This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We need robust versioning for data, models, code, and preferably even the internal state of applications—think Git on steroids to answer inevitable questions: What changed? The applications must be integrated to the surrounding business systems so ideas can be tested and validated in the real world in a controlled manner.
In this post, well see the fundamental procedures, tools, and techniques that data engineers, data scientists, and QA/testing teams use to ensure high-quality data as soon as its deployed. First, we look at how unit and integration tests uncover transformation errors at an early stage. PyTest, JUnit,NUnit).
Together with price-performance, Amazon Redshift offers capabilities such as serverless architecture, machine learning integration within your data warehouse and secure data sharing across the organization. dbt Cloud is a hosted service that helps data teams productionize dbt deployments. Choose Test Connection.
Managing tests of complex datatransformations when automated datatesting tools lack important features? Photo by Marvin Meyer on Unsplash Introduction Datatransformations are at the core of modern business intelligence, blending and converting disparate datasets into coherent, reliable outputs.
Common challenges and practical mitigation strategies for reliable datatransformations. Photo by Mika Baumeister on Unsplash Introduction Datatransformations are important processes in data engineering, enabling organizations to structure, enrich, and integrate data for analytics , reporting, and operational decision-making.
How GX helps data teams validate, test, and monitor complex data pipelines Introduction Data flows from diverse sources, and transformations are becoming increasingly complex. Great Expectations can enable a wide range of datatransformations and conversion operations.
Your generated jobs can use a variety of datatransformations, including filters, projections, unions, joins, and aggregations, giving you the flexibility to handle complex data processing requirements. In this post, we discuss how Amazon Q data integration transforms ETL workflow development.
Reporting being part of an effective DQM, we will also go through some data quality metrics examples you can use to assess your efforts in the matter. But first, let’s define what data quality actually is. What is the definition of data quality? Why Do You Need Data Quality Management? date, month, and year).
For each service, you need to learn the supported authorization and authentication methods, data access APIs, and framework to onboard and testdata sources. This approach simplifies your data journey and helps you meet your security requirements. This new capability can simplify your data journey.
AI is transforming how senior data engineers and data scientists validate datatransformations and conversions. Artificial intelligence-based verification approaches aid in the detection of anomalies, the enforcement of data integrity, and the optimization of pipelines for improved efficiency.
” I, thankfully, learned this early in my career, at a time when I could still refer to myself as a software developer. Upload your data, click through a workflow, walk away. If you’re a professional data scientist, you already have the knowledge and skills to test these models. It does not exist in the code.
Prompt with no metadata For the first test, we used a basic prompt containing just the SQL generating instructions and no table metadata. A question arises on what level of details we need to include in the table metadata. As tables undergo schema changes, updating metadata for each change can be time-consuming and requires effort.
All these pitfalls are avoidable with the right data integrity policies in place. Means of ensuring data integrity. Data integrity can be divided into two areas: physical and logical. Physical data integrity refers to how data is stored and accessed. Data integrity: A process and a state.
What is data management? Data management can be defined in many ways. Usually the term refers to the practices, techniques and tools that allow access and delivery through different fields and data structures in an organisation. Extraction, Transform, Load (ETL). Datatransformation. Microsoft Azure.
We refer to multiple masking policies being attached to a table as a multi-modal masking policy. SELECT * FROM svv_attached_masking_policy; Now you can test that different users can see the same data masked differently based on their roles. Check that the masking policies are created with the following code: -- 1.1-
For more information on this foundation, refer to A Detailed Overview of the Cost Intelligence Dashboard. Additionally, it manages table definitions in the AWS Glue Data Catalog , containing references to data sources and targets of extract, transform, and load (ETL) jobs in AWS Glue.
Traditionally, such a legacy call center analytics platform would be built on a relational database that stores data from streaming sources. Datatransformations through stored procedures and use of materialized views to curate datasets and generate insights is a known pattern with relational databases.
Developers need to onboard new data sources, chain multiple datatransformation steps together, and explore data as it travels through the flow. Figure 5: Parameter references in the configuration panel and auto-complete. Figure 7: Test sessions provide an interactive experience that NiFi developers love.
To grow the power of data at scale for the long term, it’s highly recommended to design an end-to-end development lifecycle for your data integration pipelines. The following are common asks from our customers: Is it possible to develop and test AWS Glue data integration jobs on my local laptop?
Kinesis Data Firehose is a fully managed service for delivering near-real-time streaming data to various destinations for storage and performing near-real-time analytics. You can perform analytics on VPC flow logs delivered from your VPC using the Kinesis Data Firehose integration with Datadog as a destination.
Additionally, you can configure OpenSearch Ingestion to apply datatransformations before delivery. The content includes a reference architecture, a step-by-step guide on infrastructure setup, sample code for implementing the solution within a use case, and an AWS Cloud Development Kit (AWS CDK) application for deployment.
However, you might face significant challenges when planning for a large-scale data warehouse migration. For an example, refer to How JPMorgan Chase built a data mesh architecture to drive significant value to enhance their enterprise data platform. Platform architects define a well-architected platform.
Our approach The migration initiative consisted of two main parts: building the new architecture and migrating data pipelines from the existing tool to the new architecture. Often, we would work on both in parallel, testing one component of the architecture while developing another at the same time.
Jessicamouth 2964 Queensland Load the dataset First, create a new table in your Redshift Serverless endpoint and copy the testdata into it by doing the following: Open the Query Editor V2 and log in using the admin user name and details defined when the endpoint was created.
so you have some reference as to where each item fits (and this will also make it easier for you to pick tools for the priority order referenced in Context #3 above). If you can show ROI on a DW it would be a good use of your money to go with Omniture Discover, WebTrends Data Mart, Coremetrics Explore. and embrace Multiplicity.
In the next sections, we explore the following topics: The DAG file, in order to understand how to define and then pass the correlation ID in the AWS Glue and EMR tasks The code needed in the Python scripts to output information based on the correlation ID Refer to the GitHub repo for the detailed DAG definition and Spark scripts.
Building a starter version of anything can often be straightforward, but building something with enterprise-grade scale, security, resiliency, and performance typically requires knowledge of and adherence to battle-tested best practices, and using the right tools and features in the right scenario. Data Vault 2.0
Duplicating data from a production database to a lower or lateral environment and masking personally identifiable information (PII) to comply with regulations enables development, testing, and reporting without impacting critical systems or exposing sensitive customer data. PII detection and scrubbing.
For more details on how to configure and schedule the log collector, refer to the yarn-log-collector GitHub repo. Transform the YARN job history logs from JSON to CSV After obtaining YARN logs, you run a YARN log organizer, yarn-log-organizer.py, which is a parser to transform JSON-based logs to CSV files.
Datatransformation plays a pivotal role in providing the necessary data insights for businesses in any organization, small and large. To gain these insights, customers often perform ETL (extract, transform, and load) jobs from their source systems and output an enriched dataset.
Example data The following code shows an example of raw order data from the stream: Record1: { "orderID":"101", "email":" john. To address the challenges with the raw data, we can implement a comprehensive datatransformation process using Redshift ML integrated with an LLM in an ETL workflow.
AWS Glue Studio is a graphical interface that makes it easy to create, run, and monitor extract, transform, and load (ETL) jobs in AWS Glue. It allows you to visually compose datatransformation workflows using nodes that represent different data handling steps, which later are converted automatically into code to run.
With these features, you can now build data pipelines completely in standard SQL that are serverless, more simple to build, and able to operate at scale. Typically, datatransformation processes are used to perform this operation, and a final consistent view is stored in an S3 bucket or folder.
citibike-tripdata-destination-ACCOUNT_ID – The bucket used for storing the transformed dataset. When implementing the solution in this post, replace references to airflow-blog-bucket-ACCOUNT_ID and citibike-tripdata-destination-ACCOUNT_ID with the names of your own S3 buckets. Run the DAG Let’s look at how to run the DAGs.
In this post, we discuss why AWS recommends moving from Kinesis Data Analytics for SQL Applications to Amazon Kinesis Data Analytics for Apache Flink to take advantage of Apache Flink’s advanced streaming capabilities. View the stream data. Transform and enrich the data. Manipulate the data with Python.
Creating an external schema from the data share database on the consumer, mirroring that of the producer cluster with identical names. Testing: Conducting an internal week-long regression testing and auditing process to meticulously validate all data points by running the same workload and twice the workload.
You can also use the datatransformation feature of Data Firehose to invoke a Lambda function to perform datatransformation in batches. You can test this solution yourself using the AWS Samples GitHub repository. This method uses GZIP compression to optimize storage consumption and query performance.
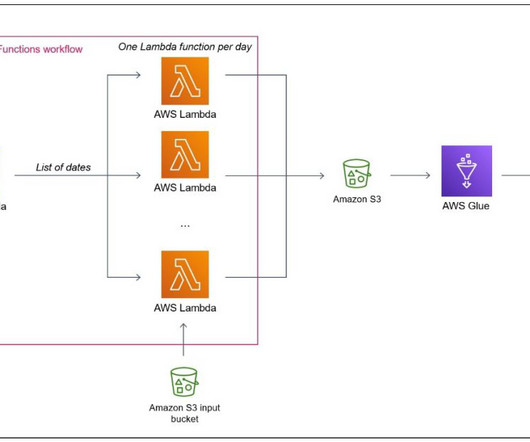
It has not been specifically designed for heavy datatransformation tasks. Now that the data is on Amazon S3, you can delete the directory that has been downloaded from your Linux machine. Create the Lambda functions For step-by-step instructions on how to create a Lambda function, refer to Getting started with Lambda.
A source of unpredictable workloads is dbt Cloud , which SafetyCulture uses to manage datatransformations in the form of models. Whenever models are created or modified, a dbt Cloud CI job is triggered to test the models by materializing the models in Amazon Redshift. Refer to Connect dbt Cloud to Redshift for setup steps.
The following AWS services are used for data ingestion, processing, and load: Amazon AppFlow is a fully managed integration service that enables you to securely transfer data between SaaS applications like Salesforce, SAP, Marketo, Slack, and ServiceNow, and AWS services like Amazon S3 and Amazon Redshift , in just a few clicks.
We are going to turn our attention away from expanding our catalog of models [as mentioned previously in the book ] and instead take a closer look at the data. Feature engineering refers to manipulation—addition, deletion, combination, mutation—of the features. Separate out a hold-out test set. Don’t peek at it.
AWS DMS enables us to capture deltas, including deletes from the source database, through the use of Change Data Capture (CDC) configuration. CDC in DMS enables us to capture deltas without writing code and without missing any changes, which is critical for the integrity of the data. Under Transforms , choose SQL Query.
We use Apache Spark as our main data processing engine and have over 1,000 Spark applications running over massive amounts of data every day. These Spark applications implement our business logic ranging from datatransformation, machine learning (ML) model inference, to operational tasks. Their costs were climbing.
Alternatively, you can use AWS Glue for Apache Spark, which provides built-in support for bucketing configurations during the datatransformation process. AWS Glue allows you to define bucketing parameters, such as the number of buckets and the columns to bucket on, providing an optimized data layout for efficient querying with Athena.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content