This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Common use cases for using the dbt adapter with Athena The following are common use cases for using the dbt adapter with Athena: Building a datawarehouse – Many organizations are moving towards a datawarehouse architecture, combining the flexibility of data lakes with the performance and structure of datawarehouses.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze your data using standard SQL and your existing business intelligence (BI) tools. Data ingestion is the process of getting data to Amazon Redshift.
Oracle recently hosted its annual Database Analyst Summit, sharing the vision and strategy for its data platform. While much of the event was under non-disclosure as product plans and launch schedules are finalized, it still served as a useful recap of the broad portfolio of data platform capabilities that Oracle has to offer.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. or a later version) database.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that you can use to analyze your data at scale. Maintaining reusable database sessions to help optimize the use of database connections, preventing the API server from exhausting the available connections and improving overall system scalability.
Each data source is updated on its own schedule, for example, daily, weekly or monthly. The DataKitchen Platform ingests data into a data lake and runs Recipes to create a datawarehouse leveraged by users and self-service data analysts. The third set of domains are cached data sets (e.g., Conclusion.
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. Data store – The data store used a custom data model that had been highly optimized to meet low-latency query response requirements.
Complex queries, on the other hand, refer to large-scale data processing and in-depth analysis based on petabyte-level datawarehouses in massive data scenarios. AWS Glue crawler crawls data lake information from Amazon S3, generating a Data Catalog to support dbt on Amazon Athena data modeling.
Whether the reporting is being done by an end user, a data science team, or an AI algorithm, the future of your business depends on your ability to use data to drive better quality for your customers at a lower cost. So, when it comes to collecting, storing, and analyzing data, what is the right choice for your enterprise?
These types of queries are suited for a datawarehouse. The goal of a datawarehouse is to enable businesses to analyze their data fast; this is important because it means they are able to gain valuable insights in a timely manner. Amazon Redshift is fully managed, scalable, cloud datawarehouse.
While many organizations understand the business need for a data and analytics cloud platform , few can quickly modernize their legacy datawarehouse due to a lack of skills, resources, and data literacy. As the amount of data ingested into the cloud increases, so does the potential that a security threat will occur.
Amazon AppFlow is a fully managed integration service that you can use to securely transfer data from software as a service (SaaS) applications, such as Google BigQuery, Salesforce, SAP, HubSpot, and ServiceNow, to Amazon Web Services (AWS) services such as Amazon Simple Storage Service (Amazon S3) and Amazon Redshift, in just a few clicks.
Source systems Aruba’s source repository includes data from three different operating regions in AMER, EMEA, and APJ, along with one worldwide (WW) data pipeline from varied sources like SAP S/4 HANA, Salesforce, Enterprise DataWarehouse (EDW), Enterprise Analytics Platform (EAP) SharePoint, and more.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. AWS Database Migration Service (AWS DMS) is used to securely transfer the relevant data to a central Amazon Redshift cluster.
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
Today’s customers have a growing need for a faster end to end data ingestion to meet the expected speed of insights and overall business demand. This ‘need for speed’ drives a rethink on building a more modern datawarehouse solution, one that balances speed with platform cost management, performance, and reliability.
This premier event showcased groundbreaking advancements, keynotes from AWS leadership, hands-on technical sessions, and exciting product launches. Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights.
I recently had the honor of delivering the keynote at the “The Journey to the Top” Event at SAP UK headquarters, and you can see my slides and a video in my previous post How Data is Powering The Future of Business: Trends and Opportunities. People, collaboration, and ease of use.
Users today are asking ever more from their datawarehouse. As an example of this, in this post we look at Real Time Data Warehousing (RTDW), which is a category of use cases customers are building on Cloudera and which is becoming more and more common amongst our customers. Ingest 100s of TB of network eventdata per day .
It can control changes in the sources from which it extracts data and includes Data Lineage capabilities, which means confidence for the user. How is Data Virtualization performance optimized? How does Data Virtualization complement Data Warehousing and SOA Architectures? In forecasting future events.
Diagram 1: Overall architecture of the solution, using AWS Step Functions, Amazon Redshift and Amazon S3 The following AWS services were used to shape our new ETL architecture: Amazon Redshift A fully managed, petabyte-scale datawarehouse service in the cloud. The following Diagram 4 shows this workflow.
AppsFlyer develops a leading measurement solution focused on privacy, which enables marketers to gauge the effectiveness of their marketing activities and integrates them with the broader marketing world, managing a vast volume of 100 billion events every day.
A DSS leverages a combination of raw data, documents, personal knowledge, and/or business models to help users make decisions. The data sources used by a DSS could include relational data sources, cubes, datawarehouses, electronic health records (EHRs), revenue projections, sales projections, and more.
Managing large-scale datawarehouse systems has been known to be very administrative, costly, and lead to analytic silos. The good news is that Snowflake, the cloud data platform, lowers costs and administrative overhead. When did you begin a technology partnership with Snowflake and why?
To create and manage the data products, smava uses Amazon Redshift , a cloud datawarehouse. In this post, we show how smava optimized their data platform by using Amazon Redshift Serverless and Amazon Redshift data sharing to overcome right-sizing challenges for unpredictable workloads and further improve price-performance.
The extract, transform, and load (ETL) process has been a common pattern for moving data from an operational database to an analytics datawarehouse. ELT is where the extracted data is loaded as is into the target first and then transformed. ETL and ELT pipelines can be expensive to build and complex to manage.
Enterprises and organizations across the globe want to harness the power of data to make better decisions by putting data at the center of every decision-making process. However, throughout history, data services have held dominion over their customers’ data.
You will load the eventdata from the SFTP site, join it to the venue data stored on Amazon S3, apply transformations, and store the data in Amazon S3. The event and venue files are from the TICKIT dataset. For Node parents , select Rename Venue data and Rename Eventdata.
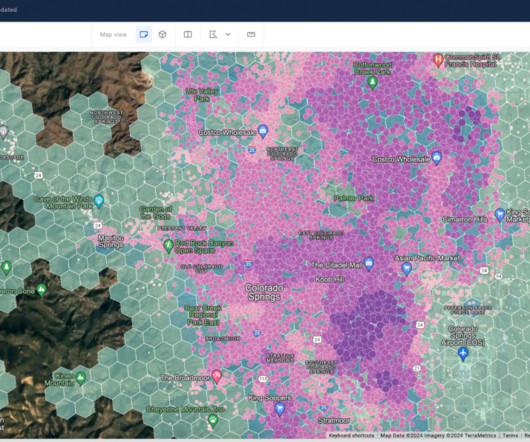
As technology continues to evolve, one specific facet of this journey is reaching unprecedented proportions: geospatial data. Because of this, many organizations are utilizing them as a support geography, aggregating their data to these grids to optimize both their storage and analysis.
Within the ANZ enterprise data mesh strategy, aligning data mesh nodes with the ANZ Group’s divisional structure provides optimal alignment between data mesh principles and organizational structure, as shown in the following diagram. Nodes and domains serve business needs and are not technology mandated.
Amazon Redshift is a popular cloud datawarehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
With auto-copy, automation enhances the COPY command by adding jobs for automatic ingestion of data. Federated queries allow querying data across Amazon RDS for MySQL and PostgreSQL data sources without the need for extract, transform, and load (ETL) pipelines.
There are two broad approaches to analyzing operational data for these use cases: Analyze the data in-place in the operational database (e.g. With Aurora zero-ETL integration with Amazon Redshift, the integration replicates data from the source database into the target datawarehouse. or higher version) database.
During that same time, AWS has been focused on helping customers manage their ever-growing volumes of data with tools like Amazon Redshift , the first fully managed, petabyte-scale cloud datawarehouse. One group performed extract, transform, and load (ETL) operations to take raw data and make it available for analysis.
Trade quality and optimization – In order to monitor and optimize trade quality, you need to continually evaluate market characteristics such as volume, direction, market depth, fill rate, and other benchmarks related to the completion of trades. This will be your OLTP data store for transactional data. version cluster.
It covers how to use a conceptual, logical architecture for some of the most popular gaming industry use cases like event analysis, in-game purchase recommendations, measuring player satisfaction, telemetry data analysis, and more. They should also provide optimal performance with low or no tuning.
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your datawarehouse. These upstream data sources constitute the data producer components.
When data is used to improve customer experiences and drive innovation, it can lead to business growth,” – Swami Sivasubramanian , VP of Database, Analytics, and Machine Learning at AWS in With a zero-ETL approach, AWS is helping builders realize near-real-time analytics. Choose a suitable instance size (the default is db.r5.2xlarge ).
More and more of FanDuel’s community of analysts and business users looked for comprehensive data solutions that centralized the data across the various arms of their business. Their individual, product-specific, and often on-premises datawarehouses soon became obsolete.
It aims to provide a framework to create low-latency streaming applications on the AWS Cloud using Amazon Kinesis Data Streams and AWS purpose-built data analytics services. In this post, we will review the common architectural patterns of two use cases: Time Series Data Analysis and Event Driven Microservices.
While cloud-native, point-solution datawarehouse services may serve your immediate business needs, there are dangers to the corporation as a whole when you do your own IT this way. Cloudera DataWarehouse (CDW) is here to save the day! CDW is an integrated datawarehouse service within Cloudera Data Platform (CDP).
If you can’t make sense of your business data, you’re effectively flying blind. Insights hidden in your data are essential for optimizing business operations, finetuning your customer experience, and developing new products — or new lines of business, like predictive maintenance. Azure Data Factory.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud. With Amazon Redshift, you can analyze all your data to derive holistic insights about your business and your customers. This helps in seamless migrations from traditional datawarehouses like Teradata and SQL Server.
Cloudera users can securely connect Rill to a source of event stream data, such as Cloudera DataFlow , model data into Rill’s cloud-based Druid service, and share live operational dashboards within minutes via Rill’s interactive metrics dashboard or any connected BI solution. Cloudera DataWarehouse). Apache Hive.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content