This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Now with Amazon Bedrock Knowledge Bases integration with structured data, you can use simple, natural language prompts to query complex financial datasets. From customer portals to internal dashboards and mobile apps, this API-driven approach makes enterprise-grade data analysis accessible to everyone in your organization.
BladeBridge offers a comprehensive suite of tools that automate much of the complex conversion work, allowing organizations to quickly and reliably transition their data analytics capabilities to the scalable Amazon Redshift datawarehouse. times better price performance than other cloud datawarehouses.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze your data using standard SQL and your existing business intelligence (BI) tools. Data ingestion is the process of getting data to Amazon Redshift.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that lets you analyze your data at scale. Amazon Redshift Serverless lets you access and analyze data without the usual configurations of a provisioned datawarehouse. For more information, refer to Amazon Redshift clusters.
Amazon AppFlow automatically encrypts data in motion, and allows you to restrict data from flowing over the public internet for SaaS applications that are integrated with AWS PrivateLink , reducing exposure to security threats. Refer to the Amazon Redshift Database Developer Guide for more details. Select demo-google-aws.
Unifying these necessitates additional data processing, requiring each business unit to provision and maintain a separate datawarehouse. This burdens business units focused solely on consuming the curated data for analysis and not concerned with data management tasks, cleansing, or comprehensive data processing.
This puts tremendous stress on the teams managing datawarehouses, and they struggle to keep up with the demand for increasingly advanced analytic requests. To gather and clean data from all internal systems and gain the business insights needed to make smarter decisions, businesses need to invest in datawarehouse automation.
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud that delivers powerful and secure insights on all your data with the best price-performance. With Amazon Redshift, you can analyze your data to derive holistic insights about your business and your customers.
Whether the reporting is being done by an end user, a data science team, or an AI algorithm, the future of your business depends on your ability to use data to drive better quality for your customers at a lower cost. So, when it comes to collecting, storing, and analyzing data, what is the right choice for your enterprise?
Tens of thousands of customers use Amazon Redshift for modern data analytics at scale, delivering up to three times better price-performance and seven times better throughput than other cloud datawarehouses. Refer to IAM Identity Center identity source tutorials for the IdP setup. IAM Identity Center enabled.
Load generic address data to Amazon Redshift Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud. Redshift Serverless makes it straightforward to run analytics workloads of any size without having to manage datawarehouse infrastructure.
Amazon Redshift has established itself as a highly scalable, fully managed cloud datawarehouse trusted by tens of thousands of customers for its superior price-performance and advanced data analytics capabilities. This allows you to maintain a comprehensive view of your data while optimizing for cost-efficiency.
The current scaling approach of Amazon Redshift Serverless increases your compute capacity based on the query queue time and scales down when the queuing reduces on the datawarehouse. This post also includes example SQLs, which you can run on your own Redshift Serverless datawarehouse to experience the benefits of this feature.
and zero-ETL support) as the source, and a Redshift datawarehouse as the target. The integration replicates data from the source database into the target datawarehouse. Refer to Connect to an Aurora PostgreSQL DB cluster for the options to connect to the PostgreSQL cluster. Choose Next.
Amazon Redshift is a fully managed, scalable cloud datawarehouse that accelerates your time to insights with fast, easy, and secure analytics at scale. Tens of thousands of customers rely on Amazon Redshift to analyze exabytes of data and run complex analytical queries, making it the widely used cloud datawarehouse.
Amazon Redshift is a widely used, fully managed, petabyte-scale cloud datawarehouse. Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytic workloads. For more information, refer to Migrate Google BigQuery to Amazon Redshift using AWS Schema Conversion tool (SCT).
New feature: Custom AWS service blueprints Previously, Amazon DataZone provided default blueprints that created AWS resources required for data lake, datawarehouse, and machine learning use cases. If you’re new to Amazon DataZone, refer to Getting started.
The extract, transform, and load (ETL) process has been a common pattern for moving data from an operational database to an analytics datawarehouse. ELT is where the extracted data is loaded as is into the target first and then transformed. Refer to Zero-ETL integration costs (Preview) for further details.
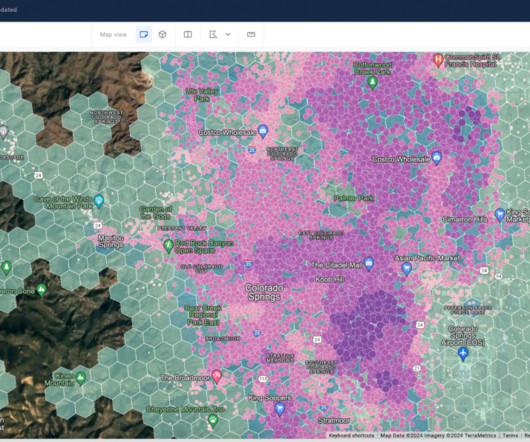
Traditionally, spatial data is represented through a geography or geometry in which features are geolocated on the earth by a long reference string describing the coordinates of every vertex. Indexed data can be quickly joined across different datasets and aggregated at different levels of precision. But what makes them special?
dbt is an open source, SQL-first templating engine that allows you to write repeatable and extensible data transforms in Python and SQL. dbt is predominantly used by datawarehouses (such as Amazon Redshift ) customers who are looking to keep their data transform logic separate from storage and engine.
The Analytics specialty practice of AWS Professional Services (AWS ProServe) helps customers across the globe with modern data architecture implementations on the AWS Cloud. The company wanted the ability to continue processing operational data in the secondary Region in the rare event of primary Region failure.
For more details, refer to the What’s New Post. There are two broad approaches to analyzing operational data for these use cases: Analyze the data in-place in the operational database (e.g. For this illustration, we use a provisioned Aurora database and an Amazon Redshift Serverless datawarehouse.
Cloudera and Accenture demonstrate strength in their relationship with an accelerator called the Smart Data Transition Toolkit for migration of legacy datawarehouses into Cloudera Data Platform. Accenture’s Smart Data Transition Toolkit . Are you looking for your datawarehouse to support the hybrid multi-cloud?
For example, manually managing data mappings for the enterprise datawarehouse via MS Excel spreadsheets had become cumbersome and unsustainable for one BSFI company. Additionally, they were able to more easily manage mappings, code sets, referencedata and data validation rules.
Tens of thousands of customers rely on Amazon Redshift to analyze exabytes of data and run complex analytical queries. You can use your preferred SQL clients to analyze your data in an Amazon Redshift datawarehouse. For this demo, we log in with user Ethan.
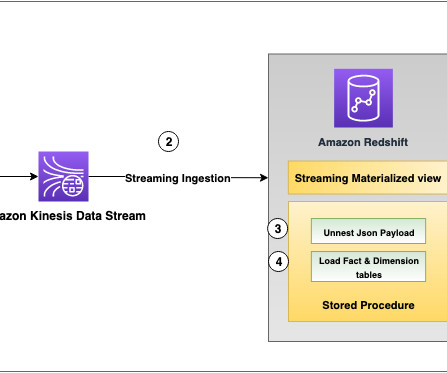
Before proceeding with the demo, create a folder named custdata under the created S3 bucket. Create a Kinesis data stream We use Kinesis Data Streams to create a serverless streaming data service that is built to handle millions of events with low latency. Select Kinesis Data Streams and choose Create data stream.
Amazon DataZone is a powerful data management service that empowers data engineers, data scientists, product managers, analysts, and business users to seamlessly catalog, discover, analyze, and govern data across organizational boundaries, AWS accounts, data lakes, and datawarehouses.
Given the value this sort of data-driven insight can provide, the reason organizations need a data catalog should become clearer. It’s no surprise that most organizations’ data is often fragmented and siloed across numerous sources (e.g., Request your own demo of erwin DI. The post Do I Need a Data Catalog?
Amazon Redshift is a petabyte-scale, enterprise-grade cloud datawarehouse service delivering the best price-performance. Today, tens of thousands of customers run business-critical workloads on Amazon Redshift to cost-effectively and quickly analyze their data using standard SQL and existing business intelligence (BI) tools.
Amazon Redshift is a fast, fully managed, petabyte-scale datawarehouse service that makes it simple and cost-effective to analyze all your data efficiently and securely. Users such as data analysts, database developers, and data scientists use SQL to analyze their data in Amazon Redshift datawarehouses.
Its solution was to replicate data from the production database, using data entities, into a traditional relational database. Microsoft referred to this approach as “bring your own database” (BYOD). For more sophisticated multidimensional reporting functions, however, a more advanced approach to staging data is required.
Confusing matters further, Microsoft has also created something called the Data Entity Store, which serves a different purpose and functions independently of data entities. The Data Entity Store is an internal datawarehouse that is only available to embedded Power BI reports (not the full version of Power BI).
Satori integrates natively with both Amazon Redshift provisioned clusters and Amazon Redshift Serverless for easy setup of your Amazon Redshift datawarehouse in the secure Satori portal. In part 2, we will explore how to set up self-service data access with Satori to data stored in Amazon Redshift.
Data lakes are not transactional by default; however, there are multiple open-source frameworks that enhance data lakes with ACID properties, providing a best of both worlds solution between transactional and non-transactional storage mechanisms. The referencedata is continuously replicated from MySQL to DynamoDB through AWS DMS.
AWS ran a live demo to show how to get started in just a few clicks. Can Amazon RDS for Db2 be used for running data warehousing workloads? Answer : Yes, Amazon RDS for Db2 can support analytics workloads, but it is not a datawarehouse. Amazon RDS Scalability 5. 13.
In a modern data architecture, unified analytics enable you to access the data you need, whether it’s stored in a data lake or a datawarehouse. One of the most common use cases for data preparation on Amazon Redshift is to ingest and transform data from different data stores into an Amazon Redshift datawarehouse.
Overlaying refers to the process of inserting custom programming directly into Microsoft’s source code. In a separate blog post, we discussed the potential for using a datawarehouse as a means for automating data extraction and transformation in advance of system migration.
Determine the source of the data . Which database are the data from? Enterprise datawarehouse? What database tables are the data from? Here, you can refer to the Top 16 Types of Chart in Data Visualization or Top 7 Most Common Data Visualization Types: How to Choose and Design to select the proper charts.
The solution contains a prebuilt automotive demo that we can use to begin delivering sensor data quickly to AWS. Choose Automotive Demo. For Simulation type , choose Automotive Demo. For Select a device type , choose the demo device you created. We reference the environment variable st_env. Choose Save.
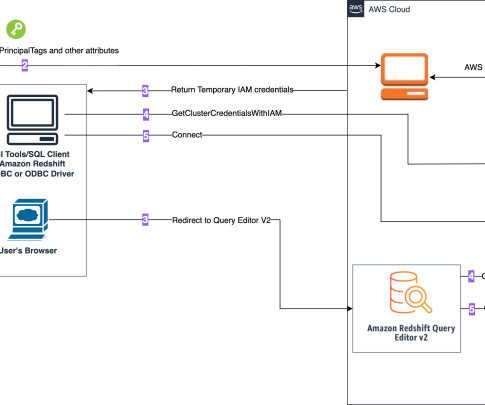
You might be modernizing your data architecture using Amazon Redshift to enable access to your data lake and data in your datawarehouse, and are looking for a centralized and scalable way to define and manage the data access based on IdP identities. Choose Register location. Choose Register location.
S3FileIO" } } This sets the following Spark session configurations: spark.sql.catalog.demo – Registers a Spark catalog named demo, which uses the Iceberg Spark catalog plugin. spark.sql.catalog.demo.catalog-impl – The demo Spark catalog uses AWS Glue as the physical catalog to store Iceberg database and table information.
With full and CDC data in separate S3 folders, it’s easier to maintain and operate data replication and downstream processing jobs. Create a database with the following code: CREATE DATABASE raw_demo; Next, create a folder in an S3 bucket that you can use for this demo. Navigate to the Athena console and choose Query editor.
Amazon Redshift Serverless makes it easy to run and scale analytics in seconds without the need to set up and manage datawarehouse clusters. Customers use their preferred SQL clients to analyze their data in Redshift Serverless. An Redshift Serverless datawarehouse. For this demo, we log in with user Ethan.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content