This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
At IKEA, the global home furnishings leader, data is more than an operational necessity—it’s a strategic asset. In a recent presentation at the SAPSA Impuls event in Stockholm , George Sandu, IKEA’s Master Data Leader, shared the company’s datatransformation story, offering valuable lessons for organizations navigating similar challenges.
I was all set to present this session at the European Collaboration Summit in November 2021, but the organizers needed to change the time and date of my session which was rescheduled to take place after I’d left to go back home. Then, we will move towards powerful but simple to use datatypes in R such as data frames.
“In the strategic data assessment, when people were like, ‘Oh, you can show us the ice cream sales?’ When the business operations team first presented the new end-of-game report in an executive meeting, the owners asked to be included. I think you have to toot your own horn that, yes, we have this information available.”.
The dashboard now in production uses Databricks’ Azure data lake to ingest, clean, store, and analyze the data, and Microsoft’s Power BI to generate graphical analytics that present critical operational data in a single view, such as the number of flights coming into domestic and international terminals and average security wait times.
Data collections are the ones and zeroes that encode the actionable insights (patterns, trends, relationships) that we seek to extract from our data through machine learning and data science. Live online presentations, demos, and customer testimonials were complemented with new content posted at sap.com/datasphere.
Its EssentialVerifying DataTransformations (Part4) Uncovering the leading problems in datatransformation workflowsand practical ways to detect and preventthem In Parts 13 of this series of blogs, categories of datatransformations were identified as among the top causes of data quality defects in data pipeline workflows.
Complex Data TransformationsTest Planning Best Practices Ensuring data accuracy with structured testing and best practices Photo by Taylor Vick on Unsplash Introduction Datatransformations and conversions are crucial for data pipelines, enabling organizations to process, integrate, and refine raw data into meaningful insights.
Common challenges and practical mitigation strategies for reliable datatransformations. Photo by Mika Baumeister on Unsplash Introduction Datatransformations are important processes in data engineering, enabling organizations to structure, enrich, and integrate data for analytics , reporting, and operational decision-making.
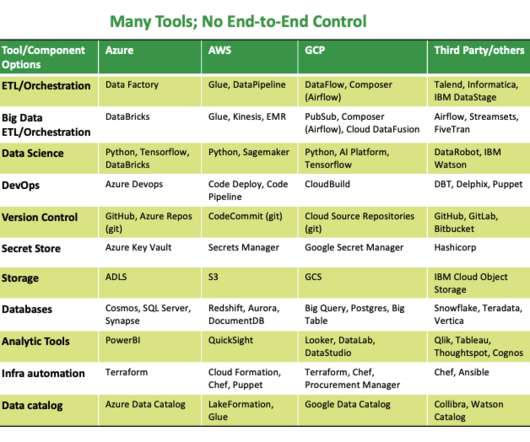
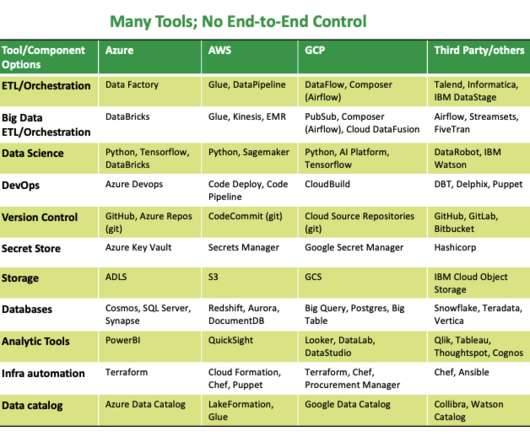
Additionally, integrating mainframe data with the cloud enables enterprises to feed information into data lakes and data lake houses, which is ideal for authorized data professionals to easily leverage the best and most modern tools for analytics and forecasting. Four key challenges prevent them from doing so: 1.
The Airflow REST API facilitates a wide range of use cases, from centralizing and automating administrative tasks to building event-driven, data-aware data pipelines. In this post, we discuss the enhancement and present several use cases that the enhancement unlocks for your Amazon MWAA environment.
In this post, we’ll walk through an example ETL process that uses session reuse to efficiently create, populate, and query temporary staging tables across the full datatransformation workflow—all within the same persistent Amazon Redshift database session.
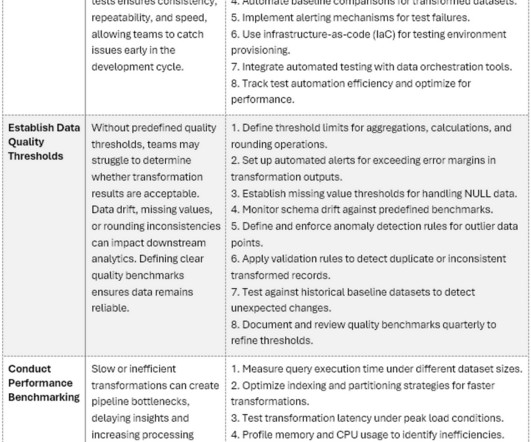
Once data is deemed high-quality, critical business processes and functions should run more efficiently and accurately, with a higher ROI and lower costs. Data Quality Management Best Practices. This means there are no unintended data errors, and it corresponds to its appropriate designation (e.g., date, month, and year).
The rise of SaaS business intelligence tools is answering that need, providing a dynamic vessel for presenting and interacting with essential insights in a way that is digestible and accessible. The future is bright for logistics companies that are willing to take advantage of big data.
To make the data scientists maximally productive, we want to provide supporting software architecture in terms of APIs and libraries that allow them to focus on data, not on the machines. Data Science Layers. However, none of these layers help with modeling and optimization. Model Development.
Airflow has been adopted by many Cloudera Data Platform (CDP) customers in the public cloud as the next generation orchestration service to setup and operationalize complex data pipelines. This presented challenges for users in building more complex multi-step pipelines that are typical of DE workflows.
Further, disclosure management capabilities will ensure secure, collaborative, narrative report production for recurring, multi-author reports, and presentations. We selected insightsoftware to transform the way our finance team operates day to day, said Laura Evison, CFO at Fresca Group.
Amazon OpenSearch Ingestion is a fully managed serverless pipeline that allows you to ingest, filter, transform, enrich, and route data to an Amazon OpenSearch Service domain or Amazon OpenSearch Serverless collection. When you create a new pipeline on the OpenSearch Service console, you’re presented with a new catalog page.
The extraction of raw data, transforming to a suitable format for business needs, and loading into a data warehouse. Datatransformation. This process helps to transform raw data into clean data that can be analysed and aggregated. Data analytics and visualisation.
We also split the datatransformation into several modules (Data Aggregation, Data Filtering, and Data Preparation) to make the system more transparent and easier to maintain. Although each module is specific to a data source or a particular datatransformation, we utilize reusable blocks inside of every job.
Jason is the CDO for Company X, responsible for six teams of data professionals across several locations. The breadth of his teams’ work and the technologies they use present a significant challenge to his main goal: to deliver new and useful analytics solutions to the business. to monitor your data operations.
The company’s orthodontics business, for instance, makes heavy use of image processing to the point that unstructured data is growing at a pace of roughly 20% to 25% per month. Advances in imaging technology present Straumann Group with the opportunity to provide its customers with new capabilities to offer their clients.
Division-level metadata management and data governance – A centrally hosted service provides domain teams with the capability to publish their data products along with relevant metadata, like business definitions and lineage. A data portal for consumers to discover data products and access associated metadata.
If we want to overcome the challenges of such transformations in sustainable ways, we need to look for solutions from multidimensional perspectives. The role of knowledge graphs in AECO transformation At present, knowledge graphs are the best-known technology capable of offering decentralized ways of going beyond existing data silos.
What is the difference between business analytics and data analytics? Business analytics is a subset of data analytics. Data analytics is used across disciplines to find trends and solve problems using data mining , data cleansing, datatransformation, data modeling, and more.
In this post, we delve into a case study for a retail use case, exploring how the Data Build Tool (dbt) was used effectively within an AWS environment to build a high-performing, efficient, and modern data platform. It does this by helping teams handle the T in ETL (extract, transform, and load) processes.
For the updateRequestProcessorChain , OpenSearch provides the ingest pipeline , allowing the enrichment or transformation of data before indexing. Multiple processor stages can be chained to form a pipeline for datatransformation. However, it’s strongly recommended to do the datatransformation outside OpenSearch.
These acquisitions usher in a new era of “ self-service ” by automating complex operations so customers can focus on building great data-driven apps instead of managing infrastructure. Datacoral powers fast and easy datatransformations for any type of data via a robust multi-tenant SaaS architecture that runs in AWS.
Before we dive in, let’s define strands of AI, Machine Learning and Data Science: Business intelligence (BI) leverages software and services to transformdata into actionable insights that inform an organization’s strategic and tactical business decisions.
Data analytics draws from a range of disciplines — including computer programming, mathematics, and statistics — to perform analysis on data in an effort to describe, predict, and improve performance. What are the four types of data analytics? In business analytics, this is the purview of business intelligence (BI).
Data Vault 2.0 allows for the following: Agile data warehouse development Parallel data ingestion A scalable approach to handle multiple data sources even on the same entity A high level of automation Historization Full lineage support However, Data Vault 2.0
Adding datatransformation details to metadata can be challenging because of the dispersed nature of this information across data processing pipelines, making it difficult to extract and incorporate into table-level metadata. Maintaining lists of possible values for the columns requires continuous updates. Choose Stacks.
The difference lies in when and where datatransformation takes place. In ETL, data is transformed before it’s loaded into the data warehouse. In ELT, raw data is loaded into the data warehouse first, then it’s transformed directly within the warehouse.
The advent of rapid adoption of serverless data lake architectures—with ever-growing datasets that need to be ingested from a variety of sources, followed by complex datatransformation and machine learning (ML) pipelines—can present a challenge.
The data organization wants to run the Value Pipeline as robustly as a six sigma factory, and it must be able to implement and deploy process improvements as rapidly as a Silicon Valley start-up. The data engineer builds datatransformations. Their product is the data.
Jason is the CDO for Company X, responsible for six teams of data professionals across several locations. The breadth of his teams’ work and the technologies they use present a significant challenge to his main goal: to deliver new and useful analytics solutions to the business. to monitor your data operations.
After the read query validation stage was complete and we were satisfied with the performance, we reconnected our orchestrator so that the datatransformation queries could be run in the new cluster. At this point, only one-time queries and those made by Amazon QuickSight reached the new cluster.
The data science algorithm Valentine is an effective tool for this. Valentine is presented in the paper Valentine: Evaluating Matching Techniques for Dataset Discovery (2021, Koutras et al.). Joel has led datatransformation projects on fraud analytics, claims automation, and data governance.
Whether you’re looking to earn a certification from an accredited university, gain experience as a new grad, hone vendor-specific skills, or demonstrate your knowledge of data analytics, the following certifications (presented in alphabetical order) will work for you. Not finding what you’re looking for?
You can check out a self service data prep flow from catalog to viz in this recorded version here. Rita Sallam Introduces the Data Prep Rodeo. Which brings me to memorable moment #2 on Tuesday when Rita Sallam took the stage for her drill-down presentation on Self-Service Data Prep. To Coming Home, Home on the Range.
Typically I break each of the areas appearing in boxes above into sub-areas, score the organisation against these, roll the results back up and present them back to the client with accompanying commentary; normally also including some sort of benchmark for comparison [2].
With these features, you can now build data pipelines completely in standard SQL that are serverless, more simple to build, and able to operate at scale. Typically, datatransformation processes are used to perform this operation, and a final consistent view is stored in an S3 bucket or folder.
This post presents one possible approach to addressing this challenge in an Amazon Redshift data warehouse. Stored procedures Stored procedures are commonly used to encapsulate logic for datatransformation, data validation, and business-specific logic. all URIDs that have are present).
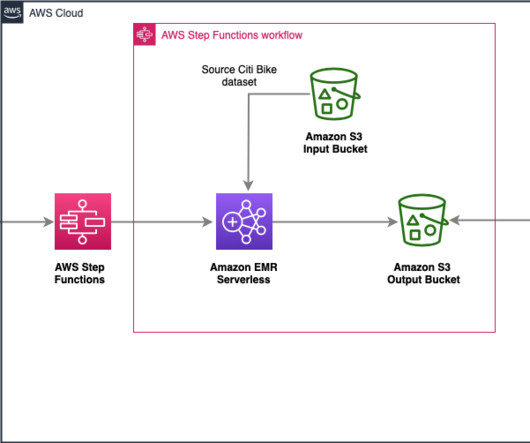
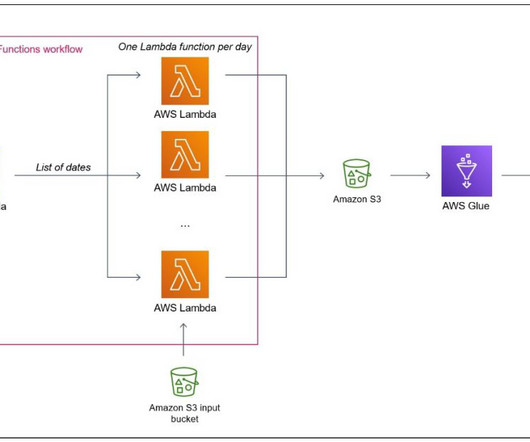
Prerequisites Before you get started, make sure you have the following prerequisites: An AWS account An IAM user with administrator access An S3 bucket Solution Architecture To automate the complete process, we use the following architecture, which integrates Step Functions for orchestration and Amazon EMR Serverless for datatransformations.
It has not been specifically designed for heavy datatransformation tasks. The proposed architecture enables extraction and repartitioning of the data in just a few minutes. It’s scalable and cost-effective, and can be adapted to other ETL and data processing use cases.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content