This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
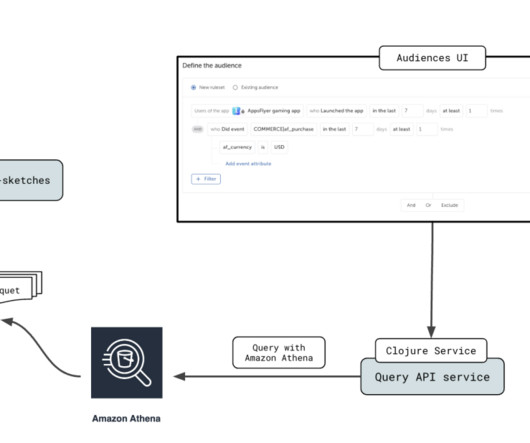
Enterprise data is brought into data lakes and datawarehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. Table metadata is fetched from AWS Glue. The generated Athena SQL query is run.
Amazon Redshift is a fully managed, AI-powered cloud datawarehouse that delivers the best price-performance for your analytics workloads at any scale. It enables you to get insights faster without extensive knowledge of your organization’s complex database schema and metadata. Your data is not shared across accounts.
This post was co-written with Dipankar Mazumdar, Staff Data Engineering Advocate with AWS Partner OneHouse. Data architecture has evolved significantly to handle growing data volumes and diverse workloads. The synchronization process in XTable works by translating table metadata using the existing APIs of these table formats.
Performance is one of the key, if not the most important deciding criterion, in choosing a Cloud DataWarehouse service. In today’s fast changing world, enterprises have to make data driven decisions quickly and for that they rely heavily on their datawarehouse service. . Cloudera DataWarehouse vs HDInsight.
Metadata management is key to wringing all the value possible from data assets. However, most organizations don’t use all the data at their disposal to reach deeper conclusions about how to drive revenue, achieve regulatory compliance or accomplish other strategic objectives. What Is Metadata? Harvest data.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud datawarehouses.
As part of the Talent Intelligence Platform Eightfold also exposes a data hub where each customer can access their Amazon Redshift-based datawarehouse and perform ad hoc queries as well as schedule queries for reporting and data export. Many customers have implemented Amazon Redshift to support multi-tenant applications.
Cloud datawarehouses allow users to run analytic workloads with greater agility, better isolation and scale, and lower administrative overhead than ever before. The results demonstrate superior price performance of Cloudera DataWarehouse on the full set of 99 queries from the TPC-DS benchmark. Introduction.
One of the BI architecture components is data warehousing. Organizing, storing, cleaning, and extraction of the data must be carried by a central repository system, namely datawarehouse, that is considered as the fundamental component of business intelligence. What Is Data Warehousing And Business Intelligence?
The past decades of enterprise data platform architectures can be summarized in 69 words. First-generation – expensive, proprietary enterprise datawarehouse and business intelligence platforms maintained by a specialized team drowning in technical debt. Note, this is based on a post by Zhamak Dehghani of Thoughtworks. .
AppsFlyer empowers digital marketers to precisely identify and allocate credit to the various consumer interactions that lead up to an app installation, utilizing in-depth analytics. million) that it loaded from the AWS Glue Data Catalog (for more information about using Athena with AWS Glue, see Integration with AWS Glue ).
Some of the most powerful results come from combining complementary superpowers, and the “dynamic duo” of Apache Hive LLAP and Apache Impala, both included in Cloudera DataWarehouse , is further evidence of this. Both Impala and Hive can operate at an unprecedented and massive scale, with many petabytes of data. So, why choose?
In this blog, we will share with you in detail how Cloudera integrates core compute engines including Apache Hive and Apache Impala in Cloudera DataWarehouse with Iceberg. We will publish follow up blogs for other data services. Iceberg basics Iceberg is an open table format designed for large analytic workloads.
Amazon SageMaker Lakehouse provides an open data architecture that reduces data silos and unifies data across Amazon Simple Storage Service (Amazon S3) data lakes, Redshift datawarehouses, and third-party and federated data sources. With AWS Glue 5.0, AWS Glue 5.0 Finally, AWS Glue 5.0
Amazon Redshift is a fast, petabyte-scale, cloud datawarehouse that tens of thousands of customers rely on to power their analytics workloads. With its massively parallel processing (MPP) architecture and columnar data storage, Amazon Redshift delivers high price-performance for complex analytical queries against large datasets.
Organisations are looking at ways of simplifying data; for example, through simple rebranding efforts to disguise the complexity. However, SAP Datasphere goes much deeper deeper than a simple rebranding; it is the next generation of SAP DataWarehouse Cloud.
First, many LLM use cases rely on enterprise knowledge that needs to be drawn from unstructured data such as documents, transcripts, and images, in addition to structured data from datawarehouses. Data enrichment In addition, additional metadata may need to be extracted from the objects.
To better understand and align data governance and enterprise architecture, let’s look at data at rest and data in motion and why they both have to be documented. Documenting data at rest involves looking at where data is stored, such as in databases, data lakes , datawarehouses and flat files.
ActionIQ is a leading composable customer data (CDP) platform designed for enterprise brands to grow faster and deliver meaningful experiences for their customers. This post will demonstrate how ActionIQ built a connector for Amazon Redshift to tap directly into your datawarehouse and deliver a secure, zero-copy CDP.
A data catalog benefits organizations in a myriad of ways. With the right data catalog tool, organizations can automate enterprise metadata management – including data cataloging, data mapping, data quality and code generation for faster time to value and greater accuracy for data movement and/or deployment projects.
These lakes power mission critical large scale data analytics, business intelligence (BI), and machine learning use cases, including enterprise datawarehouses. In recent years, the term “data lakehouse” was coined to describe this architectural pattern of tabular analytics over data in the data lake.
Quick setup enables two default blueprints and creates the default environment profiles for the data lake and datawarehouse default blueprints. You will then publish the data assets from these data sources. Add an AWS Glue data source to publish the new AWS Glue table. Review and choose Create.
These lakes power mission critical large scale data analytics, business intelligence (BI), and machine learning use cases, including enterprise datawarehouses. In recent years, the term “data lakehouse” was coined to describe this architectural pattern of tabular analytics over data in the data lake.
As AI becomes more pervasive, businesses need to feel confident that their models can be relied upon not to “hallucinate” facts or use inappropriate language when interacting with customers. With watsonx.data , businesses can quickly connect to data, get trusted insights and reduce datawarehouse costs.
To fill in the gaps in existing data, HR&A creates digital equity surveys to build a more complete picture before developing digital equity plans. HR&A has used Amazon Redshift Serverless and CARTO to process survey findings more efficiently and create custom interactive dashboards to facilitate understanding of the results.
“The number-one issue for our BI team is convincing people that business intelligence will help to make true data-driven decisions,” says Diana Stout, senior business analyst at Schellman, a global cybersecurity assessor based in Tampa, Fl. Or you have a [BI tool] like Domo, which Schellman uses, that can function as a datawarehouse.
With quality data at their disposal, organizations can form datawarehouses for the purposes of examining trends and establishing future-facing strategies. Industry-wide, the positive ROI on quality data is well understood. 2 – Data profiling. Data profiling is an essential process in the DQM lifecycle.
Amazon Redshift is a popular cloud datawarehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
dbt is an open source, SQL-first templating engine that allows you to write repeatable and extensible data transforms in Python and SQL. dbt is predominantly used by datawarehouses (such as Amazon Redshift ) customers who are looking to keep their data transform logic separate from storage and engine.
In fact, according in an IDC DataSphere study, IDC estimated that 10,628 exabytes (EB) of data was determined to be useful if analyzed, while only 5,063 exabytes (EB) of data (47.6%) was analyzed in 2022. New insights and relationships are found in this combination. All of this supports the use of AI.
Data lakes are more focused around storing and maintaining all the data in an organization in one place. And unlike datawarehouses, which are primarily analytical stores, a data hub is a combination of all types of repositories—analytical, transactional, operational, reference, and data I/O services, along with governance processes.
It seamlessly consolidates data from various data sources within AWS, including AWS Cost Explorer (and forecasting with Cost Explorer ), AWS Trusted Advisor , and AWS Compute Optimizer. Data providers and consumers are the two fundamental users of a CDH dataset.
Amazon Redshift is a popular cloud datawarehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
In the past, First Service Credit Union’s Chief data officer Ty Robbins struggled to integrate data from the legacy, non-relational, and often proprietary tabular databases on which many credit unions run. Each of the acquired companies had multiple data sets with different primary keys, says Hepworth. “We
This post is co-authored by Vijay Gopalakrishnan, Director of Product, Salesforce Data Cloud. In today’s data-driven business landscape, organizations collect a wealth of data across various touch points and unify it in a central datawarehouse or a data lake to deliver business insights.
Many customers run big data workloads such as extract, transform, and load (ETL) on Apache Hive to create a datawarehouse on Hadoop. We split the solution into two primary components: generating Spark job metadata and running the SQL on Amazon EMR. The script generates a metadata JSON file for each step.
Data in Place refers to the organized structuring and storage of data within a specific storage medium, be it a database, bucket store, files, or other storage platforms. In the contemporary data landscape, data teams commonly utilize datawarehouses or lakes to arrange their data into L1, L2, and L3 layers.
They enable transactions on top of data lakes and can simplify data storage, management, ingestion, and processing. These transactional data lakes combine features from both the data lake and the datawarehouse. The Data Catalog provides a central location to govern and keep track of the schema and metadata.
In today’s data-driven world , organizations are constantly seeking efficient ways to process and analyze vast amounts of information across data lakes and warehouses. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
Amazon Redshift , the most widely used cloud datawarehouse, has evolved significantly to meet the performance requirements of the most demanding workloads. This post covers one such new feature—the multidimensional data layout sort key. Milind Oke is a DataWarehouse Specialist Solutions Architect based out of New York.
In other words, using metadata about data science work to generate code. In this case, code gets generated for data preparation, where so much of the “time and labor” in data science work is concentrated. Interactive Query Synthesis from Input-Output Examples ” – Chenglong Wang, Alvin Cheung, Rastislav Bodik (2017-05-14).
To speed up the self-service analytics and foster innovation based on data, a solution was needed to provide ways to allow any team to create data products on their own in a decentralized manner. To create and manage the data products, smava uses Amazon Redshift , a cloud datawarehouse.
QuickSight makes it straightforward for business users to visualize data in interactive dashboards and reports. Data Firehose uses an AWS Lambda function to transform data and ingest the transformed records into an Amazon Simple Storage Service (Amazon S3) bucket.
After all, how do you adjust this month’s operations based on last month’s data if it takes two weeks to finally receive the information you need? This is exactly how Octopai customer, Farm Credit Services of America (FCSA) , felt when their BI team needed to modernize their datawarehouse.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content