This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Beyond breaking down silos, modern data architectures need to provide interfaces that make it easy for users to consume data using tools fit for their jobs. Data must be able to freely move to and from datawarehouses, data lakes, and data marts, and interfaces must make it easy for users to consume that data.
Most of what is written though has to do with the enabling technology platforms (cloud or edge or point solutions like datawarehouses) or use cases that are driving these benefits (predictive analytics applied to preventive maintenance, financial institution’s fraud detection, or predictive health monitoring as examples) not the underlying data.
times better price-performance than other cloud datawarehouses on real-world workloads using advanced techniques like concurrency scaling to support hundreds of concurrent users, enhanced string encoding for faster query performance, and Amazon Redshift Serverless performance enhancements. Amazon Redshift delivers up to 4.9
With the massive explosion of data across the enterprise — both structured and unstructured from existing sources and new innovations such as streaming and IoT — businesses have needed to find creative ways of managing their increasingly complex data lifecycle to speed time to insight.
Datawarehouses play a vital role in healthcare decision-making and serve as a repository of historical data. A healthcare datawarehouse can be a single source of truth for clinical quality control systems. What is a dimensional data model? What is a dimensional data model?
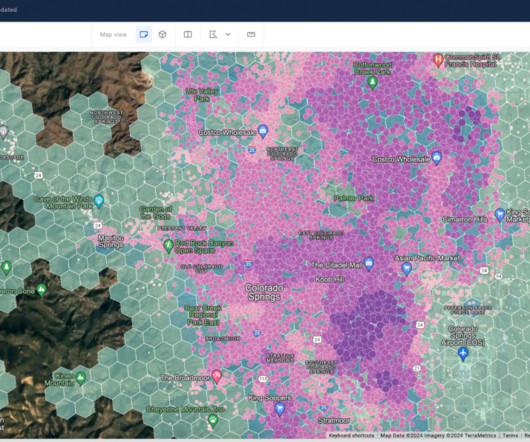
However, visualizing and analyzing large-scale geospatial datapresents a formidable challenge due to the sheer volume and intricacy of information. With Amazon Redshift, you can get real-time insights and predictive analytics on all of your data across your operational databases, data lake, datawarehouse, and third-party datasets.
Large-scale datawarehouse migration to the cloud is a complex and challenging endeavor that many organizations undertake to modernize their data infrastructure, enhance data management capabilities, and unlock new business opportunities. This makes sure the new data platform can meet current and future business goals.
Configure streaming data In the streaming domain, we’re often tasked with exploring, transforming, and enriching data coming from Internet of Things (IoT) sensors. To generate the real-time sensor data, we employ the AWS IoT Device Simulator. Navigate to the AWS IoT Core console. Choose Next.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it straightforward and cost-effective to analyze your data. This empowers data analysts and developers to incorporate ML into their datawarehouse workflows with streamlined processes driven by familiar SQL commands.
Forrester’s 2022 Total Economic Impact Report for Data Management highlights the impact Db2 and the IBM data management portfolio is having for customers: Return on investment (ROI) of 241% and payback <6 months. Db2 database SaaS is a fully managed service for a high – performance, transactional workload.
In determining how we wanted to merge these data stacks and how we wanted to model our data, we also revisited our data strategy to consider what we as a data team were striving to achieve within the business. The right data model + artificial intelligence = augmented analytics. Dig into AI.
Toiling Away in the Data Mines. If data is the fuel driving opportunities for optimization, data mining is the engine—converting that raw fuel into forward motion for your business. Store and manage: Next, businesses store and manage the data in a multidimensional database system, such as OLAP or tabular cubes.
I returned today from a two week trip to Australia that included client meetings and roundtable presentations in five cities – Brisbane, Adelaide, Melbourne, Canberra and Sydney. However, most data privacy discussions veered towards the EU GDPR ([link] which is now less than 100 days away from enforcement (May 25, 2018).
Dynamically invoking compute resources based on parameters such as query concurrency (for Data Warehousing using cases), fluctuations in ingested IoT volumes (streaming use cases) and releasing them automatically as usage winds down. Experience configuration / use case deployment: At the data lifecycle experience level (e.g.,
To best understand how to do this, let’s dig into the challenges of big data and look at a wave of emerging issues. For starters, the rise of the Internet of Things (IoT) has created immense volumes of new data to be analyzed. displaying BI insights for human users).
He is a successful architect of healthcare datawarehouses, clinical and business intelligence tools, big data ecosystems, and a health information exchange. The Enterprise Data Cloud – A Healthcare Perspective. The analytics and data platform is powering different data needs, use cases, and growth.
However, in many organizations, data is typically spread across a number of different systems such as software as a service (SaaS) applications, operational databases, and datawarehouses. Such data silos make it difficult to get unified views of the data in an organization and act in real time to derive the most value.
For customers, this opens up massive new opportunities within the Cloudera stack to incorporate existing data footprints with streaming sources. We believe this new capability will unlock net new capabilities for use cases in IoT, Finance, Manufacturing and more. Unlocking new use cases and architectures.
Complicating matters is the increasing focus on data protection and the far-reaching implications of IoT (e.g. How do I get to the next level in the data-driven journey fast enough? How do I meet a growing demand for self-serve BI, while not exploding my datawarehouse budgets? Tough decisions. Complex scenarios.
You spoke on cataloging the data lake using Alation for distributed analytics innovation at Munich Re. What are some of the major insights you presented at the talk. Andreas Kohlmaier : A data catalog is one of the key things you have to get right when implementing a data lake because data lakes can quickly become very big.
Free Download of FineReport What is Business Intelligence Dashboard (BI Dashboard)? A business intelligence dashboard, also known as a BI dashboard, is a tool that presents important business metrics and data points in a visual and analytical format on a single screen.
The bank brought together 27 billion data points and uses AI to understand the next-best conversation 21 million times each weekday. The bank coordinates all interactions via its branch network and Australian-based contact centers and presents it back through digital channels, ATMs, email and direct mail.
It also revealed that only 37 percent of organisational data being stored in cloud datawarehouses, and 35 percent still in on-premises datawarehouses. However, more than 99 percent of respondents said they would migrate data to the cloud over the next two years. zettabytes of data.
The key components of a data pipeline are typically: Data Sources : The origin of the data, such as a relational database , datawarehouse, data lake , file, API, or other data store. This can include tasks such as data ingestion, cleansing, filtering, aggregation, or standardization.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content