This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
There are countless examples of big datatransforming many different industries. It can be used for something as visual as reducing traffic jams, to personalizing products and services, to improving the experience in multiplayer video games. We would like to talk about datavisualization and its role in the big data movement.
Amazon DataZone is a data management service that makes it faster and easier for customers to catalog, discover, share, and govern data stored across AWS, on premises, and from third-party sources. This new JDBC connectivity feature enables our governed data to flow seamlessly into these tools, supporting productivity across our teams.”
Table of Contents 1) Benefits Of Big Data In Logistics 2) 10 Big Data In Logistics Use Cases Big data is revolutionizing many fields of business, and logistics analytics is no exception. The complex and ever-evolving nature of logistics makes it an essential use case for big data applications.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. In addition to real-time analytics and visualization, the data needs to be shared for long-term data analytics and machine learning applications.
AWS Glue Studio is a graphical interface that makes it easy to create, run, and monitor extract, transform, and load (ETL) jobs in AWS Glue. DataBrew is a visualdata preparation tool that enables you to clean and normalize data without writing any code. Choose Visual with a blank canvas and create the visual job.
AWS Glue Studio is a graphical interface that makes it easy to create, run, and monitor extract, transform, and load (ETL) jobs in AWS Glue. It allows you to visually compose datatransformation workflows using nodes that represent different data handling steps, which later are converted automatically into code to run.
AI is transforming how senior data engineers and data scientists validate datatransformations and conversions. Artificial intelligence-based verification approaches aid in the detection of anomalies, the enforcement of data integrity, and the optimization of pipelines for improved efficiency.
Selecting the strategies and tools for validating datatransformations and data conversions in your data pipelines. Introduction Datatransformations and data conversions are crucial to ensure that raw data is organized, processed, and ready for useful analysis.
While quantitative analysis, operational analysis, and datavisualizations are key components of business analytics, the goal is to use the insights gained to shape business decisions. What is the difference between business analytics and data analytics? Business analytics is a subset of data analytics.
When we announced the GA of Cloudera Data Engineering back in September of last year, a key vision we had was to simplify the automation of datatransformation pipelines at scale. Typically users need to ingest data, transform it into optimal format with quality checks, and optimize querying of the data by visual analytics tool.
He/she assists the organization by providing clarity and insight into advanced data technology solutions. As quality issues are often highlighted with the use of dashboard software , the change manager plays an important role in the visualization of data quality. Here, it all comes down to the datatransformation error rate.
Data lakes provide a centralized repository for data from various sources, enabling organizations to unlock valuable insights and drive data-driven decision-making. However, as data volumes continue to grow, optimizingdata layout and organization becomes crucial for efficient querying and analysis.
In 2024, datavisualization companies play a pivotal role in transforming complex data into captivating narratives. This blog provides an insightful exploration of the leading entities shaping the datavisualization landscape.
Data Warehouse – in addition to a number of performance optimizations, DW has added a number of new features for better scalability, monitoring and reliability to enable self-service access with security and performance . Enable Cloud Everywhere : Accelerate adoption of cloud-native data services for public clouds .
Let’s go through the ten Azure data pipeline tools Azure Data Factory : This cloud-based data integration service allows you to create data-driven workflows for orchestrating and automating data movement and transformation. You can use it for big data analytics and machine learning workloads.
BMW Group uses 4,500 AWS Cloud accounts across the entire organization but is faced with the challenge of reducing unnecessary costs, optimizing spend, and having a central place to monitor costs. The ultimate goal is to raise awareness of cloud efficiency and optimize cloud utilization in a cost-effective and sustainable manner.
The certification consists of several exams that cover topics such as machine learning, natural language processing, computer vision, and model forecasting and optimization. You should also have experience with pattern detection, experimentation in business optimization techniques, and time-series forecasting.
The availability of machine-readable files opens up new possibilities for data analytics, allowing organizations to analyze large amounts of pricing data. Using machine learning (ML) and datavisualization tools, these datasets can be transformed into actionable insights that can inform decision-making.
The main driving factors include lower total cost of ownership, scalability, stability, improved ingestion connectors (such as Data Prepper , Fluent Bit, and OpenSearch Ingestion), elimination of external cluster managers like Zookeeper, enhanced reporting, and rich visualizations with OpenSearch Dashboards.
AWS Glue is a serverless data integration service that helps analytics users to discover, prepare, move, and integrate data from multiple sources for analytics, machine learning (ML), and application development. For this example, you use AWS Glue Studio to develop a visual ETL pipeline. Select Visual ETL in the central pane.
Within the ANZ enterprise data mesh strategy, aligning data mesh nodes with the ANZ Group’s divisional structure provides optimal alignment between data mesh principles and organizational structure, as shown in the following diagram.
After the read query validation stage was complete and we were satisfied with the performance, we reconnected our orchestrator so that the datatransformation queries could be run in the new cluster. Do you want to know more about what we’re doing in the data area at Dafiti?
If you can’t make sense of your business data, you’re effectively flying blind. Insights hidden in your data are essential for optimizing business operations, finetuning your customer experience, and developing new products — or new lines of business, like predictive maintenance. Azure Data Factory. Everything is visual.
AWS Glue provides all the capabilities needed for data integration, so you can start analyzing your data and putting it to use in minutes instead of months. AWS Glue provides both visual and code-based interfaces to make data integration easier. Users can more easily find and access data using the AWS Glue Data Catalog.
However, you might face significant challenges when planning for a large-scale data warehouse migration. This includes the ETL processes that capture source data, the functional refinement and creation of data products, the aggregation for business metrics, and the consumption from analytics, business intelligence (BI), and ML.
With auto-copy, automation enhances the COPY command by adding jobs for automatic ingestion of data. If storing operational data in a data warehouse is a requirement, synchronization of tables between operational data stores and Amazon Redshift tables is supported. AWS Glue 4.0
In this post, we explore how AWS Glue can serve as the data integration service to bring the data from Snowflake for your data integration strategy, enabling you to harness the power of your data ecosystem and drive meaningful outcomes across various use cases. Store the extracted and transformeddata in Amazon S3.
Let’s look at a few ways that different industries take advantage of streaming data. How industries can benefit from streaming data. Automotive: Monitoring connected, autonomous cars in real time to optimize routes to avoid traffic and for diagnosis of mechanical issues. Optimizing object storage.
To create and manage the data products, smava uses Amazon Redshift , a cloud data warehouse. In this post, we show how smava optimized their data platform by using Amazon Redshift Serverless and Amazon Redshift data sharing to overcome right-sizing challenges for unpredictable workloads and further improve price-performance.
For workloads such as datatransforms, joins, and queries, you can use G.1X With exponentially growing data sources and data lakes, customers want to run more data integration workloads, including their most demanding transforms, aggregations, joins, and queries. 1X (1 DPU) and G.2X You can enable G.4X
In addition, more data is becoming available for processing / enrichment of existing and new use cases e.g., recently we have experienced a rapid growth in data collection at the edge and an increase in availability of frameworks for processing that data. As a result, alternative data integration technologies (e.g.,
In this post, we dive deep into the tool, walking through all steps from log ingestion, transformation, visualization, and architecture design to calculate TCO. Additionally, a TCO calculator generates the TCO estimation of an optimized EMR cluster for facilitating the migration. Now let’s look at how the tool works.
You can visualize the PCA insights in the business intelligence (BI) tool Amazon QuickSight for advanced analysis. In this post, we show you how to use PCA’s data to build automated QuickSight dashboards for advanced analytics to assist in quality assurance (QA) and quality management (QM) processes.
Also, such a concept helps admin to visualize the jobs which are scheduled for debugging purposes. YuniKorn is designed for Big Data app workloads, and it natively supports to run Spark/Flink/Tensorflow, etc efficiently in K8s. YuniKorn is optimized for performance, it is suitable for high throughput and large scale environments.
AWS Glue is a serverless data discovery, load, and transformation service that will prepare data for consumption in BI and AI/ML activities. Solution overview This solution uses Amazon AppFlow to retrieve data from the Jira Cloud. Parquet is a columnar format to optimize subsequent querying. Choose Update.
By supporting open-source frameworks and tools for code-based, automated and visualdata science capabilities — all in a secure, trusted studio environment — we’re already seeing excitement from companies ready to use both foundation models and machine learning to accomplish key tasks. What is watsonx.data?
Furthermore, it allows for necessary actions to be taken, such as rectifying errors in the data source, refining datatransformation processes, and updating data quality rules. The following sample email provides operational metrics for the AWS Glue Data Quality ruleset evaluation. Select your stack and delete it.
In 2024, business intelligence (BI) software has undergone significant advancements, revolutionizing data management and decision-making processes. Harnessing the power of advanced APIs, automation, and AI, these tools simplify data compilation, organization, and visualization, empowering users to extract actionable insights effortlessly.
With Octopai’s support and analysis of Azure Data Factory, enterprises can now view complete end-to-end data lineage from Azure Data Factory all the way through to reporting for the first time ever. About Octopai: Octopai was founded in 2015 by BI professionals who realized the need for dynamic solutions in a stagnant market.
Data collection and processing are handled by a third-party smart sensor manufacturer application residing in Amazon Virtual Private Cloud (Amazon VPC) private subnets behind a Network Load Balancer. The AWS Glue Data Catalog contains the table definitions for the smart sensor data sources stored in the S3 buckets.
With our strategy in mind, we factored in our consumers and consuming services, which primarily are Sisense Fusion Analytics and Cloud Data Teams. Interestingly, this ad hoc analysis benefits from a single source of truth that is easy to query to allow for quickly querying of raw data alongside the cleanest data (i.e.,
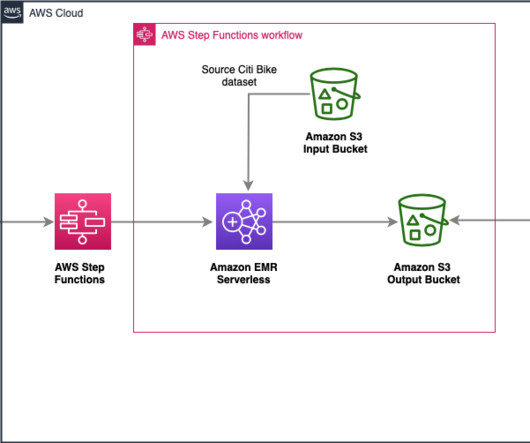
With EMR Serverless, you don’t have to configure, optimize, secure, or operate clusters to run applications with these frameworks. You can run analytics workloads at any scale with automatic scaling that resizes resources in seconds to meet changing data volumes and processing requirements.
These solutions typically include datavisualization, customizable dashboards, and self-service analytics. Tableau Tableau transformsdata usage with end-to-end analytics, including data management, visual analytics, and storytelling. Features include interactive visualizations and native data connectors.
Customers such as Crossmark , DJO Global and others use Birst with Snowflake to deliver the ultimate modern data architecture. The Snowflake/Birst combination creates the optimal balance between IT control and end-user freedom, eliminating analytic silos once and for all.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content