This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In fact, by putting a single label like AI on all the steps of a data-driven business process, we have effectively not only blurred the process, but we have also blurred the particular characteristics that make each step separately distinct, uniquely critical, and ultimately dependent on specialized, specific technologies at each step.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze your data using standard SQL and your existing business intelligence (BI) tools. Data ingestion is the process of getting data to Amazon Redshift.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. or a later version) database.
Common use cases for using the dbt adapter with Athena The following are common use cases for using the dbt adapter with Athena: Building a datawarehouse – Many organizations are moving towards a datawarehouse architecture, combining the flexibility of data lakes with the performance and structure of datawarehouses.
You can now generate data integration jobs for various data sources and destinations, including Amazon Simple Storage Service (Amazon S3) data lakes with popular file formats like CSV, JSON, and Parquet, as well as modern table formats such as Apache Hudi , Delta , and Apache Iceberg.
Each data source is updated on its own schedule, for example, daily, weekly or monthly. The DataKitchen Platform ingests data into a data lake and runs Recipes to create a datawarehouse leveraged by users and self-service data analysts. The third set of domains are cached data sets (e.g., Conclusion.
Whether the reporting is being done by an end user, a data science team, or an AI algorithm, the future of your business depends on your ability to use data to drive better quality for your customers at a lower cost. So, when it comes to collecting, storing, and analyzing data, what is the right choice for your enterprise?
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. Solution overview Amazon Redshift is an industry-leading cloud datawarehouse.
As part of its storytelling ethos, the flight-status LLM will specify, for example, which precise weather event may be affecting a delayed flight and provide quick and useful information to customers about next actions.
TIBCO is a large, independent cloud-computing and data analytics software company that offers integration, analytics, business intelligence and events processing software. It enables organizations to analyze streaming data in real time and provides the capability to automate analytics processes.
One of the major and essential parts in a datawarehouse is the extract, transform, and load (ETL) process which extracts the data from different sources, applies business rules and aggregations and then makes the transformed data available for the business users.
The world’s an eventful place, isn’t it? When we say ‘eventful’, we mean, there are some many things happening around the world, every day, every minute, and they are all happening as glamorous, lavish and big events – be it a phone launch, a mega concert, fairs and so on. Who’s coming?
Interestingly, you can address many of them very effectively with a datawarehouse. In the event you have to look up an old sales order, the old system is always there as a resource for looking at historical information…until it isn’t. The DataWarehouse Solution. You just need to be able to look things up.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that you can use to analyze your data at scale. Building event-driven applications with Amazon EventBridge and Lambda. Scheduling SQL scripts to simplify data load, unload, and refresh of materialized views.
These types of queries are suited for a datawarehouse. The goal of a datawarehouse is to enable businesses to analyze their data fast; this is important because it means they are able to gain valuable insights in a timely manner. Amazon Redshift is fully managed, scalable, cloud datawarehouse.
They must also select the data processing frameworks such as Spark, Beam or SQL-based processing and choose tools for ML. Based on business needs and the nature of the data, raw vs structured, organizations should determine whether to set up a datawarehouse, a Lakehouse or consider a data fabric technology.
Today’s customers have a growing need for a faster end to end data ingestion to meet the expected speed of insights and overall business demand. This ‘need for speed’ drives a rethink on building a more modern datawarehouse solution, one that balances speed with platform cost management, performance, and reliability.
Amazon AppFlow is a fully managed integration service that you can use to securely transfer data from software as a service (SaaS) applications, such as Google BigQuery, Salesforce, SAP, HubSpot, and ServiceNow, to Amazon Web Services (AWS) services such as Amazon Simple Storage Service (Amazon S3) and Amazon Redshift, in just a few clicks.
Enterprise datawarehouse platform owners face a number of common challenges. In this article, we look at seven challenges, explore the impacts to platform and business owners and highlight how a modern datawarehouse can address them. ETL jobs and staging of data often often require large amounts of resources.
Complex queries, on the other hand, refer to large-scale data processing and in-depth analysis based on petabyte-level datawarehouses in massive data scenarios. AWS Glue crawler crawls data lake information from Amazon S3, generating a Data Catalog to support dbt on Amazon Athena data modeling.
This post was co-written with Dipankar Mazumdar, Staff Data Engineering Advocate with AWS Partner OneHouse. Data architecture has evolved significantly to handle growing data volumes and diverse workloads. For a table that will be converted, it invokes the converter Lambda function through an event.
I recently had the honor of delivering the keynote at the “The Journey to the Top” Event at SAP UK headquarters, and you can see my slides and a video in my previous post How Data is Powering The Future of Business: Trends and Opportunities. People, collaboration, and ease of use.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud that delivers powerful and secure insights on all your data with the best price-performance. With Amazon Redshift, you can analyze your data to derive holistic insights about your business and your customers.
It was not until the addition of open table formats— specifically Apache Hudi, Apache Iceberg and Delta Lake—that data lakes truly became capable of supporting multiple business intelligence (BI) projects as well as data science and even operational applications and, in doing so, began to evolve into data lakehouses.
ActionIQ is a leading composable customer data (CDP) platform designed for enterprise brands to grow faster and deliver meaningful experiences for their customers. This post will demonstrate how ActionIQ built a connector for Amazon Redshift to tap directly into your datawarehouse and deliver a secure, zero-copy CDP.
Amazon Redshift is the most widely used datawarehouse in the cloud, best suited for analyzing exabytes of data and running complex analytical queries. Amazon QuickSight is a fast business analytics service to build visualizations, perform ad hoc analysis, and quickly get business insights from your data.
FQL also delivers native support for queries requiring joins of data across multiple documents as well as user-defined functions. The emergence of intelligent applications does not eradicate the use of specialist analytic data platforms, such as datawarehouses and data lakehouses.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing ETL (extract, transform, and load), business intelligence (BI), and reporting tools.
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
Users today are asking ever more from their datawarehouse. As an example of this, in this post we look at Real Time Data Warehousing (RTDW), which is a category of use cases customers are building on Cloudera and which is becoming more and more common amongst our customers. Ingest 100s of TB of network eventdata per day .
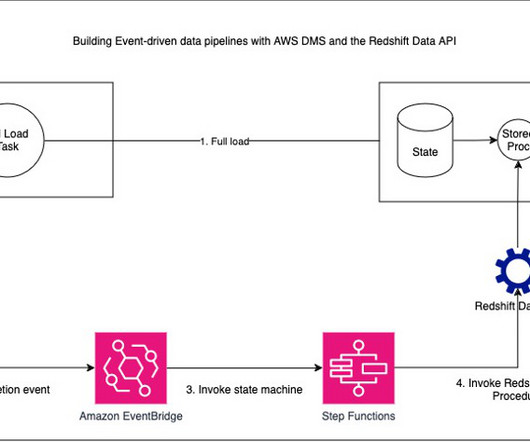
Diagram 1: Overall architecture of the solution, using AWS Step Functions, Amazon Redshift and Amazon S3 The following AWS services were used to shape our new ETL architecture: Amazon Redshift A fully managed, petabyte-scale datawarehouse service in the cloud. The following Diagram 4 shows this workflow.
In particular, the company made several announcements at its Snowflake Summit 2024 customer event in June that highlighted considerable advancements to its capabilities in relation to AI and GenAI. Snowflake was founded in 2012 to build a business around its cloud-based datawarehouse with built-in data-sharing capabilities.
About Redshift and some relevant features for the use case Amazon Redshift is a fully managed, petabyte-scale, massively parallel datawarehouse that offers simple operations and high performance. It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools.
Investment in datawarehouses is rapidly rising, projected to reach $51.18 billion by 2028 as the technology becomes a vital cog for enterprises seeking to be more data-driven by using advanced analytics. Datawarehouses are, of course, no new concept. More data, more demanding. “As
Currently, a handful of startups offer “reverse” extract, transform, and load (ETL), in which they copy data from a customer’s datawarehouse or data platform back into systems of engagement where business users do their work. Sharing Customer 360 insights back without data replication.
This premier event showcased groundbreaking advancements, keynotes from AWS leadership, hands-on technical sessions, and exciting product launches. Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights.
A CDC-based approach captures the data changes and makes them available in datawarehouses for further analytics in real-time. usually a datawarehouse) needs to reflect those changes in near real-time. This post showcases how to use streaming ingestion to bring data to Amazon Redshift.
Amazon Redshift is a fast, petabyte-scale, cloud datawarehouse that tens of thousands of customers rely on to power their analytics workloads. With its massively parallel processing (MPP) architecture and columnar data storage, Amazon Redshift delivers high price-performance for complex analytical queries against large datasets.
A DSS leverages a combination of raw data, documents, personal knowledge, and/or business models to help users make decisions. The data sources used by a DSS could include relational data sources, cubes, datawarehouses, electronic health records (EHRs), revenue projections, sales projections, and more.
As technology continues to evolve, one specific facet of this journey is reaching unprecedented proportions: geospatial data. With Amazon Redshift, you can get real-time insights and predictive analytics on all of your data across your operational databases, data lake, datawarehouse, and third-party datasets.
“We moved our major data platforms to the cloud and implemented data hubs for Customer and Operations,” Mohan says. Mohan notes that her team simultaneously created DataOps frameworks that have improved the airline’s ability to ingest and consume new data sources in a matter of hours rather than weeks.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud. You can start with just a few hundred gigabytes of data and scale to a petabyte or more. This enables you to use your data to acquire new insights for your business and customers. Document the entire disaster recovery process.
The recent announcement of the Microsoft Intelligent Data Platform makes that more obvious, though analytics is only one part of that new brand. Azure Data Factory. Azure Data Lake Analytics. Datawarehouses are designed for questions you already know you want to ask about your data, again and again.
During that same time, AWS has been focused on helping customers manage their ever-growing volumes of data with tools like Amazon Redshift , the first fully managed, petabyte-scale cloud datawarehouse. One group performed extract, transform, and load (ETL) operations to take raw data and make it available for analysis.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content