This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
1) What Is Data Quality Management? 4) Data Quality Best Practices. 5) How Do You Measure Data Quality? 6) Data Quality Metrics Examples. 7) Data Quality Control: Use Case. 8) The Consequences Of Bad Data Quality. 9) 3 Sources Of Low-Quality Data. 10) Data Quality Solutions: Key Attributes.
The need for streamlined datatransformations As organizations increasingly adopt cloud-based data lakes and warehouses, the demand for efficient datatransformation tools has grown. This approach helps in managing storage costs while maintaining the flexibility to analyze historical trends when needed.
Together with price-performance, Amazon Redshift offers capabilities such as serverless architecture, machine learning integration within your data warehouse and secure data sharing across the organization. dbt Cloud is a hosted service that helps data teams productionize dbt deployments. Choose Test Connection.
Jon Pruitt, director of IT at Hartsfield-Jackson Atlanta International Airport, and his team crafted a visual business intelligence dashboard for a top executive in its Emergency Response Team to provide key metrics at a glance, including weather status, terminal occupancy, concessions operations, and parking capacity.
Co-author: Mike Godwin, Head of Marketing, Rill Data. Cloudera has partnered with Rill Data, an expert in metrics at any scale, as Cloudera’s preferred ISV partner to provide technical expertise and support services for Apache Druid customers. Deploying metrics shouldn’t be so hard. Cloudera Data Warehouse).
AI is transforming how senior data engineers and data scientists validate datatransformations and conversions. Artificial intelligence-based verification approaches aid in the detection of anomalies, the enforcement of data integrity, and the optimization of pipelines for improved efficiency.
Extrinsic Control Deficit: Many of these changes stem from tools and processes beyond the immediate control of the data team. Unregulated ETL/ELT Processes: The absence of stringent data quality tests in ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) processes further exacerbates the problem.
Upload your data, click through a workflow, walk away. If you’re a professional data scientist, you already have the knowledge and skills to test these models. Get your results in a few hours. Why would you want autoML to build models for you? It buys time and breathing room. It does not exist in the code.
The data organization wants to run the Value Pipeline as robustly as a six sigma factory, and it must be able to implement and deploy process improvements as rapidly as a Silicon Valley start-up. The data engineer builds datatransformations. Their product is the data. Create tests. Run the factory.
Here are a few examples that we have seen of how this can be done: Batch ETL with Azure Data Factory and Azure Databricks: In this pattern, Azure Data Factory is used to orchestrate and schedule batch ETL processes. Azure Blob Storage serves as the data lake to store raw data. Azure Machine Learning).
What is the difference between business analytics and data analytics? Business analytics is a subset of data analytics. Data analytics is used across disciplines to find trends and solve problems using data mining , data cleansing, datatransformation, data modeling, and more.
If you can show ROI on a DW it would be a good use of your money to go with Omniture Discover, WebTrends Data Mart, Coremetrics Explore. If you have evolved to a stage that you need behavior targeting then get Omniture Test and Target or Sitespect. Mongoose Metrics ~ ifbyphone. Five Reasons And Awesome Testing Ideas.
However, you might face significant challenges when planning for a large-scale data warehouse migration. The success criteria are the key performance indicators (KPIs) for each component of the data workflow. This will enable right-sizing the Redshift data warehouse to meet workload demands cost-effectively.
Photo by CDC on Unsplash Many data pipeline failures and quality issues that are detected by data observability tools in production could have been prevented earlier in the pipeline lifecycle with better pre-production testing strategies. Helps identify transformation errors, and data quality issues early, minimizing risks.
A modern data platform entails maintaining data across multiple layers, targeting diverse platform capabilities like high performance, ease of development, cost-effectiveness, and DataOps features such as CI/CD, lineage, and unit testing. It does this by helping teams handle the T in ETL (extract, transform, and load) processes.
The advent of rapid adoption of serverless data lake architectures—with ever-growing datasets that need to be ingested from a variety of sources, followed by complex datatransformation and machine learning (ML) pipelines—can present a challenge. Disable the rules after testing to avoid repeated messages.
The goal of DataOps Observability is to provide visibility of every journey that data takes from source to customer value across every tool, environment, data store, data and analytic team, and customer so that problems are detected, localized and raised immediately. A data journey spans and tracks multiple pipelines.
In this post, we discuss ways to modernize your legacy, on-premises, real-time analytics architecture to build serverless data analytics solutions on AWS using Amazon Managed Service for Apache Flink. Near-real-time streaming analytics captures the value of operational data and metrics to provide new insights to create business opportunities.
AWS offers Redshift Test Drive to validate whether the configuration chosen for Amazon Redshift is ideal for your workload before migrating the production environment. At this point, only one-time queries and those made by Amazon QuickSight reached the new cluster. We removed the DC2 cluster and completed the migration.
Datatransformation plays a pivotal role in providing the necessary data insights for businesses in any organization, small and large. To gain these insights, customers often perform ETL (extract, transform, and load) jobs from their source systems and output an enriched dataset.
Allows them to iteratively develop processing logic and test with as little overhead as possible. Plays nice with existing CI/CD processes to promote a data pipeline to production. Provides monitoring, alerting, and troubleshooting for production data pipelines.
An obvious mechanical answer is: use relevance as a metric. Another important method is to benchmark existing metrics. Know the limitations of your existing dataset and answer these questions: What categories of data are there? Be sure test cases represent the diversity of app users. Can a chatbot help improve relations?
Kinesis Data Firehose is a fully managed service for delivering near-real-time streaming data to various destinations for storage and performing near-real-time analytics. You can perform analytics on VPC flow logs delivered from your VPC using the Kinesis Data Firehose integration with Datadog as a destination.
Each CDH dataset has three processing layers: source (raw data), prepared (transformeddata in Parquet), and semantic (combined datasets). It is possible to define stages (DEV, INT, PROD) in each layer to allow structured release and test without affecting PROD.
You simply configure your data sources to send information to OpenSearch Ingestion, which then automatically delivers the data to your specified destination. Additionally, you can configure OpenSearch Ingestion to apply datatransformations before delivery. Choose the Test tab. For Method type ¸ choose POST.
Detailed Data and Model Lineage Tracking*: Ensures comprehensive tracking and documentation of datatransformations and model lifecycle events, enhancing reproducibility and auditability.
Alation is pleased to be named a dbt Metrics Partner and to announce the start of a partnership with dbt, which will bring dbt data into the Alation data catalog. In the modern data stack, dbt is a key tool to make data ready for analysis. DataTransformation in the Modern Data Stack.
Let’s look at some key metrics. After analyzing YARN logs by various metrics, you’re ready to design future EMR architectures. Clean up After you complete all the steps and finish testing, complete the following steps to delete resources to avoid incurring costs: On the AWS CloudFormation console, choose the stack you created.
Few actors in the modern data stack have inspired the enthusiasm and fervent support as dbt. This datatransformation tool enables data analysts and engineers to transform, test and document data in the cloud data warehouse. But what does this mean from a practitioner perspective?
Tricentis is the global leader in continuous testing for DevOps, cloud, and enterprise applications. Speed changes everything, and continuous testing across the entire CI/CD lifecycle is the key. Tricentis instills that confidence by providing software tools that enable Agile Continuous Testing (ACT) at scale.
Within a large enterprise, there is a huge amount of data accumulated over the years – many decisions have been made and different methods have been tested. They have different metrics for judging whether some content is interesting or not. This is one of the main diagnostic tests.
DataBrew is a visual data preparation tool that enables you to clean and normalize data without writing any code. The over 200 transformations it provides are now available to be used in an AWS Glue Studio visual job. On the Runs tab, you can keep track of the process and see detailed job metrics using the job ID link.
We use Apache Spark as our main data processing engine and have over 1,000 Spark applications running over massive amounts of data every day. These Spark applications implement our business logic ranging from datatransformation, machine learning (ML) model inference, to operational tasks. Their costs were climbing.
The first step in building a model that can predict machine failure and even recommend the next best course of action is to aggregate, clean, and prepare data to train against. This task may require complex joins, aggregations, filtering, window functions, and many other datatransformations against extremely large-scale data sets.
This, in turn, empowers data leaders to better identify and develop new revenue streams, customize patient offerings, and use data to optimize operations. To make good on this potential, healthcare organizations need to understand their data and how they can use it. Why Is Data Governance in Healthcare Important?
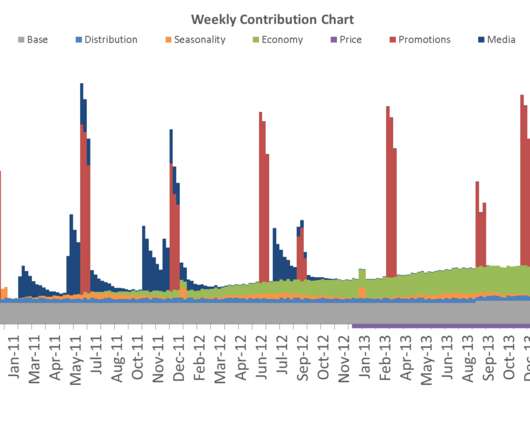
Media data (usually weekly): media costs, media ratings generated (TVRs, magazine copies, digital impressions, likes, shares, etc.), The standard practice is that the data should be aggregated into a weekly format and span at least the last two to three years (ideally around five years). Classical Modeling Considerations.
GSK had been pursuing DataOps capabilities such as automation, containerization, automated testing and monitoring, and reusability, for several years. DataOps provides the “continuous delivery equivalent for Machine Learning and enables teams to manage the complexities around continuous training, A/B testing, and deploying without downtime.
dbt is an open source, SQL-first templating engine that allows you to write repeatable and extensible datatransforms in Python and SQL. dbt is predominantly used by data warehouses (such as Amazon Redshift ) customers who are looking to keep their datatransform logic separate from storage and engine.
The data products from the Business Vault and Data Mart stages are now available for consumers. smava decided to use Tableau for business intelligence, data visualization, and further analytics. The datatransformations are managed with dbt to simplify the workflow governance and team collaboration.
Conduct data quality tests on anonymized data in compliance with data policies Conduct data quality tests to quickly identify and address data quality issues, maintaining high-quality data at all times. The challenge Data quality tests require performing 1,300 tests on 10 TB of data monthly.
If data mapping has been enabled within the data processing job, then the structured data is prepared based on the given schema. This output is passed to next phase where datatransformations and business validations can be applied. After this step, data is loaded to specified target.
DataOps Observability includes monitoring and testing the data pipeline, data quality, datatesting, and alerting. Datatesting is an essential aspect of DataOps Observability; it helps to ensure that data is accurate, complete, and consistent with its specifications, documentation, and end-user requirements.
As a result, end users can better view shared metrics (backed by accurate data), which ultimately drives performance. When treating a patient, a doctor may wish to study the patient’s vital metrics in comparison to those of their peer group. Visual Analytics Users are given data from which they can uncover new insights.
Tableaus certifications, in particular, focus on performance-based testing rather than theory in an effort to verify a candidates ability to apply the subject matter in a real work environment. The Tableau Certified Data Analyst title is active for two years from the date achieved. The certification does not expire.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content