This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Organizations can’t afford to mess up their datastrategies, because too much is at stake in the digital economy. How enterprises gather, store, cleanse, access, and secure their data can be a major factor in their ability to meet corporate goals. Here are some datastrategy mistakes IT leaders would be wise to avoid.
How dbt Core aids data teams test, validate, and monitor complex datatransformations and conversions Photo by NASA on Unsplash Introduction dbt Core, an open-source framework for developing, testing, and documenting SQL-based datatransformations, has become a must-have tool for modern data teams as the complexity of data pipelines grows.
AI is transforming how senior data engineers and data scientists validate datatransformations and conversions. Artificial intelligence-based verification approaches aid in the detection of anomalies, the enforcement of data integrity, and the optimization of pipelines for improved efficiency.
“Digitizing was our first stake at the table in our data journey,” he says. That step, primarily undertaken by developers and data architects, established data governance and data integration. “As For that, he relied on a defensive and offensive metaphor for his datastrategy.
Amazon Athena provides interactive analytics service for analyzing the data in Amazon Simple Storage Service (Amazon S3). Amazon Redshift is used to analyze structured and semi-structureddata across data warehouses, operational databases, and data lakes. The solution architecture and workflow.
Snowflake is the data cloud that boasts instant elasticity, secure data sharing and per-second pricing across multiple clouds. Its ability to natively load and use SQL to query semi-structured and structureddata within a single system simplifies your data engineering. Learn about current trends.
In this article, we’ll dig into what data modeling is, provide some best practices for setting up your data model, and walk through a handy way of thinking about data modeling that you can use when building your own. Building the right data model is an important part of your datastrategy. Discover why.
You can also use the datatransformation feature of Data Firehose to invoke a Lambda function to perform datatransformation in batches. Query the data using Athena Athena is a serverless, interactive analytics service built to analyze unstructured, semi-structured, and structureddata where it is hosted.
You can use AWS Glue Studio to create jobs that extract structured or semi-structureddata from a data source, perform a transformation of that data, and save the result set in a data target. This concludes creating data sources on the AWS Glue job canvas. Under Transforms , choose SQL Query.
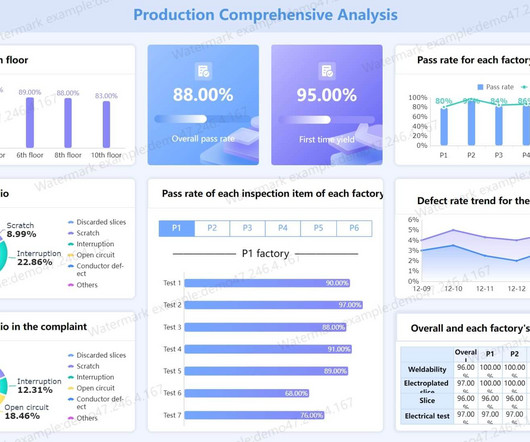
Data Analysis Report (by FineReport ) Note: All the data analysis reports in this article are created using the FineReport reporting tool. Leveraging the advanced enterprise-level web reporting tool capabilities of FineReport , we empower businesses to achieve genuine datatransformation. Try FineReport Now 1.
Storing the same data in multiple places can lead to: Human error: mistakes when transcribing data reduce its quality and integrity. Multiple datastructures: different departments use distinct technologies and datastructures. Data governance is the solution to these challenges. Reduce audit times.
Data Extraction : The process of gathering data from disparate sources, each of which may have its own schema defining the structure and format of the data and making it available for processing. This can include tasks such as data ingestion, cleansing, filtering, aggregation, or standardization.
With Simba drivers acting as a bridge between Trino and your BI or ETL tools, you can unlock enhanced data connectivity, streamline analytics, and drive real-time decision-making. Let’s explore why this combination is a game-changer for datastrategies and how it maximizes the value of Trino and Apache Iceberg for your business.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content