This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Let’s start by considering the job of a non-ML software engineer: writing traditional software deals with well-defined, narrowly-scoped inputs, which the engineer can exhaustively and cleanly model in the code. Not only is data larger, but models—deep learning models in particular—are much larger than before.
” I, thankfully, learned this early in my career, at a time when I could still refer to myself as a software developer. Given that, what would you say is the job of a data scientist (or ML engineer, or any other such title)? Building Models. A common task for a data scientist is to build a predictive model.
Finally, we can use Amazon SageMaker to build forecasting models that can predict inventory demand and optimize stock levels. ElastiCache manages the real-time application data caching, allowing your customers to experience microsecond response times while supporting high-throughput handling of hundreds of millions of operations per second.
Writing SQL queries requires not just remembering the SQL syntax rules, but also knowledge of the tables metadata, which is data about table schemas, relationships among the tables, and possible column values. Generative AI models can translate natural language questions into valid SQL queries, a capability known as text-to-SQL generation.
Reporting being part of an effective DQM, we will also go through some data quality metrics examples you can use to assess your efforts in the matter. But first, let’s define what data quality actually is. What is the definition of data quality? Why Do You Need Data Quality Management? 2 – Data profiling.
Together with price-performance, Amazon Redshift offers capabilities such as serverless architecture, machine learning integration within your data warehouse and secure data sharing across the organization. dbt Cloud is a hosted service that helps data teams productionize dbt deployments. Create dbt models in dbt Cloud.
Amazon Redshift has launched a session reuse capability for the Data API that can significantly streamline multi-step, stateful workloads such as exchange, transform, and load (ETL) pipelines, reporting processes, and other flows that involve sequential queries. Please refer to Redshift Quotas and Limits here.
AI is transforming how senior data engineers and data scientists validate datatransformations and conversions. Artificial intelligence-based verification approaches aid in the detection of anomalies, the enforcement of data integrity, and the optimization of pipelines for improved efficiency.
You can’t talk about data analytics without talking about datamodeling. The reasons for this are simple: Before you can start analyzing data, huge datasets like data lakes must be modeled or transformed to be usable. Building the right datamodel is an important part of your data strategy.
The goal of DataOps is to help organizations make better use of their data to drive business decisions and improve outcomes. ChatGPT> DataOps is a term that refers to the set of practices and tools that organizations use to improve the quality and speed of data analytics and machine learning.
dbt is an open source, SQL-first templating engine that allows you to write repeatable and extensible datatransforms in Python and SQL. dbt is predominantly used by data warehouses (such as Amazon Redshift ) customers who are looking to keep their datatransform logic separate from storage and engine.
Einstein Copilot for Tableau remains in beta, but Tableau announced two new features for the AI assistant as well: AI-assisted datatransformation. This feature can automate a datatransformation pipeline with step-by-step suggestions for preparing data for analysis.
However, this partnership model cannot keep pace with an always-changing technology landscape in which the skill gaps and lack of resources are increasing. The new models recognise this, drawing tech vendors to shift toward innovation-focused roles and become partners in the client’s success.
For more information on this foundation, refer to A Detailed Overview of the Cost Intelligence Dashboard. Additionally, it manages table definitions in the AWS Glue Data Catalog , containing references to data sources and targets of extract, transform, and load (ETL) jobs in AWS Glue.
The Cloud Data Hub processes and combines anonymized data from vehicle sensors and other sources across the enterprise to make it easily accessible for internal teams creating customer-facing and internal applications. To learn more about the Cloud Data Hub, refer to BMW Group Uses AWS-Based Data Lake to Unlock the Power of Data.
AI governance refers to the practice of directing, managing and monitoring an organization’s AI activities. It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. Foundation models can use language, vision and more to affect the real world.
Taking the broadest possible interpretation of data analytics , Azure offers more than a dozen services — and that’s before you include Power BI, with its AI-powered analysis and new datamart option , or governance-oriented approaches such as Microsoft Purview. Azure Data Factory. Azure Synapse Analytics. Analytics, Microsoft Azure
Traditionally, such a legacy call center analytics platform would be built on a relational database that stores data from streaming sources. Datatransformations through stored procedures and use of materialized views to curate datasets and generate insights is a known pattern with relational databases.
Amazon Redshift ML is a feature of Amazon Redshift that enables you to build, train, and deploy machine learning (ML) models directly within the Redshift environment. Generative AI models can derive new features from your data and enhance decision-making. Create a materialized view to load the raw streaming data.
As with all AWS services, Amazon Redshift is a customer-obsessed service that recognizes there isn’t a one-size-fits-all for customers when it comes to datamodels, which is why Amazon Redshift supports multiple datamodels such as Star Schemas, Snowflake Schemas and Data Vault. Data Vault 2.0
Efficient data integration – AWS Glue simplifies the ETL process, providing a scalable and flexible solution for data integration between Snowflake and Amazon S3. Scalability and flexibility – The architecture supports scalable data transfers and can be extended to integrate additional data sources and destinations as needed.
We set up our AWS CDK to refer to the contents of a specific directory and define a resource (for example, an AWS Step Functions state machine or an AWS Glue job) for each file it found in that directory. We also used it as a repository for storing code that could be retrieved and used by other services.
For full instructions, refer to Jira Cloud connector for Amazon AppFlow. You can do this by updating the CloudFormation stack with a flag that includes the CDC and datatransformation steps. This will enable both the CDC steps and the datatransformation steps for the Jira data. Choose Update.
Operationalizing machine learning (ML) is another growing use case, where data has to be transformed and normalized before it can be loaded into an ML model. In both use cases, the data pipeline is preparing the data for consumption by ingesting data from different sources and transforming it through a series of steps.
If storing operational data in a data warehouse is a requirement, synchronization of tables between operational data stores and Amazon Redshift tables is supported. In scenarios where datatransformation is required, you can use Redshift stored procedures to modify data in Redshift tables.
Under the Transparency in Coverage (TCR) rule , hospitals and payors to publish their pricing data in a machine-readable format. For more information, refer to Delivering Consumer-friendly Healthcare Transparency in Coverage On AWS. The Data Catalog now contains references to the machine-readable data.
Encounter 4 appears to refer to the customer with ID 8, but the email doesn’t match, and no Customer_ID is given. A knowledge graph allows us to combine data from different sources to gain a better understanding of a specific problem domain. With the AWS SDK for Pandas, we combine this data by running a query against the Neptune graph.
In legacy analytical systems such as enterprise data warehouses, the scalability challenges of a system were primarily associated with computational scalability, i.e., the ability of a data platform to handle larger volumes of data in an agile and cost-efficient way. As a result, alternative data integration technologies (e.g.,
You can modify the Lambda function to fetch additional vehicle information from a separate data store (for example, a DynamoDB table or a Customer Relationship Management system) to enrich the data, before storing the results in an S3 bucket. In this model, the Lambda function is invoked for each incoming event.
OpenSearch Service also has vector database capabilities that let you implement semantic search and Retrieval Augmented Generation (RAG) with large language models (LLMs) to build recommendation and media search engines. For setup instructions, refer to Getting started with Amazon OpenSearch Service.
However, in this initial article, I wanted to to focus on one tool that I have used as part of my Data Strategy engagements; a Data Maturity Model. I used to talk about carrying out a Situational Analysis of Data Capabilities, nowadays I am more likely to refer to a Data Capability Review.
To populate the database, the Infomedia team developed a data pipeline using Amazon Simple Storage Service (Amazon S3) for data storage, AWS Glue for datatransformations, and Apache Hudi for CDC and record-level updates.
A source of unpredictable workloads is dbt Cloud , which SafetyCulture uses to manage datatransformations in the form of models. Whenever models are created or modified, a dbt Cloud CI job is triggered to test the models by materializing the models in Amazon Redshift.
AWS Glue Studio is a graphical interface that makes it easy to create, run, and monitor extract, transform, and load (ETL) jobs in AWS Glue. It allows you to visually compose datatransformation workflows using nodes that represent different data handling steps, which later are converted automatically into code to run.
In our last blog , we delved into the seven most prevalent data challenges that can be addressed with effective data governance. Today we will share our approach to developing a data governance program to drive datatransformation and fuel a data-driven culture.
In this post, I’ll walk you through how to copy data from one Amazon Relational Database Service (Amazon RDS) for PostgreSQL database to another, while scrubbing PII along the way using AWS Glue. Built-in datatransformations then scrub columns containing PII using pre-defined masking functions. PII detection and scrubbing.
Feature engineering is useful for data scientists when assessing tradeoff decisions regarding the impact of their ML models. It is a framework for approaching ML as well as providing techniques for extracting features from raw data that can be used within the models. Feature Engineering Terminology and Motivation.
A data warehouse stores transactional level details and serves the broader reporting and analytical needs of an organization – creating one source of truth for building semantic models or serving structured, simplified and harmonized data to tools like Power BI, Excel or even SSRS.
By preserving historical versions, data lake time travel provides benefits such as auditing and compliance, data recovery and rollback, reproducible analysis, and data exploration at different points in time. Another popular transaction data lake use case is incremental query. Make sure you are in the us-east-1 Region.
However, you might face significant challenges when planning for a large-scale data warehouse migration. For an example, refer to How JPMorgan Chase built a data mesh architecture to drive significant value to enhance their enterprise data platform. Platform architects define a well-architected platform.
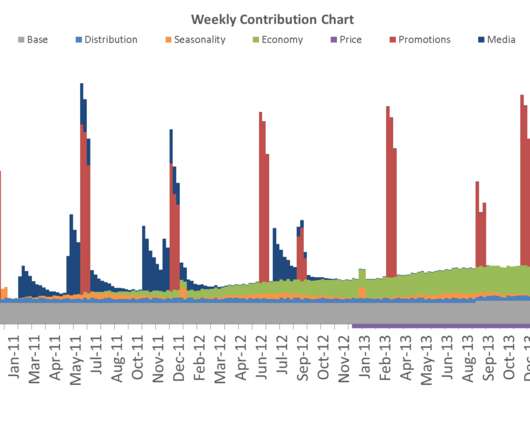
MMM stands for Marketing Mix Model and it is one of the oldest and most well-established techniques to measure the sales impact of marketing activity statistically. Data Requirements. As with any type of statistical model, data is key and GIGO (“Garbage In, Garbage Out”) principle definitely applies. What is MMM?
Datatransformation plays a pivotal role in providing the necessary data insights for businesses in any organization, small and large. To gain these insights, customers often perform ETL (extract, transform, and load) jobs from their source systems and output an enriched dataset.
The solution is choosing one of the standard provenance models. Standard provenance models Graph Replace is probably the most straightforward model. Trade-offs of the standard provenance models Graph Replace is fast and simple to implement and we recommend it to people with batch updates. Persistent or non-persistent IDs?
The following AWS services are used for data ingestion, processing, and load: Amazon AppFlow is a fully managed integration service that enables you to securely transfer data between SaaS applications like Salesforce, SAP, Marketo, Slack, and ServiceNow, and AWS services like Amazon S3 and Amazon Redshift , in just a few clicks.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content