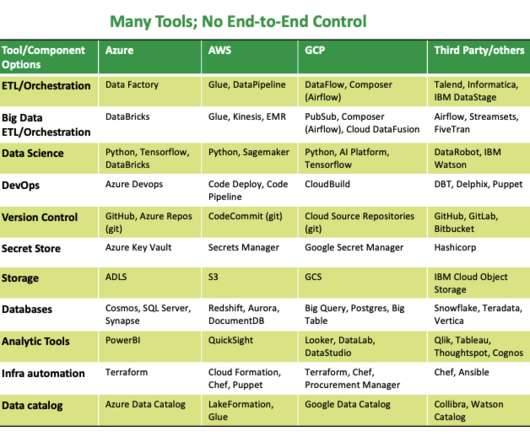
While working in Azure with our customers, we have noticed several standard Azure tools people use to develop data pipelines and ETL or ELT processes. We counted ten ‘standard’ ways to transform and set up batch data pipelines in Microsoft Azure. You can use it for big data analytics and machine learning workloads.
Extrinsic Control Deficit: Many of these changes stem from tools and processes beyond the immediate control of the data team. Unregulated ETL/ELT Processes: The absence of stringent data quality tests in ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) processes further exacerbates the problem.
They may also learn from evidence, but the data and the modelling fundamentally comes from humans in some way. Data Science – Data science is the field of study that combines domain expertise, programming skills, and knowledge of mathematics and statistics to extract meaningful insights from data. Credit: [link].
Data-driven companies sense change through data analytics. Companies turn to their data organization to provide the analytics that stimulates creative problem-solving. Companies turn to their data organization to provide the analytics that stimulates creative problem-solving. – Leon C. Adapt or face decline.
Building a data platform involves various approaches, each with its unique blend of complexities and solutions. In this post, we delve into a case study for a retail use case, exploring how the Data Build Tool (dbt) was used effectively within an AWS environment to build a high-performing, efficient, and modern data platform.
We live in a world of data: There’s more of it than ever before, in a ceaselessly expanding array of forms and locations. Dealing with Data is your window into the ways data teams are tackling the challenges of this new world to help their companies and their customers thrive. What is data integrity?
What is the difference between business analytics and data analytics? Business analytics is a subset of data analytics. Data analytics is used across disciplines to find trends and solve problems using data mining , data cleansing, datatransformation, data modeling, and more.
The main driving factors include lower total cost of ownership, scalability, stability, improved ingestion connectors (such as Data Prepper , Fluent Bit, and OpenSearch Ingestion), elimination of external cluster managers like Zookeeper, enhanced reporting, and rich visualizations with OpenSearch Dashboards.
What is data analytics? Data analytics is a discipline focused on extracting insights from data. It comprises the processes, tools and techniques of data analysis and management, including the collection, organization, and storage of data. What are the four types of data analytics?
Observability is a methodology for providing visibility of every journey that data takes from source to customer value across every tool, environment, data store, team, and customer so that problems are detected and addressed immediately. to monitor your data operations. DataOps Industry Challenges. This call is from the CEO?his
Observability is a methodology for providing visibility of every journey that data takes from source to customer value across every tool, environment, data store, team, and customer so that problems are detected and addressed immediately. Data journey observability is the first step in implementing DataOps.
Photo by CDC on Unsplash Many data pipeline failures and quality issues that are detected by data observability tools in production could have been prevented earlier in the pipeline lifecycle with better pre-production testing strategies. Helps identify transformation errors, and data quality issues early, minimizing risks.
Cloudera has been providing enterprise support for Apache NiFi since 2015, helping hundreds of organizations take control of their data movement pipelines on premises and in the public cloud. Developers need to onboard new data sources, chain multiple datatransformation steps together, and explore data as it travels through the flow.
In addition to using native managed AWS services that BMS didn’t need to worry about upgrading, BMS was looking to offer an ETL service to non-technical business users that could visually compose datatransformation workflows and seamlessly run them on the AWS Glue Apache Spark-based serverless data integration engine.
An expansive view of what it means to use data online, both from the type of data perspective and the kind of desired impact perspective. What is the first thing you want when you think about web analytics? Of course tools. What to do, where to start, what's cool. recommending tools for the complete web analytics 2.0 spectrum.
We’re excited to announce the general availability of the open source adapters for dbt for all the engines in CDP — Apache Hive , Apache Impala , and Apache Spark, with added support for Apache Livy and Cloudera Data Engineering. The Open Data Lakehouse . Cloudera builds dbt adaptors for all engines in the open data lakehouse.
Data scientist is one of the hottest jobs in IT. Companies are increasingly eager to hire data professionals who can make sense of the wide array of data the business collects. Candidates for the exam are tested on ML, AI solutions, NLP, computer vision, and predictive analytics.
We also share a Spark benchmark solution that suits all Amazon EMR deployment options, so you can replicate the process in your environment for your own performance test cases. The solution uses the TPC-DS dataset and unmodified data schema and table relationships, but derives queries from TPC-DS to support the SparkSQL test cases.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing ETL (extract, transform, and load), business intelligence (BI), and reporting tools. All columns should masked for them.
To grow the power of data at scale for the long term, it’s highly recommended to design an end-to-end development lifecycle for your data integration pipelines. The following are common asks from our customers: Is it possible to develop and test AWS Glue data integration jobs on my local laptop?
Airflow has been adopted by many Cloudera Data Platform (CDP) customers in the public cloud as the next generation orchestration service to setup and operationalize complex data pipelines. Making the most commonly used as readily available as possible is critical to reduce development friction. .
Writing SQL queries requires not just remembering the SQL syntax rules, but also knowledge of the tables metadata, which is data about table schemas, relationships among the tables, and possible column values. As a result, the model used the correct column names and data types and restricted the DATE casting to a literal string value.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content