This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon DataZone is a data management service that makes it faster and easier for customers to catalog, discover, share, and govern data stored across AWS, on premises, and from third-party sources. Refer to the detailed blog post on how you can use this to connect through various other tools.
This means you can refine your ETL jobs through natural follow-up questionsstarting with a basic data pipeline and progressively adding transformations, filters, and business logic through conversation. The DataFrame code generation now extends beyond AWS Glue DynamicFrame to support a broader range of data processing scenarios.
Reporting being part of an effective DQM, we will also go through some data quality metrics examples you can use to assess your efforts in the matter. But first, let’s define what data quality actually is. What is the definition of data quality? Why Do You Need Data Quality Management? date, month, and year).
AWS Glue Studio is a graphical interface that makes it easy to create, run, and monitor extract, transform, and load (ETL) jobs in AWS Glue. It allows you to visually compose datatransformation workflows using nodes that represent different data handling steps, which later are converted automatically into code to run.
With the ability to browse metadata, you can understand the structure and schema of the data source, identify relevant tables and fields, and discover useful data assets you may not be aware of. You can navigate to the projects Data page to visually verify the existence of the newly created table. option("url", jdbcurl).option("dbtable",
You can use AWS Glue Studio to set up data replication and mask PII with no coding required. AWS Glue Studio visual editor provides a low-code graphic environment to build, run, and monitor extract, transform, and load (ETL) scripts. Datatransformation – Adjusts and removes unnecessary fields.
The goal is to examine five major methods of verifying and validating datatransformations in data pipelines with an eye toward high-quality data deployment. First, we look at how unit and integration tests uncover transformation errors at an early stage. Key Tools & Processes Data profiling tools (e.g.,
Together the technologies aim to help business users and “novice” data analysts explore their data and gain insights without having to resort to data experts. This is really empowering everyone to be a data expert,” Maxon said. “It Shared Dimensions and Composable Data Sources.
AI is transforming how senior data engineers and data scientists validate datatransformations and conversions. Artificial intelligence-based verification approaches aid in the detection of anomalies, the enforcement of data integrity, and the optimization of pipelines for improved efficiency.
Traditionally, such a legacy call center analytics platform would be built on a relational database that stores data from streaming sources. Datatransformations through stored procedures and use of materialized views to curate datasets and generate insights is a known pattern with relational databases.
Under the Transparency in Coverage (TCR) rule , hospitals and payors to publish their pricing data in a machine-readable format. For more information, refer to Delivering Consumer-friendly Healthcare Transparency in Coverage On AWS. Then you can use Amazon Athena V3 to query the tables in the Data Catalog.
” I, thankfully, learned this early in my career, at a time when I could still refer to myself as a software developer. That takes us to a conspicuous omission from that list of roles: the data scientists who focused on building basic models. Companies will still need advanced ML modeling and data viz, sure.
Amazon OpenSearch Ingestion is a fully managed serverless pipeline that allows you to ingest, filter, transform, enrich, and route data to an Amazon OpenSearch Service domain or Amazon OpenSearch Serverless collection. You can now view the configurations in JSON format in addition to the YAML format and edit them in place.
For more information on this foundation, refer to A Detailed Overview of the Cost Intelligence Dashboard. Additionally, it manages table definitions in the AWS Glue Data Catalog , containing references to data sources and targets of extract, transform, and load (ETL) jobs in AWS Glue.
Kinesis Data Firehose is a fully managed service for delivering near-real-time streaming data to various destinations for storage and performing near-real-time analytics. You can perform analytics on VPC flow logs delivered from your VPC using the Kinesis Data Firehose integration with Datadog as a destination.
AWS Glue is a serverless data integration service that makes it straightforward to discover, prepare, and combine data for analytics, machine learning (ML), and application development. AWS Glue provides both visual and code-based interfaces to make data integration effortless. Choose Create job and Visual ETL.
But the features in Power BI Premium are now more powerful than the functionality in Azure Analysis Services, so while the service isn’t going away, Microsoft will offer an automated migration tool in the second half of this year for customers who want to move their data models into Power BI instead. Azure Data Factory.
This allows business analysts and decision-makers to gain valuable insights, visualize key metrics, and explore the data in depth, enabling informed decision-making and strategic planning for pricing and promotional strategies. For Data sources , search for and select Snowflake. On the Visual tab, choose Add nodes.
If storing operational data in a data warehouse is a requirement, synchronization of tables between operational data stores and Amazon Redshift tables is supported. In scenarios where datatransformation is required, you can use Redshift stored procedures to modify data in Redshift tables. AWS Glue 4.0
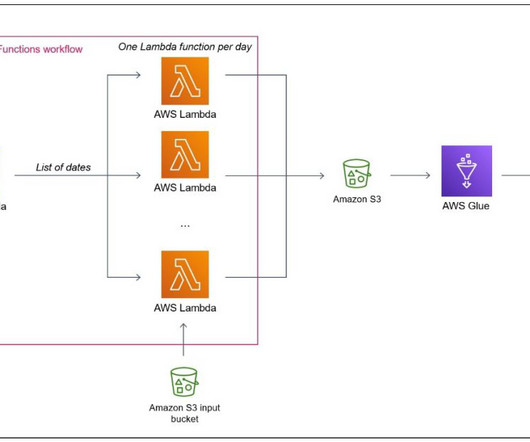
It has not been specifically designed for heavy datatransformation tasks. Now that the data is on Amazon S3, you can delete the directory that has been downloaded from your Linux machine. Create the Lambda functions For step-by-step instructions on how to create a Lambda function, refer to Getting started with Lambda.
For full instructions, refer to Jira Cloud connector for Amazon AppFlow. You can do this by updating the CloudFormation stack with a flag that includes the CDC and datatransformation steps. This will enable both the CDC steps and the datatransformation steps for the Jira data. Choose Update.
Developers need to onboard new data sources, chain multiple datatransformation steps together, and explore data as it travels through the flow. A reimagined visual editor to boost developer productivity and enable self service. Figure 5: Parameter references in the configuration panel and auto-complete.
In this post, we dive deep into the tool, walking through all steps from log ingestion, transformation, visualization, and architecture design to calculate TCO. For more details on how to configure and schedule the log collector, refer to the yarn-log-collector GitHub repo.
In addition, more data is becoming available for processing / enrichment of existing and new use cases e.g., recently we have experienced a rapid growth in data collection at the edge and an increase in availability of frameworks for processing that data. As a result, alternative data integration technologies (e.g.,
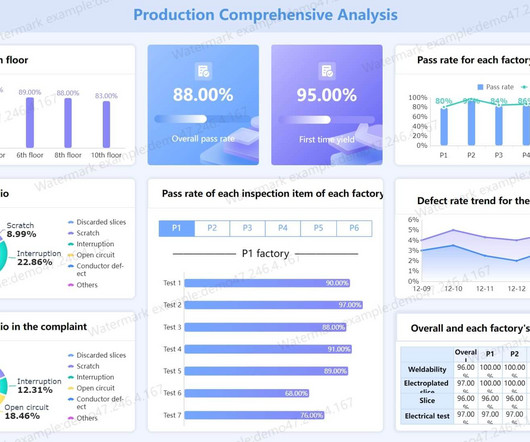
You can visualize the PCA insights in the business intelligence (BI) tool Amazon QuickSight for advanced analysis. In this post, we show you how to use PCA’s data to build automated QuickSight dashboards for advanced analytics to assist in quality assurance (QA) and quality management (QM) processes.
You can use your preferred IDE to implement AWS resource definition using the AWS Cloud Development Kit (AWS CDK) or AWS CloudFormation , and also the business logic of AWS Glue job scripts for data integration. To learn more about how to implement your AWS Glue job scripts locally, refer to Develop and test AWS Glue version 3.0
Notebooks are provisioned quickly and provide a way for you to instantly view and analyze your streaming data. This pipeline could further be used to send data to Amazon OpenSearch Service or other targets for additional processing and visualization. View the stream data. Transform and enrich the data.
Furthermore, it allows for necessary actions to be taken, such as rectifying errors in the data source, refining datatransformation processes, and updating data quality rules. The following sample email provides operational metrics for the AWS Glue Data Quality ruleset evaluation.
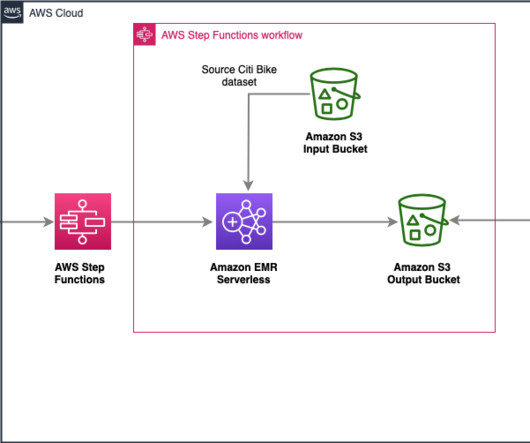
citibike-tripdata-destination-ACCOUNT_ID – The bucket used for storing the transformed dataset. When implementing the solution in this post, replace references to airflow-blog-bucket-ACCOUNT_ID and citibike-tripdata-destination-ACCOUNT_ID with the names of your own S3 buckets. Run the DAG Let’s look at how to run the DAGs.
You can also use the datatransformation feature of Data Firehose to invoke a Lambda function to perform datatransformation in batches. Refer to the instructions in the README file for steps on how to provision and decommission this solution.
AWS Step Functions is a serverless orchestration service that enables developers to build visual workflows for applications as a series of event-driven steps. References Amazon EMR Serverless AWS Step Functions About the Authors Naveen Balaraman is a Sr Cloud Application Architect at Amazon Web Services. Leave a comment.
The following AWS services are used for data ingestion, processing, and load: Amazon AppFlow is a fully managed integration service that enables you to securely transfer data between SaaS applications like Salesforce, SAP, Marketo, Slack, and ServiceNow, and AWS services like Amazon S3 and Amazon Redshift , in just a few clicks.
For addressing data quality challenges in Amazon Simple Storage Service (Amazon S3) data lakes and data pipelines, AWS has announced AWS Glue Data Quality (preview). Create a table for weight information This reference table holds two columns; the table name and the column mapping with weights.
In summary, embedded analytics refers to actionable intelligence seamlessly integrated into customer-facing products, applications, or services. These solutions typically include datavisualization, customizable dashboards, and self-service analytics. Features include interactive visualizations and native data connectors.
AWS DMS enables us to capture deltas, including deletes from the source database, through the use of Change Data Capture (CDC) configuration. CDC in DMS enables us to capture deltas without writing code and without missing any changes, which is critical for the integrity of the data. Navigate to the Visual tab.
A modern data stack relies on cloud computing, whereas a legacy data stack stores data on servers instead of in the cloud. Modern data stacks provide access for more data professionals than a legacy data stack. Business Intelligence Tools: Business intelligence (BI) tools are used to visualize your data.
However, you might face significant challenges when planning for a large-scale data warehouse migration. For an example, refer to How JPMorgan Chase built a data mesh architecture to drive significant value to enhance their enterprise data platform. Platform architects define a well-architected platform.
I used to talk about carrying out a Situational Analysis of Data Capabilities, nowadays I am more likely to refer to a Data Capability Review. I make such reviews with respect to my own Data Capability Framework, which I introduced to the public in 2019 via A Simple Data Capability Framework.
Data ingestion – Steps 1 and 2 use AWS DMS, which connects to the source database and moves full and incremental data (CDC) to Amazon S3 in Parquet format. Let’s refer to this S3 bucket as the raw layer. Datatransformation – Steps 3 and 4 represent an EMR Serverless Spark application (Amazon EMR 6.9
Alternatively, you can use AWS Glue for Apache Spark, which provides built-in support for bucketing configurations during the datatransformation process. AWS Glue allows you to define bucketing parameters, such as the number of buckets and the columns to bucket on, providing an optimized data layout for efficient querying with Athena.
Before we dive into the topics of big data as a service and analytics applied to same, let’s quickly clarify data analytics using an oft-used application of analytics: Visualization! As we move from right to left in the diagram, from big data to BI, we notice that unstructured datatransforms into structured data. (ESB
Before we dive into the topics of big data as a service and analytics applied to same, let’s quickly clarify data analytics using an oft-used application of analytics: Visualization! As we move from right to left in the diagram, from big data to BI, we notice that unstructured datatransforms into structured data. (ESB
Data Analysis Report (by FineReport ) Note: All the data analysis reports in this article are created using the FineReport reporting tool. Leveraging the advanced enterprise-level web reporting tool capabilities of FineReport , we empower businesses to achieve genuine datatransformation. Try FineReport Now 1.
We are going to turn our attention away from expanding our catalog of models [as mentioned previously in the book ] and instead take a closer look at the data. Feature engineering refers to manipulation—addition, deletion, combination, mutation—of the features. In our example, we had data from a uniform or flat-ish distribution.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content