This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In fact, by putting a single label like AI on all the steps of a data-driven business process, we have effectively not only blurred the process, but we have also blurred the particular characteristics that make each step separately distinct, uniquely critical, and ultimately dependent on specialized, specific technologies at each step.
This post was co-written with Dipankar Mazumdar, Staff Data Engineering Advocate with AWS Partner OneHouse. Data architecture has evolved significantly to handle growing data volumes and diverse workloads. The synchronization process in XTable works by translating table metadata using the existing APIs of these table formats.
An extract, transform, and load (ETL) process using AWS Glue is triggered once a day to extract the required data and transform it into the required format and quality, following the data product principle of data mesh architectures. From here, the metadata is published to Amazon DataZone by using AWS Glue Data Catalog.
These nodes can implement analytical platforms like data lake houses, datawarehouses, or data marts, all united by producing data products. The Institutional Data & AI platform adopts a federated approach to data while centralizing the metadata to facilitate simpler discovery and sharing of data products.
This premier event showcased groundbreaking advancements, keynotes from AWS leadership, hands-on technical sessions, and exciting product launches. Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights.
We also examine how centralized, hybrid and decentralized data architectures support scalable, trustworthy ecosystems. As data-centric AI, automated metadata management and privacy-aware data sharing mature, the opportunity to embed data quality into the enterprises core has never been more significant.
Currently, a handful of startups offer “reverse” extract, transform, and load (ETL), in which they copy data from a customer’s datawarehouse or data platform back into systems of engagement where business users do their work. It works in Salesforce just like any other native Salesforce data,” Carlson said.
Amazon Redshift is a fast, petabyte-scale, cloud datawarehouse that tens of thousands of customers rely on to power their analytics workloads. With its massively parallel processing (MPP) architecture and columnar data storage, Amazon Redshift delivers high price-performance for complex analytical queries against large datasets.
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
It was not until the addition of open table formats— specifically Apache Hudi, Apache Iceberg and Delta Lake—that data lakes truly became capable of supporting multiple business intelligence (BI) projects as well as data science and even operational applications and, in doing so, began to evolve into data lakehouses.
Today’s customers have a growing need for a faster end to end data ingestion to meet the expected speed of insights and overall business demand. This ‘need for speed’ drives a rethink on building a more modern datawarehouse solution, one that balances speed with platform cost management, performance, and reliability.
Enterprises and organizations across the globe want to harness the power of data to make better decisions by putting data at the center of every decision-making process. However, throughout history, data services have held dominion over their customers’ data. This concept makes Iceberg extremely versatile.
ActionIQ is a leading composable customer data (CDP) platform designed for enterprise brands to grow faster and deliver meaningful experiences for their customers. This post will demonstrate how ActionIQ built a connector for Amazon Redshift to tap directly into your datawarehouse and deliver a secure, zero-copy CDP.
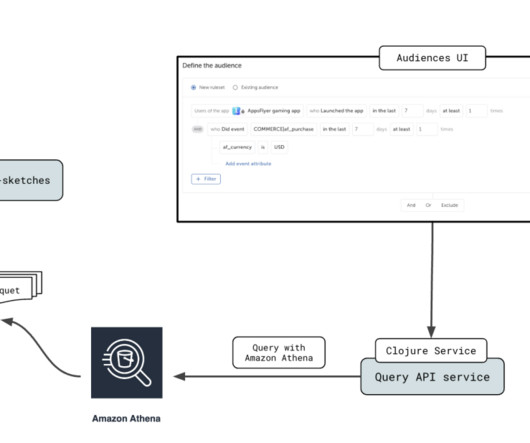
AppsFlyer develops a leading measurement solution focused on privacy, which enables marketers to gauge the effectiveness of their marketing activities and integrates them with the broader marketing world, managing a vast volume of 100 billion events every day. This led the team to examine partition indexing.
Another hypothesis: Databricks execs were billion-dollar stoked to stick it to Snowflake by drowning out its event with a buyout its rival reportedly sought. The data catalog is critical because it’s where business manages its metadata,” said Venkat Rajaji, Senior Vice President of Product Management at Cloudera.
Some solutions provide read and write access to any type of source and information, advanced integration, security capabilities and metadata management that help achieve virtual and high-performance Data Services in real-time, cache or batch mode. How does Data Virtualization complement Data Warehousing and SOA Architectures?
But whatever their business goals, in order to turn their invisible data into a valuable asset, they need to understand what they have and to be able to efficiently find what they need. Enter metadata. It enables us to make sense of our data because it tells us what it is and how best to use it. Knowledge (metadata) layer.
It covers how to use a conceptual, logical architecture for some of the most popular gaming industry use cases like event analysis, in-game purchase recommendations, measuring player satisfaction, telemetry data analysis, and more. Data lakes are more focused around storing and maintaining all the data in an organization in one place.
Cloudera and Accenture demonstrate strength in their relationship with an accelerator called the Smart Data Transition Toolkit for migration of legacy datawarehouses into Cloudera Data Platform. Accenture’s Smart Data Transition Toolkit . Are you looking for your datawarehouse to support the hybrid multi-cloud?
Amazon Redshift is a widely used, fully managed, petabyte-scale cloud datawarehouse. Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytic workloads. This JSON file contains the migration metadata, namely the following: A list of Google BigQuery projects and datasets.
Source systems Aruba’s source repository includes data from three different operating regions in AMER, EMEA, and APJ, along with one worldwide (WW) data pipeline from varied sources like SAP S/4 HANA, Salesforce, Enterprise DataWarehouse (EDW), Enterprise Analytics Platform (EAP) SharePoint, and more.
An Amazon DataZone domain contains an associated business data catalog for search and discovery, a set of metadata definitions to decorate the data assets that are used for discovery purposes, and data projects with integrated analytics and ML tools for users and groups to consume and publish data assets.
It also makes it easier for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization to discover, use, and collaborate to derive data-driven insights. The producer also needs to manage and publish the data asset so it’s discoverable throughout the organization.
While cloud-native, point-solution datawarehouse services may serve your immediate business needs, there are dangers to the corporation as a whole when you do your own IT this way. Cloudera DataWarehouse (CDW) is here to save the day! CDW is an integrated datawarehouse service within Cloudera Data Platform (CDP).
The first blog introduced a mock connected vehicle manufacturing company, The Electric Car Company (ECC), to illustrate the manufacturing data path through the data lifecycle. Having completed the Data Collection step in the previous blog, ECC’s next step in the data lifecycle is Data Enrichment.
Data engineers use Apache Iceberg because it’s fast, efficient, and reliable at any scale and keeps records of how datasets change over time. Apache Iceberg offers integrations with popular data processing frameworks such as Apache Spark, Apache Flink, Apache Hive, Presto, and more.
Amazon Redshift is a fully managed, scalable cloud datawarehouse that accelerates your time to insights with fast, easy, and secure analytics at scale. Tens of thousands of customers rely on Amazon Redshift to analyze exabytes of data and run complex analytical queries, making it the widely used cloud datawarehouse.
We are also building models trained on different types of business data, including code, time-series data, tabular data, geospatial data and IT eventsdata. With watsonx.data , businesses can quickly connect to data, get trusted insights and reduce datawarehouse costs.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud. You can start with just a few hundred gigabytes of data and scale to a petabyte or more. This enables you to use your data to acquire new insights for your business and customers. Document the entire disaster recovery process.
Amazon Redshift is a popular cloud datawarehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
In other words, using metadata about data science work to generate code. In this case, code gets generated for data preparation, where so much of the “time and labor” in data science work is concentrated. Less data gets decompressed, deserialized, loaded into memory, run through the processing, etc.
This solution only replicates metadata in the Data Catalog, not the actual underlying data. To have a redundant data lake using Lake Formation and AWS Glue in an additional Region, we recommend replicating the Amazon S3-based storage using S3 replication , S3 sync, aws-s3-copy-sync-using-batch or S3 Batch replication process.
The Analytics specialty practice of AWS Professional Services (AWS ProServe) helps customers across the globe with modern data architecture implementations on the AWS Cloud. For example, to create source-aligned datasets in the data lake for 3,000 operational tables, the company didn’t want to deploy 3,000 separate data processing jobs.
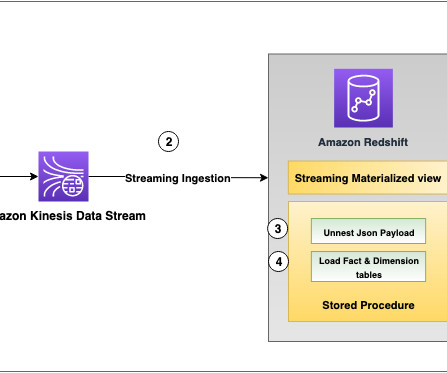
It aims to provide a framework to create low-latency streaming applications on the AWS Cloud using Amazon Kinesis Data Streams and AWS purpose-built data analytics services. In this post, we will review the common architectural patterns of two use cases: Time Series Data Analysis and Event Driven Microservices.
Data in Place refers to the organized structuring and storage of data within a specific storage medium, be it a database, bucket store, files, or other storage platforms. In the contemporary data landscape, data teams commonly utilize datawarehouses or lakes to arrange their data into L1, L2, and L3 layers.
With quality data at their disposal, organizations can form datawarehouses for the purposes of examining trends and establishing future-facing strategies. Industry-wide, the positive ROI on quality data is well understood. 2 – Data profiling. Data profiling is an essential process in the DQM lifecycle.
In this blog, we will discuss performance improvement that Cloudera has contributed to the Apache Iceberg project in regards to Iceberg metadata reads, and we’ll showcase the performance benefit using Apache Impala as the query engine. Impala can access Hive table metadata fast because HMS is backed by RDBMS, such as mysql or postgresql.
To speed up the self-service analytics and foster innovation based on data, a solution was needed to provide ways to allow any team to create data products on their own in a decentralized manner. To create and manage the data products, smava uses Amazon Redshift , a cloud datawarehouse.
You also need services to store data for analysis and machine learning (ML) like Amazon Simple Storage Service (Amazon S3). Customers have created hundreds of thousands of data lakes on Amazon S3. Within seconds of data being written into Aurora, you can use Amazon Redshift to do near-real-time analytics and ML on petabytes of data.
While these instructions are carried out for Cloudera Data Platform (CDP), Cloudera Data Engineering, and Cloudera DataWarehouse, one can extrapolate them easily to other services and other use cases as well. In all the use cases we are trying to migrate a table named “events.”
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a data lake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale. The following table summarizes the features.
To achieve this, first requires getting the data into a form that delivers insights. Salesforce data is extracted, transformed and loaded into a datawarehouse using an ETL tool connected to the datawarehouse. Then, use a data model to model the data into a single unified source of truth.
Datawarehouses play a vital role in healthcare decision-making and serve as a repository of historical data. A healthcare datawarehouse can be a single source of truth for clinical quality control systems. What is a dimensional data model? What is a dimensional data model? What is a data vault?
For example, in a chatbot, dataevents could pertain to an inventory of flights and hotels or price changes that are constantly ingested to a streaming storage engine. Furthermore, dataevents are filtered, enriched, and transformed to a consumable format using a stream processor.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content