This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Additionally, as I recently explained , the companys platform addresses a broad range of capabilities that includes data governance and security, data integration and application development, as well as the automation and incorporation of artificial intelligence (AI) and machine learning (ML) models into BI and analytics.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze your data using standard SQL and your existing business intelligence (BI) tools. Data ingestion is the process of getting data to Amazon Redshift.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. or a later version) database.
Furthermore, you can gain insights into the performance of your data transformations with detailed execution logs and metrics, all accessible through the dbt Cloud interface. Using Athena and the dbt adapter, you can transform raw data in Amazon S3 into well-structured tables suitable for analytics.
1) What Is Data Quality Management? 4) Data Quality Best Practices. 5) How Do You Measure Data Quality? 6) Data Quality Metrics Examples. 7) Data Quality Control: Use Case. 8) The Consequences Of Bad Data Quality. 9) 3 Sources Of Low-Quality Data. 10) Data Quality Solutions: Key Attributes.
Amazon AppFlow is a fully managed integration service that you can use to securely transfer data from software as a service (SaaS) applications, such as Google BigQuery, Salesforce, SAP, HubSpot, and ServiceNow, to Amazon Web Services (AWS) services such as Amazon Simple Storage Service (Amazon S3) and Amazon Redshift, in just a few clicks.
Whether the reporting is being done by an end user, a data science team, or an AI algorithm, the future of your business depends on your ability to use data to drive better quality for your customers at a lower cost. So, when it comes to collecting, storing, and analyzing data, what is the right choice for your enterprise?
Co-author: Mike Godwin, Head of Marketing, Rill Data. Cloudera has partnered with Rill Data, an expert in metrics at any scale, as Cloudera’s preferred ISV partner to provide technical expertise and support services for Apache Druid customers. Deploying metrics shouldn’t be so hard. Cloudera DataWarehouse).
AWS Glue Data Quality allows you to measure and monitor the quality of data in your data repositories. It’s important for business users to be able to see quality scores and metrics to make confident business decisions and debug data quality issues. An AWS Glue crawler crawls the results.
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
About Redshift and some relevant features for the use case Amazon Redshift is a fully managed, petabyte-scale, massively parallel datawarehouse that offers simple operations and high performance. It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools.
The extract, transform, and load (ETL) process has been a common pattern for moving data from an operational database to an analytics datawarehouse. ELT is where the extracted data is loaded as is into the target first and then transformed. ETL and ELT pipelines can be expensive to build and complex to manage.
and zero-ETL support) as the source, and a Redshift datawarehouse as the target. The integration replicates data from the source database into the target datawarehouse. Additionally, you can choose the capacity, to limit the compute resources of the datawarehouse. For this post, set this to 8 RPUs.
There are two broad approaches to analyzing operational data for these use cases: Analyze the data in-place in the operational database (e.g. With Aurora zero-ETL integration with Amazon Redshift, the integration replicates data from the source database into the target datawarehouse. or higher version) database.
AWS Database Migration Service (AWS DMS) is used to securely transfer the relevant data to a central Amazon Redshift cluster. The data in the central datawarehouse in Amazon Redshift is then processed for analytical needs and the metadata is shared to the consumers through Amazon DataZone.
It covers how to use a conceptual, logical architecture for some of the most popular gaming industry use cases like event analysis, in-game purchase recommendations, measuring player satisfaction, telemetry data analysis, and more. Data lakes are more focused around storing and maintaining all the data in an organization in one place.
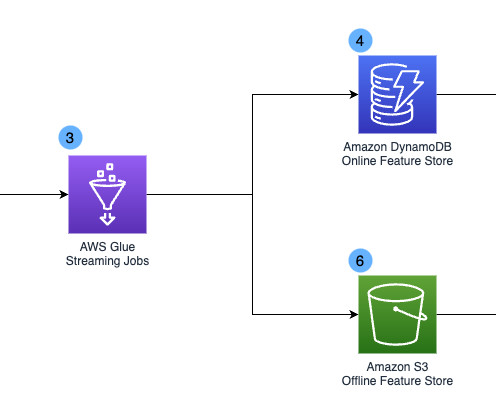
Real-time AI brings together streaming data and machine learning algorithms to make fast and automated decisions; examples include recommendations, fraud detection, security monitoring, and chatbots. The underpinning architecture needs to include event-streaming technology, high-performing databases, and machine learning feature stores.
Data in Place refers to the organized structuring and storage of data within a specific storage medium, be it a database, bucket store, files, or other storage platforms. In the contemporary data landscape, data teams commonly utilize datawarehouses or lakes to arrange their data into L1, L2, and L3 layers.
It automatically provisions and intelligently scales datawarehouse compute capacity to deliver fast performance, and you pay only for what you use. Just load your data and start querying right away in the Amazon Redshift Query Editor or in your favorite business intelligence (BI) tool. Open the workgroup you want to monitor.
Power BI is Microsoft’s interactive data visualization and analytics tool for business intelligence (BI). With Power BI, you can pull data from almost any data source and create dashboards that track the metrics you care about the most. You can also create manual metrics to update yourself.
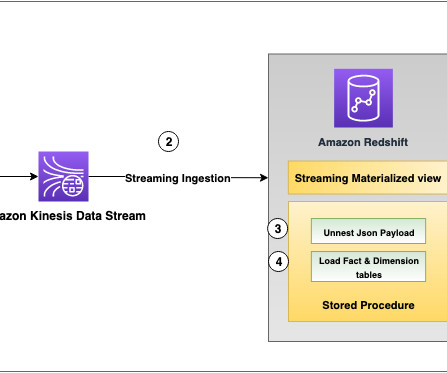
This stack creates the following resources and necessary permissions to integrate the services: Data stream – With Amazon Kinesis Data Streams , you can send data from your streaming source to a data stream to ingest the data into a Redshift datawarehouse. version cluster. version cluster.
Managing large-scale datawarehouse systems has been known to be very administrative, costly, and lead to analytic silos. The good news is that Snowflake, the cloud data platform, lowers costs and administrative overhead. When did you begin a technology partnership with Snowflake and why?
This premier event showcased groundbreaking advancements, keynotes from AWS leadership, hands-on technical sessions, and exciting product launches. Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights.
Stream processing, however, can enable the chatbot to access real-time data and adapt to changes in availability and price, providing the best guidance to the customer and enhancing the customer experience. When the model finds an anomaly or abnormal metric value, it should immediately produce an alert and notify the operator.
The application supports custom workflows to allow demand and supply planning teams to collaborate, plan, source, and fulfill customer orders, then track fulfillment metrics via persona-based operational and management reports and dashboards. To achieve this, Aruba used Amazon S3 Event Notifications.
These nodes can implement analytical platforms like data lake houses, datawarehouses, or data marts, all united by producing data products. For instance, one enhancement involves integrating cross-functional squads to support data literacy.
Problem statement In order to keep up with the rapid movement of fraudsters, our decision platform must continuously monitor user events and respond in real-time. However, our legacy datawarehouse-based solution was not equipped for this challenge. Amazon DynamoDB is another data source for our Streaming 2.0
To run analytics on your operational data, you might build a solution that is a combination of a database, a datawarehouse, and an extract, transform, and load (ETL) pipeline. ETL is the process data engineers use to combine data from different sources.
Amazon Redshift is a popular cloud datawarehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
It aims to provide a framework to create low-latency streaming applications on the AWS Cloud using Amazon Kinesis Data Streams and AWS purpose-built data analytics services. In this post, we will review the common architectural patterns of two use cases: Time Series Data Analysis and Event Driven Microservices.
Federated queries allow querying data across Amazon RDS for MySQL and PostgreSQL data sources without the need for extract, transform, and load (ETL) pipelines. If storing operational data in a datawarehouse is a requirement, synchronization of tables between operational data stores and Amazon Redshift tables is supported.
We’ve all experienced the pain of what continues to happen with the disconnect between customer usage metrics and gaps in supply chain data.” — Frank Cutitta ( @fcutitta ), CEO and Founder, HealthTech Decisions Lab “Operationally, think of logistics.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, datawarehouse, and data lakes can become equally challenging.
When it comes to data analysis, you are usually more likely to see me share guidance on advanced segmentation or custom reports or advanced social metrics or controlled experiments or economic value or competitive intelligence or web analytics maturity or one of an infinite number of difficult, if hugely rewarding, things.
To speed up the self-service analytics and foster innovation based on data, a solution was needed to provide ways to allow any team to create data products on their own in a decentralized manner. To create and manage the data products, smava uses Amazon Redshift , a cloud datawarehouse.
The aim was to bolster their analytical capabilities and improve data accessibility while ensuring a quick time to market and high data quality, all with low total cost of ownership (TCO) and no need for additional tools or licenses. Third-party APIs – These provide analytics and survey data related to ecommerce websites.
Datawarehouses play a vital role in healthcare decision-making and serve as a repository of historical data. A healthcare datawarehouse can be a single source of truth for clinical quality control systems. What is a dimensional data model? What is a dimensional data model? What is a data vault?
Different DAM providers use different approaches to defining the key metrics that influence the cost of an off-the-shelf solution. On the one hand, the use of agents allows you to actively monitor and respond to events. There are different opinions. DAM deployment best practices. Let’s get to the bottom of this.
As data volumes and use cases scale especially with AI and real-time analytics trust must be an architectural principle, not an afterthought. Comparison of modern data architectures : Architecture Definition Strengths Weaknesses Best used when Datawarehouse Centralized, structured and curated data repository.
Many organizations today are using AWS Glue to build ETL pipelines that bring data from disparate sources and store the data in repositories like a data lake, database, or datawarehouse for further consumption. EventBridge picks up the event from AWS Glue and triggers an AWS Lambda function.
The following figure shows some of the metrics derived from the study. You can subscribe to data products that help enrich customer profiles, for example demographics data, advertising data, and financial markets data. Data processing Raw data is often cluttered with duplicates and irregular formats.
Zero-ETL will perform an initial full load of your collection by doing a collection scan on the primary instance of your Amazon DocumentDB cluster, which may take several minutes to complete depending on the size of the data, and you may notice elevated resource consumption on your cluster.
In the second blog of the Universal Data Distribution blog series , we explored how Cloudera DataFlow for the Public Cloud (CDF-PC) can help you implement use cases like data lakehouse and datawarehouse ingest, cybersecurity, and log optimization, as well as IoT and streaming data collection.
Amazon Redshift is a fully managed, scalable cloud datawarehouse that accelerates your time to insights with fast, easy, and secure analytics at scale. Tens of thousands of customers rely on Amazon Redshift to analyze exabytes of data and run complex analytical queries, making it the widely used cloud datawarehouse.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content