This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
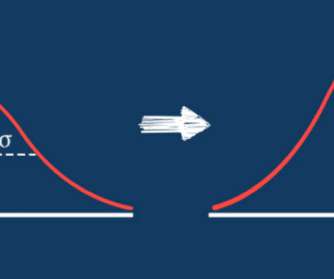
Increasing accuracy in your models is often obtained through the first steps of datatransformations. This guide explains the difference between the key feature scaling methods of standardization and normalization, and demonstrates when and how to apply each approach.
Introduction to Data Engineering In recent days the consignment of data produced from innumerable sources is drastically increasing day-to-day. So, processing and storing of these data has also become highly strenuous. The post Data Engineering – A Journal with Pragmatic Blueprint appeared first on Analytics Vidhya.
For years, IT and data leaders have been striving to help their companies become more data driven. But technology investment alone is not enough to make your organization data driven. I think that speaks volumes to the type of commitment that organizations have to make around data in order to actually move the needle.”.
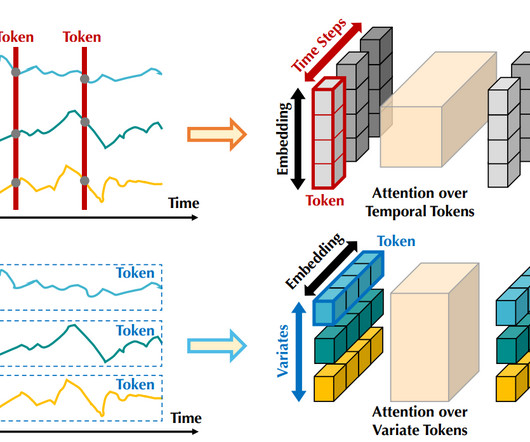
Introduction Transformers have revolutionized various domains of machinelearning, notably in natural language processing (NLP) and computer vision. Their ability to capture long-range dependencies and handle sequential data effectively has made them a staple in every AI researcher and practitioner’s toolbox.
At Atlanta’s Hartsfield-Jackson International Airport, an IT pilot has led to a wholesale data journey destined to transform operations at the world’s busiest airport, fueled by machinelearning and generative AI. They’re trying to get a handle on their data estate right now.
The following requirements were essential to decide for adopting a modern data mesh architecture: Domain-oriented ownership and data-as-a-product : EUROGATE aims to: Enable scalable and straightforward data sharing across organizational boundaries. Eliminate centralized bottlenecks and complex data pipelines.
Think about what the model results tell you: “Maybe a random forest isn’t the best tool to split this data, but XLNet is.” ” If none of your models performed well, that tells you that your dataset–your choice of raw data, feature selection, and feature engineering–is not amenable to machinelearning.
We live in a data-rich, insights-rich, and content-rich world. Data collections are the ones and zeroes that encode the actionable insights (patterns, trends, relationships) that we seek to extract from our data through machinelearning and data science. Source: [link] I will finish with three quotes.
This middleware consists of custom code that runs data flows to stitch datatransformations, search queries, and AI enrichments in varying combinations tailored to use cases, datasets, and requirements. Ingest flows are created to enrich data as its added to an index. Flows are a pipeline of processor resources.
Big Data is the Key to Hospital Management. Big data is changing the scope of hospital management. Healthcare providers are using machinelearning, predictive analytics and other big data technologies to trim costs and improve the quality of care. However, all big data solutions are not created equally.
Introduction Have you ever struggled with managing complex datatransformations? In today’s data-driven world, extracting, transforming, and loading (ETL) data is crucial for gaining valuable insights. While many ETL tools exist, dbt (data build tool) is emerging as a game-changer.
In the fast-evolving landscape of data science and machinelearning, efficiency is not just desirable—it’s essential. Imagine a world where every data practitioner, from seasoned data scientists to budding developers, has an intelligent assistant at their fingertips.
As per the TDWI survey, more than a third (nearly 37%) of people has shown dissatisfaction with their ability to access and integrate complex data streams. Why is Data Integration a Challenge for Enterprises? As complexities in big data increase each day, data integration is becoming a challenge.
Much has been written about struggles of deploying machinelearning projects to production. As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. However, the concept is quite abstract.
You can use it for big data analytics and machinelearning workloads. Azure Databricks Delta Live Table s: These provide a more straightforward way to build and manage Data Pipelines for the latest, high-quality data in Delta Lake. Azure Blob Storage serves as the data lake to store raw data.
How dbt Core aids data teams test, validate, and monitor complex datatransformations and conversions Photo by NASA on Unsplash Introduction dbt Core, an open-source framework for developing, testing, and documenting SQL-based datatransformations, has become a must-have tool for modern data teams as the complexity of data pipelines grows.
AI is transforming how senior data engineers and data scientists validate datatransformations and conversions. Artificial intelligence-based verification approaches aid in the detection of anomalies, the enforcement of data integrity, and the optimization of pipelines for improved efficiency.
The goal, she explained, is to knock down data silos between those groups, using multiple data lakes supported by strong security and governance, to drive positive impact across the supply chain, manufacturing, and the clinical trials of new drugs. . Four ways to improve data-driven business transformation .
Data quality rules are codified into structured Expectation Suites by Great Expectations instead of relying on ad-hoc scripts or manual checks. The framework ensures that your datatransformations comply with rigorous specifications from the moment they are created through every iteration of your pipeline.
Workiva also prioritized improving the data lifecycle of machinelearning models, which otherwise can be very time consuming for the team to monitor and deploy. GSK’s DataOps journey paralleled their datatransformation journey.
Managing tests of complex datatransformations when automated data testing tools lack important features? Photo by Marvin Meyer on Unsplash Introduction Datatransformations are at the core of modern business intelligence, blending and converting disparate datasets into coherent, reliable outputs.
Although CRISP-DM is not perfect , the CRISP-DM framework offers a pathway for machinelearning using AzureML for Microsoft Data Platform professionals. AI vs ML vs Data Science vs Business Intelligence. They may also learn from evidence, but the data and the modelling fundamentally comes from humans in some way.
The exam covers everything from fundamental to advanced data science concepts such as big data best practices, business strategies for data, building cross-organizational support, machinelearning, natural language processing, scholastic modeling, and more.
We speak a lot about the ways we can use data, transform it, and create powerful models based on advanced machinelearning techniques, but we sometimes forget where the data comes from initially.
How to Perform Motion Detection Using Python • The Complete Collection of Data Science Projects - Part 2 • What Does ETL Have to Do with MachineLearning? DataTransformation: Standardization vs Normalization • The Evolution From Artificial Intelligence to MachineLearning to Data Science.
Within seconds of transactional data being written into Amazon Aurora (a fully managed modern relational database service offering performance and high availability at scale), the data is seamlessly made available in Amazon Redshift for analytics and machinelearning.
In this post, well see the fundamental procedures, tools, and techniques that data engineers, data scientists, and QA/testing teams use to ensure high-quality data as soon as its deployed. First, we look at how unit and integration tests uncover transformation errors at an early stage.
ChatGPT> DataOps is a term that refers to the set of practices and tools that organizations use to improve the quality and speed of data analytics and machinelearning. It involves bringing together people, processes, and technology to enable data-driven decision making and improve the efficiency of data-related workflows.
Where DataOps fits Enterprises today are increasingly injecting machinelearning into a vast array of products and services and DataOps is an approach geared toward supporting the end-to-end needs of machinelearning. The DataOps approach is not limited to machinelearning,” they add.
This does away with the need for analysts to repeatedly perform data extraction, enrichment or transformation motions from the required source systems, all but eliminating the substantial amount of time analysts and business users spend routinely on data preparation.
Data analytics draws from a range of disciplines — including computer programming, mathematics, and statistics — to perform analysis on data in an effort to describe, predict, and improve performance. What are the four types of data analytics? Data analytics methods and techniques.
Taking the broadest possible interpretation of data analytics , Azure offers more than a dozen services — and that’s before you include Power BI, with its AI-powered analysis and new datamart option , or governance-oriented approaches such as Microsoft Purview. Azure Data Factory. Azure Synapse Analytics. Datamarts in Power BI.
What is the difference between business analytics and data analytics? Business analytics is a subset of data analytics. Data analytics is used across disciplines to find trends and solve problems using data mining , data cleansing, datatransformation, data modeling, and more.
When we announced the GA of Cloudera Data Engineering back in September of last year, a key vision we had was to simplify the automation of datatransformation pipelines at scale. Typically users need to ingest data, transform it into optimal format with quality checks, and optimize querying of the data by visual analytics tool.
Third, some services require you to set up and manage compute resources used for federated connectivity, and capabilities like connection testing and data preview arent available in all services. To solve for these challenges, we launched Amazon SageMaker Lakehouse unified data connectivity.
Secure storage, together with datatransformation, monitoring, auditing, and a compliance layer, increase the complexity of the system. AI projects can break budgets Because AI and machinelearning are data intensive, these projects can greatly increase cloud costs.
Build data validation rules directly into ingestion layers so that insufficient data is stopped at the gate and not detected after damage is done. Use lineage tooling to trace data from source to report. Understanding how datatransforms and where it breaks is crucial for audibility and root-cause resolution.
In the beginning, CDP ran only on AWS with a set of services that supported a handful of use cases and workload types: CDP Data Warehouse: a kubernetes-based service that allows business analysts to deploy data warehouses with secure, self-service access to enterprise data. Predict – Data Engineering (Apache Spark).
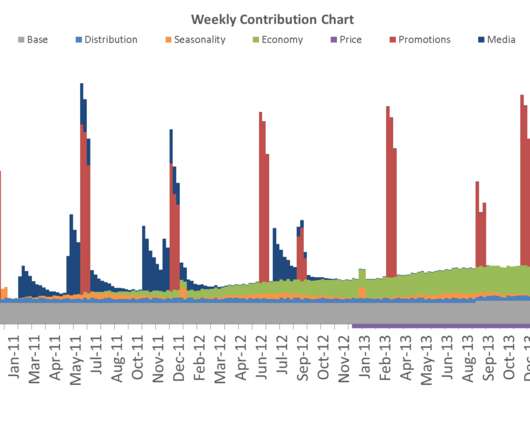
Before the data is put into the model comes a process called feature engineering – transforming the original data columns to impose certain business assumptions or simply increase model accuracy. The post Bringing MMM to 21st Century with MachineLearning and Automation? Want to See DataRobot in Action?
AWS Step Functions With AWS Step Functions, you can create workflows, also called State machines, to build distributed applications, automate processes, orchestrate microservices, and create data and machinelearning pipelines. The following Diagram 2 shows this workflow.
My vision is that I can give the keys to my businesses to manage their data and run their data on their own, as opposed to the Data & Tech team being at the center and helping them out,” says Iyengar, director of Data & Tech at Straumann Group North America. The company’s Findability.ai
OpenSearch Ingestion can ingest data from a wide variety of sources, such as Amazon Simple Storage Service (Amazon S3) buckets and HTTP endpoints, and has a rich ecosystem of built-in processors to take care of your most complex datatransformation needs.
We’re excited to announce the general availability of the open source adapters for dbt for all the engines in CDP — Apache Hive , Apache Impala , and Apache Spark, with added support for Apache Livy and Cloudera Data Engineering. The Open Data Lakehouse . Cloudera builds dbt adaptors for all engines in the open data lakehouse.
Features are input for machinelearning models. The most efficient way to use them across an organization is in a feature store that automates the datatransformations, stores them and makes them available for training and inference.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content