This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. or a later version) database.
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. Solution overview Amazon Redshift is an industry-leading cloud datawarehouse.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that you can use to analyze your data at scale. Whether you’re a data engineer, an analyst generating reports, or working on any other stateful data, understanding how to use Data API session reuse is worth exploring.
Each data source is updated on its own schedule, for example, daily, weekly or monthly. The DataKitchen Platform ingests data into a data lake and runs Recipes to create a datawarehouse leveraged by users and self-service data analysts. The third set of domains are cached data sets (e.g.,
Interestingly, you can address many of them very effectively with a datawarehouse. There are some very important reasons why you might want to bring some of your historical data into your new system, though. For example, it would be useful to retain the capability of reporting historical sales trends.
The world’s an eventful place, isn’t it? When we say ‘eventful’, we mean, there are some many things happening around the world, every day, every minute, and they are all happening as glamorous, lavish and big events – be it a phone launch, a mega concert, fairs and so on. Who’s coming?
Amazon AppFlow is a fully managed integration service that you can use to securely transfer data from software as a service (SaaS) applications, such as Google BigQuery, Salesforce, SAP, HubSpot, and ServiceNow, to Amazon Web Services (AWS) services such as Amazon Simple Storage Service (Amazon S3) and Amazon Redshift, in just a few clicks.
These types of queries are suited for a datawarehouse. The goal of a datawarehouse is to enable businesses to analyze their data fast; this is important because it means they are able to gain valuable insights in a timely manner. Amazon Redshift is fully managed, scalable, cloud datawarehouse.
User interfaces for ERP reporting tools are most often built with IT staff in mind, not the end user. For users of Oracle E-Business Suite (EBS), data access is about to get a bit more difficult now that the company has phased out the Oracle Discoverer product. Real-Time Reporting Solutions for Oracle EBS. View Solutions Now.
Enterprise datawarehouse platform owners face a number of common challenges. In this article, we look at seven challenges, explore the impacts to platform and business owners and highlight how a modern datawarehouse can address them. ETL jobs and staging of data often often require large amounts of resources.
Today’s customers have a growing need for a faster end to end data ingestion to meet the expected speed of insights and overall business demand. This ‘need for speed’ drives a rethink on building a more modern datawarehouse solution, one that balances speed with platform cost management, performance, and reliability.
ActionIQ is a leading composable customer data (CDP) platform designed for enterprise brands to grow faster and deliver meaningful experiences for their customers. This post will demonstrate how ActionIQ built a connector for Amazon Redshift to tap directly into your datawarehouse and deliver a secure, zero-copy CDP.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing ETL (extract, transform, and load), business intelligence (BI), and reporting tools.
As I explained in our recent Buyers Guide for Data Platforms , the popularization of generative artificial intelligence (GenAI) has had a significant impact on the requirements for data platforms in the last 18 months. Snowflake is not alone in adding support for AI workloads to its data platform.
Objective Gupshup wanted to build a messaging analytics platform that provided: Build a platform to get detailed insights, data, and reports about WhatsApp/SMS campaigns and track the success of every text message sent by the end customers. This compiled data is then imported into Aurora PostgreSQL Serverless for operational reporting.
Many organizations today are using AWS Glue to build ETL pipelines that bring data from disparate sources and store the data in repositories like a data lake, database, or datawarehouse for further consumption. EventBridge picks up the event from AWS Glue and triggers an AWS Lambda function.
In the following section, two use cases demonstrate how the data mesh is established with Amazon DataZone to better facilitate machine learning for an IoT-based digital twin and BI dashboards and reporting using Tableau. In the past, one-to-one connections were established between Tableau and respective applications.
Users today are asking ever more from their datawarehouse. As an example of this, in this post we look at Real Time Data Warehousing (RTDW), which is a category of use cases customers are building on Cloudera and which is becoming more and more common amongst our customers. Ingest 100s of TB of network eventdata per day .
The following are some of the key business use cases that highlight this need: Trade reporting – Since the global financial crisis of 2007–2008, regulators have increased their demands and scrutiny on regulatory reporting. This will be your OLTP data store for transactional data. version cluster. version cluster.
This premier event showcased groundbreaking advancements, keynotes from AWS leadership, hands-on technical sessions, and exciting product launches. Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights.
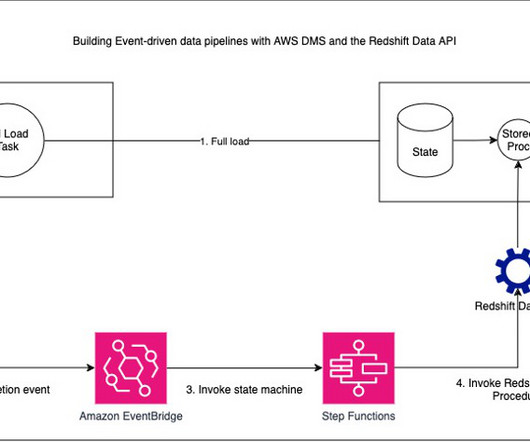
Diagram 1: Overall architecture of the solution, using AWS Step Functions, Amazon Redshift and Amazon S3 The following AWS services were used to shape our new ETL architecture: Amazon Redshift A fully managed, petabyte-scale datawarehouse service in the cloud. The following Diagram 4 shows this workflow.
A DSS leverages a combination of raw data, documents, personal knowledge, and/or business models to help users make decisions. The data sources used by a DSS could include relational data sources, cubes, datawarehouses, electronic health records (EHRs), revenue projections, sales projections, and more.
It covers how to use a conceptual, logical architecture for some of the most popular gaming industry use cases like event analysis, in-game purchase recommendations, measuring player satisfaction, telemetry data analysis, and more. Data lakes are more focused around storing and maintaining all the data in an organization in one place.
Federated queries are useful for use cases where organizations want to combine data from their operational systems with data stored in Amazon Redshift. Federated queries allow querying data across Amazon RDS for MySQL and PostgreSQL data sources without the need for extract, transform, and load (ETL) pipelines.
During that same time, AWS has been focused on helping customers manage their ever-growing volumes of data with tools like Amazon Redshift , the first fully managed, petabyte-scale cloud datawarehouse. From 2019 to now, Wang reports the amount of data the company holds has grown by a factor of 20.
Data from that surfeit of applications was distributed in multiple repositories, mostly traditional databases. Fazal instructed his IT team to collect every bit of data and methodically determine its use later, rather than lose “precious” data in the rush to build a massive datawarehouse. “We
The first blog introduced a mock connected vehicle manufacturing company, The Electric Car Company (ECC), to illustrate the manufacturing data path through the data lifecycle. Having completed the Data Collection step in the previous blog, ECC’s next step in the data lifecycle is Data Enrichment.
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your datawarehouse. These upstream data sources constitute the data producer components.
This connector provides comprehensive access to SFTP storage, facilitating cloud ETL processes for operational reporting, backup and disaster recovery, data governance, and more. Solution overview In this example, you use AWS Glue Studio to connect to an SFTP server, then enrich that data and upload it to Amazon S3.
Analytics is the means for discovering those insights, and doing it well requires the right tools for ingesting and preparing data, enriching and tagging it, building and sharing reports, and managing and protecting your data and insights. Azure Data Factory. Azure Data Lake Analytics.
Social BI indicates the process of gathering, analyzing, publishing, and sharing data, reports, and information. This is done using interactive Business Intelligence and Analytics dashboards along with intuitive tools to improve data clarity. They can also optimize their time if they don’t have to reinvent a report.
Data virtualization is ideal in any situation where the is necessary: Information coming from diverse data sources. Multi-channel publishing of data services. How does Data Virtualization complement Data Warehousing and SOA Architectures? In forecasting future events. Real-time information.
Most of what is written though has to do with the enabling technology platforms (cloud or edge or point solutions like datawarehouses) or use cases that are driving these benefits (predictive analytics applied to preventive maintenance, financial institution’s fraud detection, or predictive health monitoring as examples) not the underlying data.
You can drill into data, create a variety of visualizations, and (literally) ask questions about it using AI. Power BI’s rich reports or dashboards can be embedded into reporting portals you already use. Smart Narratives pull out key takeaways and trends in your data and wrap them with autogenerated text to build data stories.
The aim was to bolster their analytical capabilities and improve data accessibility while ensuring a quick time to market and high data quality, all with low total cost of ownership (TCO) and no need for additional tools or licenses. Flat files – Other systems supply data in the form of flat files of different formats.
The extract, transform, and load (ETL) process has been a common pattern for moving data from an operational database to an analytics datawarehouse. ELT is where the extracted data is loaded as is into the target first and then transformed. ETL and ELT pipelines can be expensive to build and complex to manage.
The application supports custom workflows to allow demand and supply planning teams to collaborate, plan, source, and fulfill customer orders, then track fulfillment metrics via persona-based operational and management reports and dashboards. To achieve this, Aruba used Amazon S3 Event Notifications.
Amazon Redshift is a fast, fully managed, petabyte-scale datawarehouse that provides the flexibility to use provisioned or serverless compute for your analytical workloads. You can get faster insights without spending valuable time managing your datawarehouse. Analyze the assessment report and address the action items.
Datawarehouses play a vital role in healthcare decision-making and serve as a repository of historical data. A healthcare datawarehouse can be a single source of truth for clinical quality control systems. This is one of the biggest hurdles with the data vault approach. What is a dimensional data model?
There are two broad approaches to analyzing operational data for these use cases: Analyze the data in-place in the operational database (e.g. With Aurora zero-ETL integration with Amazon Redshift, the integration replicates data from the source database into the target datawarehouse. or higher version) database.
Bridging the Gap: How ‘Data in Place’ and ‘Data in Use’ Define Complete Data Observability In a world where 97% of data engineers report burnout and crisis mode seems to be the default setting for data teams, a Zen-like calm feels like an unattainable dream.
Cloudera users can securely connect Rill to a source of event stream data, such as Cloudera DataFlow , model data into Rill’s cloud-based Druid service, and share live operational dashboards within minutes via Rill’s interactive metrics dashboard or any connected BI solution. Cloudera DataWarehouse). Apache Hive.
Before we dive in, we recommend reviewing Architectural patterns for real-time analytics using Amazon Kinesis Data Streams, part 1 for the basic functionalities of Kinesis Data Streams. Part 1 also contains architectural examples for building real-time applications for time series data and event-sourcing microservices.
In this article, we will detail everything which is at stake when we talk about DQM: why it is essential, how to measure data quality, the pillars of good quality management, and some data quality control techniques. But first, let’s define what data quality actually is. 4 – DataReporting.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content