This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Much has been written about struggles of deploying machinelearning projects to production. As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. An Overarching Concern: Correctness and Testing.
At Atlanta’s Hartsfield-Jackson International Airport, an IT pilot has led to a wholesale data journey destined to transform operations at the world’s busiest airport, fueled by machinelearning and generative AI. They’re trying to get a handle on their data estate right now.
Think about what the model results tell you: “Maybe a random forest isn’t the best tool to split this data, but XLNet is.” ” If none of your models performed well, that tells you that your dataset–your choice of raw data, feature selection, and feature engineering–is not amenable to machinelearning.
Managing tests of complex datatransformations when automated datatesting tools lack important features? Photo by Marvin Meyer on Unsplash Introduction Datatransformations are at the core of modern business intelligence, blending and converting disparate datasets into coherent, reliable outputs.
Within seconds of transactional data being written into Amazon Aurora (a fully managed modern relational database service offering performance and high availability at scale), the data is seamlessly made available in Amazon Redshift for analytics and machinelearning. Choose Test Connection.
Purchase Ready-Made Big Data Solutions for Healthcare Applications. There is also a range of different data-driven solutions you can start using right now. Such products usually come with a standard set of tools, and you can test several of them to pick the best option. Big Data is the Key to Hospital Management.
GSK had been pursuing DataOps capabilities such as automation, containerization, automated testing and monitoring, and reusability, for several years. Workiva also prioritized improving the data lifecycle of machinelearning models, which otherwise can be very time consuming for the team to monitor and deploy.
In this post, well see the fundamental procedures, tools, and techniques that data engineers, data scientists, and QA/testing teams use to ensure high-quality data as soon as its deployed. First, we look at how unit and integration tests uncover transformation errors at an early stage. PyTest, JUnit,NUnit).
In the fast-evolving landscape of data science and machinelearning, efficiency is not just desirable—it’s essential. Imagine a world where every data practitioner, from seasoned data scientists to budding developers, has an intelligent assistant at their fingertips.
Although CRISP-DM is not perfect , the CRISP-DM framework offers a pathway for machinelearning using AzureML for Microsoft Data Platform professionals. AI vs ML vs Data Science vs Business Intelligence. They may also learn from evidence, but the data and the modelling fundamentally comes from humans in some way.
You can use it for big data analytics and machinelearning workloads. Azure Databricks Delta Live Table s: These provide a more straightforward way to build and manage Data Pipelines for the latest, high-quality data in Delta Lake. Azure Blob Storage serves as the data lake to store raw data.
The goal, she explained, is to knock down data silos between those groups, using multiple data lakes supported by strong security and governance, to drive positive impact across the supply chain, manufacturing, and the clinical trials of new drugs. . Four ways to improve data-driven business transformation .
How dbt Core aids data teams test, validate, and monitor complex datatransformations and conversions Photo by NASA on Unsplash Introduction dbt Core, an open-source framework for developing, testing, and documenting SQL-based datatransformations, has become a must-have tool for modern data teams as the complexity of data pipelines grows.
AI is transforming how senior data engineers and data scientists validate datatransformations and conversions. Artificial intelligence-based verification approaches aid in the detection of anomalies, the enforcement of data integrity, and the optimization of pipelines for improved efficiency.
How GX helps data teams validate, test, and monitor complex data pipelines Introduction Data flows from diverse sources, and transformations are becoming increasingly complex. Great Expectations can enable a wide range of datatransformations and conversion operations.
The exam tests general knowledge of the platform and applies to multiple roles, including administrator, developer, data analyst, data engineer, data scientist, and system architect. The exam is designed for seasoned and high-achiever data science thought and practice leaders.
Build data validation rules directly into ingestion layers so that insufficient data is stopped at the gate and not detected after damage is done. Use lineage tooling to trace data from source to report. Understanding how datatransforms and where it breaks is crucial for audibility and root-cause resolution.
Data analytics draws from a range of disciplines — including computer programming, mathematics, and statistics — to perform analysis on data in an effort to describe, predict, and improve performance. What are the four types of data analytics? Data analytics methods and techniques.
What is the difference between business analytics and data analytics? Business analytics is a subset of data analytics. Data analytics is used across disciplines to find trends and solve problems using data mining , data cleansing, datatransformation, data modeling, and more.
For each service, you need to learn the supported authorization and authentication methods, data access APIs, and framework to onboard and testdata sources. To solve for these challenges, we launched Amazon SageMaker Lakehouse unified data connectivity.
We’re excited to announce the general availability of the open source adapters for dbt for all the engines in CDP — Apache Hive , Apache Impala , and Apache Spark, with added support for Apache Livy and Cloudera Data Engineering. This variety can result in a lack of standardization, leading to data duplication and inconsistency.
In the beginning, CDP ran only on AWS with a set of services that supported a handful of use cases and workload types: CDP Data Warehouse: a kubernetes-based service that allows business analysts to deploy data warehouses with secure, self-service access to enterprise data. Predict – Data Engineering (Apache Spark).
AI and machinelearning (ML) are not just catchy buzzwords; they’re vital to the future of our planet and your business. Doing it right can mean the difference between thriving in the new world of data and disappearing from it. Be sure test cases represent the diversity of app users. Can a chatbot help improve relations?
Our approach The migration initiative consisted of two main parts: building the new architecture and migrating data pipelines from the existing tool to the new architecture. Often, we would work on both in parallel, testing one component of the architecture while developing another at the same time.
Airflow has been adopted by many Cloudera Data Platform (CDP) customers in the public cloud as the next generation orchestration service to setup and operationalize complex data pipelines. With this Technical Preview release, any CDE customer can test drive the new authoring interface by setting up the latest CDE service.
Once released, consumers use datasets from different providers for analysis, machinelearning (ML) workloads, and visualization. Each CDH dataset has three processing layers: source (raw data), prepared (transformeddata in Parquet), and semantic (combined datasets).
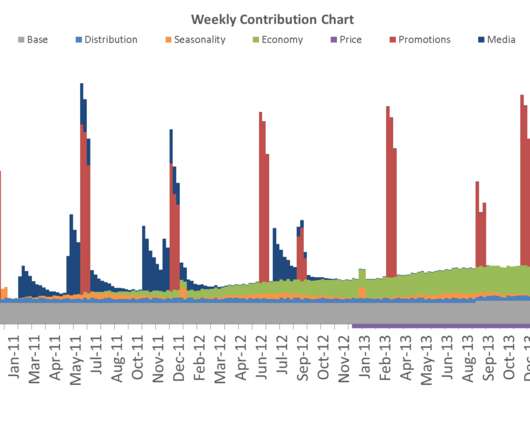
Before the data is put into the model comes a process called feature engineering – transforming the original data columns to impose certain business assumptions or simply increase model accuracy. The classical approach is to assume the adstock function (typically linear ) and test out various values of ? Request a demo.
In addition to using native managed AWS services that BMS didn’t need to worry about upgrading, BMS was looking to offer an ETL service to non-technical business users that could visually compose datatransformation workflows and seamlessly run them on the AWS Glue Apache Spark-based serverless data integration engine.
Today’s general availability announcement covers Iceberg running within key data services in the Cloudera Data Platform (CDP) — including Cloudera Data Warehousing ( CDW ), Cloudera Data Engineering ( CDE ), and Cloudera MachineLearning ( CML ). Read why the future of data lakehouses is open.
Continuing from my previous blog post about how awesome and easy it is to develop web-based applications backed by Cloudera Operational Database (COD), I started a small project to integrate COD with another CDP cloud experience, Cloudera MachineLearning (CML). . Now, let’s start testing our model! Go to runner.py
Also, you can run other types of business applications, such as web applications and machinelearning (ML) TensorFlow workloads, on the same EKS cluster. We also share a Spark benchmark solution that suits all Amazon EMR deployment options, so you can replicate the process in your environment for your own performance test cases.
The advent of rapid adoption of serverless data lake architectures—with ever-growing datasets that need to be ingested from a variety of sources, followed by complex datatransformation and machinelearning (ML) pipelines—can present a challenge. Disable the rules after testing to avoid repeated messages.
Modak Nabu relies on a framework of “Botworks”, a series of micro-jobs to accomplish various datatransformation steps from ingestion to profiling, and indexing. Cloudera Data Engineering within CDP provides : Fully managed Spark-on-Kubernetes service that hides the complexity running production DE workloads at scale.
The general availability covers Iceberg running within some of the key data services in CDP, including Cloudera Data Warehouse ( CDW ), Cloudera Data Engineering ( CDE ), and Cloudera MachineLearning ( CML ). Cloudera Data Engineering (Spark 3) with Airflow enabled. Cloudera MachineLearning .
Apache Spark unifies batch processing, real-time processing, stream analytics, machinelearning, and interactive query in one-platform. The Test and Development queue have fixed resource limits. Background. Why choose K8s for Apache Spark. All other queues are only limited by the size of the cluster. Acknowledgments.
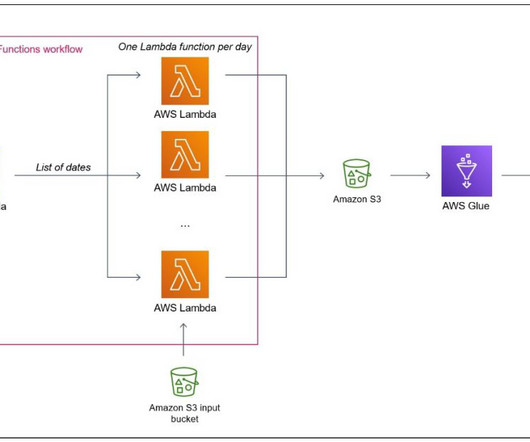
It has not been specifically designed for heavy datatransformation tasks. Step Functions helps developers use AWS services to build distributed applications, automate processes, orchestrate microservices, and create data and machinelearning (ML) pipelines. Note that Lambda is a general purpose serverless engine.
Amazon Redshift is used to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes. Amazon EMR provides a big data environment for data processing, interactive analysis, and machinelearning using open source frameworks such as Apache Spark, Apache Hive, and Presto.
Datatransforms businesses. That’s where the data lifecycle comes into play. Managing data and its flow, from the edge to the cloud, is one of the most important tasks in the process of gaining data intelligence. .
Migrating to Amazon Redshift offers organizations the potential for improved price-performance, enhanced data processing, faster query response times, and better integration with technologies such as machinelearning (ML) and artificial intelligence (AI). Platform architects define a well-architected platform.
To grow the power of data at scale for the long term, it’s highly recommended to design an end-to-end development lifecycle for your data integration pipelines. The following are common asks from our customers: Is it possible to develop and test AWS Glue data integration jobs on my local laptop?
According to Evanta’s 2022 CIO Leadership Perspectives study, CIOs’ second top priority within the IT function is around data and analytics, with CIOs seeing advancing organizational use of data as key to reaching enterprise objectives. Others also list data initiatives as a top issue for CIOs.
To accomplish this interchange, the method uses data mining and machinelearning and it contains components like a data dictionary to define the fields used by the model, and datatransformation to map user data and make it easier for the system to mine that data. Validation summary of models.
They use various AWS analytics services, such as Amazon EMR, to enable their analysts and data scientists to apply advanced analytics techniques to interactively develop and test new surveillance patterns and improve investor protection. Melody Yang is a Senior Big Data Solutions Architect for Amazon EMR at AWS.
Many thanks to AWP Pearson for the permission to excerpt “Manual Feature Engineering: Manipulating Data for Fun and Profit” from the book, MachineLearning with Python for Everyone by Mark E. Missing values can be filled in based on expert knowledge, heuristics, or by some machinelearning techniques.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content