This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Complex queries, on the other hand, refer to large-scale data processing and in-depth analysis based on petabyte-level datawarehouses in massive data scenarios. AWS Glue crawler crawls data lake information from Amazon S3, generating a Data Catalog to support dbt on Amazon Athena data modeling.
This post was co-written with Dipankar Mazumdar, Staff Data Engineering Advocate with AWS Partner OneHouse. Data architecture has evolved significantly to handle growing data volumes and diverse workloads. For a table that will be converted, it invokes the converter Lambda function through an event.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud. You can start with just a few hundred gigabytes of data and scale to a petabyte or more. This enables you to use your data to acquire new insights for your business and customers. For additional details, refer to Automated snapshots.
These types of queries are suited for a datawarehouse. The goal of a datawarehouse is to enable businesses to analyze their data fast; this is important because it means they are able to gain valuable insights in a timely manner. Amazon Redshift is fully managed, scalable, cloud datawarehouse.
About Redshift and some relevant features for the use case Amazon Redshift is a fully managed, petabyte-scale, massively parallel datawarehouse that offers simple operations and high performance. It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools.
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
Enterprises and organizations across the globe want to harness the power of data to make better decisions by putting data at the center of every decision-making process. However, throughout history, data services have held dominion over their customers’ data. SparkActions.get().expireSnapshots(iceTable).expireOlderThan(TimeUnit.DAYS.toMillis(7)).execute()
Amazon Redshift is a popular cloud datawarehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
A CDC-based approach captures the data changes and makes them available in datawarehouses for further analytics in real-time. usually a datawarehouse) needs to reflect those changes in near real-time. This post showcases how to use streaming ingestion to bring data to Amazon Redshift.
and zero-ETL support) as the source, and a Redshift datawarehouse as the target. The integration replicates data from the source database into the target datawarehouse. Additionally, you can choose the capacity, to limit the compute resources of the datawarehouse. For this post, set this to 8 RPUs.
It aims to provide a framework to create low-latency streaming applications on the AWS Cloud using Amazon Kinesis Data Streams and AWS purpose-built data analytics services. In this post, we will review the common architectural patterns of two use cases: Time Series Data Analysis and Event Driven Microservices.
AWS-powered data lakes, supported by the unmatched availability of Amazon Simple Storage Service (Amazon S3), can handle the scale, agility, and flexibility required to combine different data and analytics approaches. It will never remove files that are still required by a non-expired snapshot.
To achieve this, first requires getting the data into a form that delivers insights. Salesforce data is extracted, transformed and loaded into a datawarehouse using an ETL tool connected to the datawarehouse. Then, use a data model to model the data into a single unified source of truth.
The AWS Glue crawler generates and updates Iceberg table metadata and stores it in AWS Glue Data Catalog for existing Iceberg tables on an S3 data lake. Snowflake integrates with AWS Glue Data Catalog to retrieve the snapshot location. Snowflake can query across Iceberg and Snowflake table formats.
The extract, transform, and load (ETL) process has been a common pattern for moving data from an operational database to an analytics datawarehouse. ELT is where the extracted data is loaded as is into the target first and then transformed. ETL and ELT pipelines can be expensive to build and complex to manage.
There are two broad approaches to analyzing operational data for these use cases: Analyze the data in-place in the operational database (e.g. With Aurora zero-ETL integration with Amazon Redshift, the integration replicates data from the source database into the target datawarehouse. or higher version) database.
It supports modern analytical data lake operations such as create table as select (CTAS), upsert and merge, and time travel queries. Athena also supports the ability to create views and perform VACUUM (snapshot expiration) on Apache Iceberg tables to optimize storage and performance.
For example, in a chatbot, dataevents could pertain to an inventory of flights and hotels or price changes that are constantly ingested to a streaming storage engine. Furthermore, dataevents are filtered, enriched, and transformed to a consumable format using a stream processor.
While these instructions are carried out for Cloudera Data Platform (CDP), Cloudera Data Engineering, and Cloudera DataWarehouse, one can extrapolate them easily to other services and other use cases as well. In all the use cases we are trying to migrate a table named “events.”
It automatically provisions and intelligently scales datawarehouse compute capacity to deliver fast performance, and you pay only for what you use. Just load your data and start querying right away in the Amazon Redshift Query Editor or in your favorite business intelligence (BI) tool. Ashish Agrawal is a Sr.
Data migration must be performed separately using methods such as S3 replication , S3 sync, aws-s3-copy-sync-using-batch or S3 Batch replication. This utility has two modes for replicating Lake Formation and Data Catalog metadata: on-demand and real-time. All relevant events are then stored in a DynamoDB table.
Ahead of the Chief Data Analytics Officers & Influencers, Insurance event we caught up with Dominic Sartorio, Senior Vice President for Products & Development, Protegrity to discuss how the industry is evolving. It definitely depends on the type of data, no one method is always better than the other.
Amazon Redshift is a fast, fully managed, petabyte-scale datawarehouse that provides the flexibility to use provisioned or serverless compute for your analytical workloads. You can get faster insights without spending valuable time managing your datawarehouse. Fault tolerance is built in.
There was always a delay between the events being recorded in financial systems (for example, the purchase of a product or service) and the ability to put that information in context and draw useful conclusions from it (for example, a weekly sales report). Such BI methodologies are built on a snapshot of what happened in the past.
Data Science works best with a high degree of data granularity when the data offers the closest possible representation of what happened during actual events – as in financial transactions, medical consultations or marketing campaign results. Integration Features.
The Analytics specialty practice of AWS Professional Services (AWS ProServe) helps customers across the globe with modern data architecture implementations on the AWS Cloud. For example, to create source-aligned datasets in the data lake for 3,000 operational tables, the company didn’t want to deploy 3,000 separate data processing jobs.
Amazon Redshift is a fully managed and petabyte-scale cloud datawarehouse that is used by tens of thousands of customers to process exabytes of data every day to power their analytics workload. You can structure your data, measure business processes, and get valuable insights quickly can be done by using a dimensional model.
To achieve this, they combine their CRM data with a wealth of information already available in their datawarehouse, enterprise systems, or other software as a service (SaaS) applications. One widely used approach is getting the CRM data into your datawarehouse and keeping it up to date through frequent data synchronization.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a data lake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale. Clustering data for better data colocation using z-ordering.
A range of Iceberg table analysis such as listing table’s data file, selecting table snapshot, partition filtering, and predicate filtering can be delegated through Iceberg Java API instead, obviating the need for each query engine to implement it themself. The data files and metadata files in Iceberg format are immutable.
In this blog, we walk through the Impala workloads analysis in iEDH, Cloudera’s own Enterprise DataWarehouse (EDW) implementation on CDH clusters. We might find the root cause by realizing that a problem recurs at a particular time, or coincides with another event. . Data Engineering jobs (optional). Primary Workload .
In a datawarehouse, a dimension is a structure that categorizes facts and measures in order to enable users to answer business questions. This post is designed to be implemented for a real customer use case, where you get full snapshotdata on a daily basis.
Because DE is fully integrated with the Cloudera Shared Data Experience (SDX), every stakeholder across your business gains end-to-end operational visibility, with comprehensive security and governance throughout. The admin overview page provides a snapshot of all the workloads across multi-cloud environments.
The following are some highlighted steps: Run a snapshot query. %%sql You also can use transactional data lake features such as running snapshot queries, incremental queries, time travel, and DML query. He is deeply passionate about applying ML/DL and big data techniques to solve real-world problems.
Snapshot testing augments debugging capabilities by recording past table states, facilitating the identification of unforeseen spikes, declines, or abnormalities before their effect on production systems. Workaround: Use Git branches, tagging, and commit messages to trackchanges.
S3 bucket as landing zone We used an S3 bucket as the immediate landing zone of the extracted data, which is further processed and optimized. Lambda as AWS Glue ETL Trigger We enabled S3 event notifications on the S3 bucket to trigger Lambda, which further partitions our data. Clients access this data store with an API’s.
Additionally, the scale is significant because the multi-tenant data sources provide a continuous stream of testing activity, and our users require quick data refreshes as well as historical context for up to a decade due to compliance and regulatory demands. Finally, data integrity is of paramount importance.
You will also want to apply incremental updates with change data capture (CDC) from the source system to the destination. To make data-driven decisions in a timely manner, you need to account for missed records and backpressure, and maintain event ordering and integrity, especially if the reference data also changes rapidly.
Amazon Redshift is a fully managed, petabyte scale cloud datawarehouse that enables you to analyze large datasets using standard SQL. Datawarehouse workloads are increasingly being used with mission-critical analytics applications that require the highest levels of resilience and availability.
On the Code tab, choose Test , then Configure test event. Configure a test event with the default hello-world template event JSON. Provide an event name without any changes to the template and save the test event. Provide an event name without any changes to the template and save the test event.
Organizations across all industries have complex data processing requirements for their analytical use cases across different analytics systems, such as data lakes on AWS , datawarehouses ( Amazon Redshift ), search ( Amazon OpenSearch Service ), NoSQL ( Amazon DynamoDB ), machine learning ( Amazon SageMaker ), and more.
Today, BI represents a $23 billion market and umbrella term that describes a system for data-driven decision-making. BI leverages and synthesizes data from analytics, data mining, and visualization tools to deliver quick snapshots of business health to key stakeholders, and empower those people to make better choices.
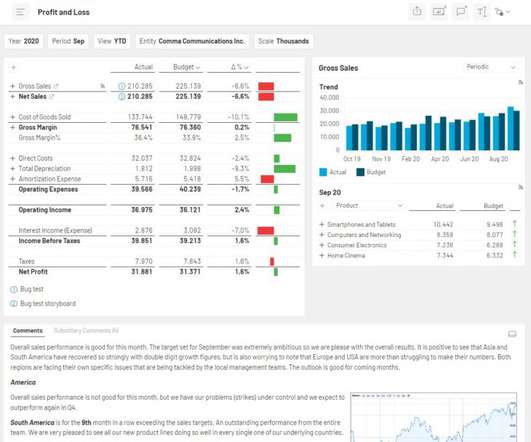
That might be a sales performance dashboard for your Chief Revenue Officer, a snapshot of “days sales outstanding” (DSO) for the A/R collections team, or an item sales trend analysis for product management. With the CXO DataWarehouse Adapter, you can access ERP data, planning and budgeting numbers, or external information.
The answer depends on your specific business needs and the nature of the data you are working with. Both methods have advantages and disadvantages: Replication involves periodically copying data from a source system to a datawarehouse or reporting database. Empower your team to add new data sources on the fly.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content