This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Accurately predicting demand for products allows businesses to optimize inventory levels, minimize stockouts, and reduce holding costs. Solution overview In today’s highly competitive business landscape, it’s essential for retailers to optimize their inventory management processes to maximize profitability and improve customer satisfaction.
Maintaining reusable database sessions to help optimize the use of database connections, preventing the API server from exhausting the available connections and improving overall system scalability. Please refer to Redshift Quotas and Limits here. After 24 hours the session is forcibly closed, and in-progress queries are terminated.
This new JDBC connectivity feature enables our governed data to flow seamlessly into these tools, supporting productivity across our teams.” Use case Amazon DataZone addresses your data sharing challenges and optimizesdata availability.
but to reference concrete tooling used today in order to ground what could otherwise be a somewhat abstract exercise. Adapted from the book Effective Data Science Infrastructure. However, none of these layers help with modeling and optimization. Let’s now take a tour of the various layers, to begin to map the territory.
With Amazon AppFlow, you can run data flows at nearly any scale and at the frequency you chooseon a schedule, in response to a business event, or on demand. You can configure datatransformation capabilities such as filtering and validation to generate rich, ready-to-use data as part of the flow itself, without additional steps.
Reporting being part of an effective DQM, we will also go through some data quality metrics examples you can use to assess your efforts in the matter. But first, let’s define what data quality actually is. What is the definition of data quality? Why Do You Need Data Quality Management? date, month, and year).
Common challenges and practical mitigation strategies for reliable datatransformations. Photo by Mika Baumeister on Unsplash Introduction Datatransformations are important processes in data engineering, enabling organizations to structure, enrich, and integrate data for analytics , reporting, and operational decision-making.
AI is transforming how senior data engineers and data scientists validate datatransformations and conversions. Artificial intelligence-based verification approaches aid in the detection of anomalies, the enforcement of data integrity, and the optimization of pipelines for improved efficiency.
Adding datatransformation details to metadata can be challenging because of the dispersed nature of this information across data processing pipelines, making it difficult to extract and incorporate into table-level metadata. Enriching the prompt You can enhance the prompts with query optimization rules like partition pruning.
Data lakes provide a centralized repository for data from various sources, enabling organizations to unlock valuable insights and drive data-driven decision-making. However, as data volumes continue to grow, optimizingdata layout and organization becomes crucial for efficient querying and analysis.
The goal of DataOps is to help organizations make better use of their data to drive business decisions and improve outcomes. ChatGPT> DataOps is a term that refers to the set of practices and tools that organizations use to improve the quality and speed of data analytics and machine learning.
BMW Group uses 4,500 AWS Cloud accounts across the entire organization but is faced with the challenge of reducing unnecessary costs, optimizing spend, and having a central place to monitor costs. For more information on this foundation, refer to A Detailed Overview of the Cost Intelligence Dashboard.
Together with price-performance, Amazon Redshift offers capabilities such as serverless architecture, machine learning integration within your data warehouse and secure data sharing across the organization. dbt Cloud is a hosted service that helps data teams productionize dbt deployments.
If you want deeper control over your infrastructure for cost and latency optimization, you can choose OpenSearch Service’s managed clusters deployment option. With managed clusters, you get granular control over the instances you would like to use, indexing and data-sharding strategy, and more.
With auto-copy, automation enhances the COPY command by adding jobs for automatic ingestion of data. If storing operational data in a data warehouse is a requirement, synchronization of tables between operational data stores and Amazon Redshift tables is supported.
Notably, a partner with global reach can be particularly valuable to an organisation with operations with a global presence; since the structure of most multinational organisations is optimised to support their core business rather than initiatives like digital transformation.
Data Vault 2.0 allows for the following: Agile data warehouse development Parallel data ingestion A scalable approach to handle multiple data sources even on the same entity A high level of automation Historization Full lineage support However, Data Vault 2.0
In this post, we explore how AWS Glue can serve as the data integration service to bring the data from Snowflake for your data integration strategy, enabling you to harness the power of your data ecosystem and drive meaningful outcomes across various use cases. Store the extracted and transformeddata in Amazon S3.
However, you might face significant challenges when planning for a large-scale data warehouse migration. This includes the ETL processes that capture source data, the functional refinement and creation of data products, the aggregation for business metrics, and the consumption from analytics, business intelligence (BI), and ML.
Additionally, a TCO calculator generates the TCO estimation of an optimized EMR cluster for facilitating the migration. For more details on how to configure and schedule the log collector, refer to the yarn-log-collector GitHub repo. For more information on how to use the YARN log organizer, refer to the yarn-log-organizer GitHub repo.
With these settings, you can now seamlessly ingest decompressed CloudWatch log data into Splunk using Firehose. This enables you to run high-performance, cost-efficient analytics on streaming data in Amazon S3 using services such as Amazon Athena , Amazon EMR , Amazon Redshift Spectrum , and Amazon QuickSight.
dbt is an open source, SQL-first templating engine that allows you to write repeatable and extensible datatransforms in Python and SQL. dbt is predominantly used by data warehouses (such as Amazon Redshift ) customers who are looking to keep their datatransform logic separate from storage and engine.
Oracle GoldenGate for Oracle Database and Big Data adapters Oracle GoldenGate is a real-time data integration and replication tool used for disaster recovery, data migrations, high availability. You can use temporary credentials; for more details, refer to Using temporary credentials with AWS resources.
AWS Glue is a serverless data discovery, load, and transformation service that will prepare data for consumption in BI and AI/ML activities. Solution overview This solution uses Amazon AppFlow to retrieve data from the Jira Cloud. For full instructions, refer to Jira Cloud connector for Amazon AppFlow.
We set up our AWS CDK to refer to the contents of a specific directory and define a resource (for example, an AWS Step Functions state machine or an AWS Glue job) for each file it found in that directory. We also used it as a repository for storing code that could be retrieved and used by other services.
In this post, we provide a detailed overview of streaming messages with Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon ElastiCache for Redis , covering technical aspects and design considerations that are essential for achieving optimal results. We also discuss the key features, considerations, and design of the solution.
If you can’t make sense of your business data, you’re effectively flying blind. Insights hidden in your data are essential for optimizing business operations, finetuning your customer experience, and developing new products — or new lines of business, like predictive maintenance. Azure Data Factory.
It supports modern analytical data lake operations such as create table as select (CTAS), upsert and merge, and time travel queries. Athena also supports the ability to create views and perform VACUUM (snapshot expiration) on Apache Iceberg tables to optimize storage and performance.
Under the Transparency in Coverage (TCR) rule , hospitals and payors to publish their pricing data in a machine-readable format. For more information, refer to Delivering Consumer-friendly Healthcare Transparency in Coverage On AWS. The Data Catalog now contains references to the machine-readable data.
Infomedia was looking to build a cloud-based data platform to take advantage of highly scalable data storage with flexible and cloud-native processing tools to ingest, transform, and deliver datasets to their SaaS applications. The raw input data is stored in Amazon S3 in JSON format (called the bronze dataset layer).
Datatransformation plays a pivotal role in providing the necessary data insights for businesses in any organization, small and large. To gain these insights, customers often perform ETL (extract, transform, and load) jobs from their source systems and output an enriched dataset.
Stored procedures are commonly used to encapsulate logic for datatransformation, data validation, and business-specific logic. You can also schedule stored procedures to automate data processing on Amazon Redshift. For more information, refer to Bringing your stored procedures to Amazon Redshift.
Furthermore, it allows for necessary actions to be taken, such as rectifying errors in the data source, refining datatransformation processes, and updating data quality rules. This automated approach reduces the need for manual intervention and streamlines the data quality evaluation process.
By preserving historical versions, data lake time travel provides benefits such as auditing and compliance, data recovery and rollback, reproducible analysis, and data exploration at different points in time. Another popular transaction data lake use case is incremental query.
In addition, more data is becoming available for processing / enrichment of existing and new use cases e.g., recently we have experienced a rapid growth in data collection at the edge and an increase in availability of frameworks for processing that data. As a result, alternative data integration technologies (e.g.,
Amazon Redshift enables you to use SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and machine learning (ML) to deliver the best price-performance at scale. Shashank Tewari is a Senior Technical Account Manager at AWS.
AWS Glue Studio is a graphical interface that makes it easy to create, run, and monitor extract, transform, and load (ETL) jobs in AWS Glue. It allows you to visually compose datatransformation workflows using nodes that represent different data handling steps, which later are converted automatically into code to run.
This method uses GZIP compression to optimize storage consumption and query performance. You can also use the datatransformation feature of Data Firehose to invoke a Lambda function to perform datatransformation in batches. You can test this solution yourself using the AWS Samples GitHub repository.
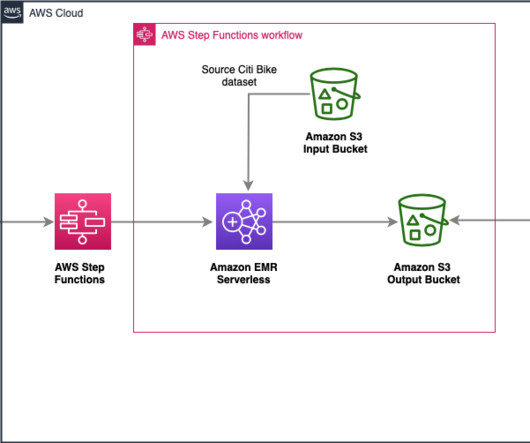
Data ingestion – Steps 1 and 2 use AWS DMS, which connects to the source database and moves full and incremental data (CDC) to Amazon S3 in Parquet format. Let’s refer to this S3 bucket as the raw layer. Datatransformation – Steps 3 and 4 represent an EMR Serverless Spark application (Amazon EMR 6.9
With EMR Serverless, you don’t have to configure, optimize, secure, or operate clusters to run applications with these frameworks. You can run analytics workloads at any scale with automatic scaling that resizes resources in seconds to meet changing data volumes and processing requirements. Do you have follow-up questions or feedback?
With our strategy in mind, we factored in our consumers and consuming services, which primarily are Sisense Fusion Analytics and Cloud Data Teams. Interestingly, this ad hoc analysis benefits from a single source of truth that is easy to query to allow for quickly querying of raw data alongside the cleanest data (i.e.,
Databases can be stored either on a local server or in the cloud and can be access for reporting in many different ways, through limited native tools included with the system collecting the data itself, to Excel exports or various direct connectivity options. Enter the Warehouse.
Customers rely on data from different sources such as mobile applications, clickstream events from websites, historical data, and more to deduce meaningful patterns to optimize their products, services, and processes. citibike-tripdata-destination-ACCOUNT_ID – The bucket used for storing the transformed dataset.
We use Apache Spark as our main data processing engine and have over 1,000 Spark applications running over massive amounts of data every day. These Spark applications implement our business logic ranging from datatransformation, machine learning (ML) model inference, to operational tasks. Their costs were climbing.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content