This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Complex Data TransformationsTest Planning Best Practices Ensuring data accuracy with structured testing and best practices Photo by Taylor Vick on Unsplash Introduction Datatransformations and conversions are crucial for data pipelines, enabling organizations to process, integrate, and refine raw data into meaningful insights.
Common challenges and practical mitigation strategies for reliable datatransformations. Photo by Mika Baumeister on Unsplash Introduction Datatransformations are important processes in data engineering, enabling organizations to structure, enrich, and integrate data for analytics , reporting, and operational decision-making.
With this launch of JDBC connectivity, Amazon DataZone expands its support for data users, including analysts and scientists, allowing them to work in their preferred environments—whether it’s SQL Workbench, Domino, or Amazon-native solutions—while ensuring secure, governed access within Amazon DataZone. Choose Test connection.
In this post, well see the fundamental procedures, tools, and techniques that data engineers, data scientists, and QA/testing teams use to ensure high-quality data as soon as its deployed. First, we look at how unit and integration tests uncover transformation errors at an early stage. PyTest, JUnit,NUnit).
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing ETL, business intelligence (BI), and reporting tools. dbt Cloud is a hosted service that helps data teams productionize dbt deployments.
Fragmented systems, inconsistent definitions, outdated architecture and manual processes contribute to a silent erosion of trust in data. When financial data is inconsistent, reporting becomes unreliable. A compliance report is rejected because timestamps dont match across systems. Assign domain data stewards.
How dbt Core aids data teams test, validate, and monitor complex datatransformations and conversions Photo by NASA on Unsplash Introduction dbt Core, an open-source framework for developing, testing, and documenting SQL-based datatransformations, has become a must-have tool for modern data teams as the complexity of data pipelines grows.
How GX helps data teams validate, test, and monitor complex data pipelines Introduction Data flows from diverse sources, and transformations are becoming increasingly complex. Great Expectations can enable a wide range of datatransformations and conversion operations.
In this article, we will detail everything which is at stake when we talk about DQM: why it is essential, how to measure data quality, the pillars of good quality management, and some data quality control techniques. But first, let’s define what data quality actually is. 4 – DataReporting. date, month, and year).
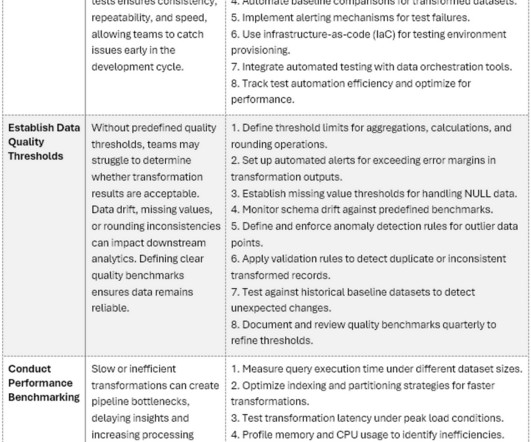
Its EssentialVerifying DataTransformations (Part4) Uncovering the leading problems in datatransformation workflowsand practical ways to detect and preventthem In Parts 13 of this series of blogs, categories of datatransformations were identified as among the top causes of data quality defects in data pipeline workflows.
AI is transforming how senior data engineers and data scientists validate datatransformations and conversions. Artificial intelligence-based verification approaches aid in the detection of anomalies, the enforcement of data integrity, and the optimization of pipelines for improved efficiency.
The data organization wants to run the Value Pipeline as robustly as a six sigma factory, and it must be able to implement and deploy process improvements as rapidly as a Silicon Valley start-up. The data engineer builds datatransformations. Their product is the data. Create tests. Run the factory.
DataOps Observability can help you ensure that your complex data pipelines and processes are accurate and that they deliver as designed. Observability also validates that your datatransformations, models, and reports are performing as expected. to monitor your data operations. without replacing staff or systems?to
Before we dive in, let’s define strands of AI, Machine Learning and Data Science: Business intelligence (BI) leverages software and services to transformdata into actionable insights that inform an organization’s strategic and tactical business decisions. Once the model has been trained, it will need to be tested.
Datatransformation plays a pivotal role in providing the necessary data insights for businesses in any organization, small and large. To gain these insights, customers often perform ETL (extract, transform, and load) jobs from their source systems and output an enriched dataset.
Azure Blob Storage serves as the data lake to store raw data. Azure Databricks, a big data analytics platform built on Apache Spark, performs the actual datatransformations. Azure Machine Learning can then use this data to train, test, and deploy machine learning models. Azure Machine Learning).
A modern data platform entails maintaining data across multiple layers, targeting diverse platform capabilities like high performance, ease of development, cost-effectiveness, and DataOps features such as CI/CD, lineage, and unit testing. It does this by helping teams handle the T in ETL (extract, transform, and load) processes.
Data analytics draws from a range of disciplines — including computer programming, mathematics, and statistics — to perform analysis on data in an effort to describe, predict, and improve performance. What are the four types of data analytics? Data analytics and data science are closely related.
The goal of DataOps Observability is to provide visibility of every journey that data takes from source to customer value across every tool, environment, data store, data and analytic team, and customer so that problems are detected, localized and raised immediately. That data then fills several database tables.
DataOps Observability can help you ensure that your complex data pipelines and processes are accurate and that they deliver as designed. Observability also validates that your datatransformations, models, and reports are performing as expected. to monitor your data operations. without replacing staff or systems?to
What is the difference between business analytics and data analytics? Business analytics is a subset of data analytics. Data analytics is used across disciplines to find trends and solve problems using data mining , data cleansing, datatransformation, data modeling, and more.
All this contributes to your overall data integrity profile. Logical data integrity is designed to guard against human error. We’ll explore this concept in detail in the testing section below. Data integrity: A process and a state. There are two means for ensuring data integrity: process and testing.
However, you might face significant challenges when planning for a large-scale data warehouse migration. This will enable right-sizing the Redshift data warehouse to meet workload demands cost-effectively. This report shows how tables, views, and stored procedures rely on each other.
dbt allows data teams to produce trusted data sets for reporting, ML modeling, and operational workflows using SQL, with a simple workflow that follows software engineering best practices like modularity, portability, and continuous integration/continuous development (CI/CD). Introduction.
Photo by CDC on Unsplash Many data pipeline failures and quality issues that are detected by data observability tools in production could have been prevented earlier in the pipeline lifecycle with better pre-production testing strategies. Helps identify transformation errors, and data quality issues early, minimizing risks.
Airflow has been adopted by many Cloudera Data Platform (CDP) customers in the public cloud as the next generation orchestration service to setup and operationalize complex data pipelines. The same Airflow job can now be used to generate different SQL reports. Looking forward.
At the heart of CDP is SDX , a unified context layer for governance and security, that makes it easy to create a secure data lake and run workloads that address all stages of your data lifecycle (collect, enrich, report, serve and predict). Enrich – Data Engineering (Apache Spark and Apache Hive). This is Now.
The main driving factors include lower total cost of ownership, scalability, stability, improved ingestion connectors (such as Data Prepper , Fluent Bit, and OpenSearch Ingestion), elimination of external cluster managers like Zookeeper, enhanced reporting, and rich visualizations with OpenSearch Dashboards.
The advent of rapid adoption of serverless data lake architectures—with ever-growing datasets that need to be ingested from a variety of sources, followed by complex datatransformation and machine learning (ML) pipelines—can present a challenge. Disable the rules after testing to avoid repeated messages.
In addition to using native managed AWS services that BMS didn’t need to worry about upgrading, BMS was looking to offer an ETL service to non-technical business users that could visually compose datatransformation workflows and seamlessly run them on the AWS Glue Apache Spark-based serverless data integration engine.
The data products used inside the company include insights from user journeys, operational reports, and marketing campaign results, among others. The data platform serves on average 60 thousand queries per day. The data volume is in double-digit TBs with steady growth as business and data sources evolve.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing ETL (extract, transform, and load), business intelligence (BI), and reporting tools. All columns should masked for them.
Our approach The migration initiative consisted of two main parts: building the new architecture and migrating data pipelines from the existing tool to the new architecture. Often, we would work on both in parallel, testing one component of the architecture while developing another at the same time.
According to Evanta’s 2022 CIO Leadership Perspectives study, CIOs’ second top priority within the IT function is around data and analytics, with CIOs seeing advancing organizational use of data as key to reaching enterprise objectives. To get there, Angel-Johnson has embarked on a master data management initiative.
Datatransforms businesses. That’s where the data lifecycle comes into play. Managing data and its flow, from the edge to the cloud, is one of the most important tasks in the process of gaining data intelligence. . This has also improved analytics for ad hoc business report queries.
Each CDH dataset has three processing layers: source (raw data), prepared (transformeddata in Parquet), and semantic (combined datasets). It is possible to define stages (DEV, INT, PROD) in each layer to allow structured release and test without affecting PROD.
dbt is an open source, SQL-first templating engine that allows you to write repeatable and extensible datatransforms in Python and SQL. dbt is predominantly used by data warehouses (such as Amazon Redshift ) customers who are looking to keep their datatransform logic separate from storage and engine.
Queue Usage Concurrency Scaling Mode Concurrency on Main / Memory % Query Monitoring Rules etl For ingestion from multiple data integration auto auto Stop action on: Query runtime (seconds) > 3600 The following table summarizes the new workload management configuration for the consumer cluster.
Modak Nabu relies on a framework of “Botworks”, a series of micro-jobs to accomplish various datatransformation steps from ingestion to profiling, and indexing. Cloudera Data Engineering within CDP provides : Fully managed Spark-on-Kubernetes service that hides the complexity running production DE workloads at scale.
These tools empower analysts and data scientists to easily collaborate on the same data, with their choice of tools and analytic engines. No more lock-in, unnecessary datatransformations, or data movement across tools and clouds just to extract insights out of the data.
Enterprise data is brought into data lakes and data warehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. A question arises on what level of details we need to include in the table metadata.
Cloudera Data Warehouse). Efficient batch data processing. Complex datatransformations. Built-in workflow: In addition to querying capabilities, Rill includes scheduled exports and alerts to stay on top of regular reporting and provide opportunities to dive deeper. Apache Hive. Joins and subqueries . Apache Druid.
To accomplish this interchange, the method uses data mining and machine learning and it contains components like a data dictionary to define the fields used by the model, and datatransformation to map user data and make it easier for the system to mine that data. No programming or scripting required.
Duplicating data from a production database to a lower or lateral environment and masking personally identifiable information (PII) to comply with regulations enables development, testing, and reporting without impacting critical systems or exposing sensitive customer data. PII detection and scrubbing.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content