This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Data from different sources are brought to a single location and then converted into a format that the datawarehouse can process and store. For example, a company stores data about its customers, products, employees, salaries, sales, and invoices. A boss may […].
Introduction The following is an in-depth article explaining what data warehousing is as well as its types, characteristics, benefits, and disadvantages. What is a datawarehouse? The post An Introduction to DataWarehouse appeared first on Analytics Vidhya. Why is […].
Introduction All data mining repositories have a similar purpose: to onboard data for reporting intents, analysis purposes, and delivering insights. By their definition, the types of data it stores and how it can be accessible to users differ.
Introduction The purpose of a datawarehouse is to combine multiple sources to generate different insights that help companies make better decisions and forecasting. It consists of historical and commutative data from single or multiple sources. Most data scientists, big data analysts, and business […].
Introduction Do you think you can derive insights from raw data? Wouldn’t the process be much easier if the raw data were more organized and clean? Here’s when Data […]. The post What are Schemas in DataWarehouse Modeling? appeared first on Analytics Vidhya.
Introduction Data is defined as information that has been organized in a meaningful way. Data collection is critical for businesses to make informed decisions, understand customers’ […]. The post Data Lake or DataWarehouse- Which is Better? appeared first on Analytics Vidhya.
Introduction on Snowflake Architecture This article helps to focus on an in-depth understanding of Snowflake architecture, how it stores and manages data, as well as its conceptual fragmentation concepts. The post Snowflake Architecture & Key Concepts for DataWarehouse appeared first on Analytics Vidhya.
This is where data warehousing is a critical component of any business, allowing companies to store and manage vast amounts of data. It provides the necessary foundation for businesses to […] The post Understanding the Basics of DataWarehouse and its Structure appeared first on Analytics Vidhya.
According to the study conducted by Wakefield Research in 2021, only 22% of the data leaders surveyed have fully realized ROI in the past two years, with most data leaders (56%) having no consistent way of measuring it.
Introduction to DataWarehouse In today’s data-driven age, a large amount of data gets generated daily from various sources such as emails, e-commerce websites, healthcare, supply chain and logistics, transaction processing systems, etc. It is difficult to store, maintain and keep track of […].
Introduction on DataWarehouses During one of the technical webinars, it was highlighted where the transactional database was rendered no-operational bringing day to day operations to a standstill. The post Understanding Key Concepts on DataWarehouses appeared first on Analytics Vidhya.
Introduction The STAR schema is an efficient database design used in data warehousing and business intelligence. It organizes data into a central fact table linked to surrounding dimension tables. A major advantage of the STAR […] The post How to Optimize DataWarehouse with STAR Schema?
Introduction Have you ever wondered how big IT giants store and process huge amounts of data? Different organizations make use of different databases like an oracle database storing transactional data, MySQL for storing product data, and many others for different tasks. storing the data […].
Organizations are dealing with exponentially increasing data that ranges broadly from customer-generated information, financial transactions, edge-generated data and even operational IT server logs. A combination of complex data lake and datawarehouse capabilities are required to leverage this data.
United claims to be among the earliest users of the Amazon SageMaker ML platform, and it has leveraged its own United Data Hub and AWS Bedrock-based Mars ML platform to create this first batch of production gen AI LLMs. People hear the specifics, and they understand it and their blood pressure goes down.
Why: Data Makes It Different. In contrast, a defining feature of ML-powered applications is that they are directly exposed to a large amount of messy, real-world data which is too complex to be understood and modeled by hand. However, the concept is quite abstract. Can’t we just fold it into existing DevOps best practices?
INTRODUCTION Hive is one of the most popular datawarehouse systems in the industry for data storage, and to store this data Hive uses tables. By default, it is /user/hive/warehouse directory. Tables in the hive are analogous to tables in a relational database management system. For instance, […].
Slingshot is a data management software product initially developed by Capital One Financial Corporation to accelerate and manage its internal adoption of Snowflake’s cloud-based analytic data platform. Along the way, it adopted Snowflake’s AI Data Cloud and became an investor in the company in 2017.
This article was published as a part of the Data Science Blogathon Introduction Google’s BigQuery is an enterprise-grade cloud-native datawarehouse. Since its inception, BigQuery has evolved into a more economical and fully managed datawarehouse that can run lightning-fast […].
This is where we dispel an old “big data” notion (heard a decade ago) that was expressed like this: “we need our data to run at the speed of business.” Instead, what we really need is for our business to run at the speed of data. This is where SAP Datasphere (the next generation of SAP DataWarehouse Cloud) comes in.
Data lakes and datawarehouses are two of the most important data storage and management technologies in a modern data architecture. Data lakes store all of an organization’s data, regardless of its format or structure.
Introduction Nowadays, organizations are looking for multiple solutions to deal with big data and related challenges. If you’re preparing for the Snowflake interview, […] The post A Comprehensive Guide Of Snowflake Interview Questions appeared first on Analytics Vidhya.
It serves as the primary means for communicating with relational databases, where most organizations store crucial data. SQL plays a significant role including analyzing complex data, creating data pipelines, and efficiently managing datawarehouses.
Unifying these necessitates additional data processing, requiring each business unit to provision and maintain a separate datawarehouse. This burdens business units focused solely on consuming the curated data for analysis and not concerned with data management tasks, cleansing, or comprehensive data processing.
Rapidminer is a visual enterprise data science platform that includes data extraction, data mining, deep learning, artificial intelligence and machine learning (AI/ML) and predictive analytics. It can support AI/ML processes with data preparation, model validation, results visualization and model optimization.
Introduction Amazon Elastic MapReduce (EMR) is a fully managed service that makes it easy to process large amounts of data using the popular open-source framework Apache Hadoop. EMR enables you to run petabyte-scale datawarehouses and analytics workloads using the Apache Spark, Presto, and Hadoop ecosystems.
This article was published as a part of the Data Science Blogathon. Introduction Apache Hive is a datawarehouse system built on top of Hadoop which gives the user the flexibility to write complex MapReduce programs in form of SQL- like queries.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud datawarehouses.
In our cutthroat digital age, the importance of setting the right data analysis questions can define the overall success of a business. That being said, it seems like we’re in the midst of a data analysis crisis. That being said, it seems like we’re in the midst of a data analysis crisis.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze your data using standard SQL and your existing business intelligence (BI) tools. Data ingestion is the process of getting data to Amazon Redshift.
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. If these concerns were not addressed, the customer would be prevented from growing their user base.
Talend data integration software offers an open and scalable architecture and can be integrated with multiple datawarehouses, systems and applications to provide a unified view of all data. Its code generation architecture uses a visual interface to create Java or SQL code.
Similarly, the data lakehouse, an architecture that features attributes of both the data lake and the datawarehouse, gained traction in 2020 and will continue to grow in prominence in 2021. Cloud datawarehouse engineering develops as a particular focus as database solutions move more and more to the cloud.
Introduction Amazon Redshift is a fully managed, petabyte-scale data warehousing Amazon Web Services (AWS). It allows users to easily set up, operate, and scale a datawarehouse in the cloud.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. Choose Launch Stack Choose Next.
It combines SQL analytics, data processing, AI development, data streaming, business intelligence, and search analytics. Another offering that AWS announced to support the integration is the SageMaker Data Lakehouse , aimed at helping enterprises unify data across Amazon S3 data lakes and Amazon Redshift datawarehouses.
BladeBridge offers a comprehensive suite of tools that automate much of the complex conversion work, allowing organizations to quickly and reliably transition their data analytics capabilities to the scalable Amazon Redshift datawarehouse. times better price performance than other cloud datawarehouses.
Introduction This article will introduce the concept of data modeling, a crucial process that outlines how data is stored, organized, and accessed within a database or data system. It involves converting real-world business needs into a logical and structured format that can be realized in a database or datawarehouse.
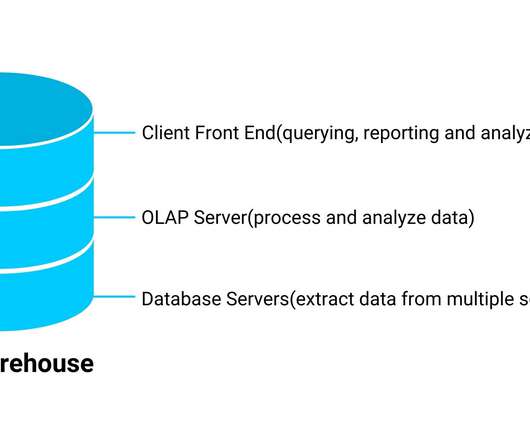
This article was published as a part of the Data Science Blogathon What is ETL? ETL is a process that extracts data from multiple source systems, changes it (through calculations, concatenations, and so on), and then puts it into the DataWarehouse system. ETL stands for Extract, Transform, and Load.
Oracle recently hosted its annual Database Analyst Summit, sharing the vision and strategy for its data platform. While much of the event was under non-disclosure as product plans and launch schedules are finalized, it still served as a useful recap of the broad portfolio of data platform capabilities that Oracle has to offer.
Although data forms the basis for effective and efficient analysis, large-scale data processing requires complete data-driven import and processing techniques […]. The post All About Data Pipeline and Its Components appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction Hive is a popular datawarehouse built on top of Hadoop that is used by companies like Walmart, Tiktok, and AT&T. It is an important technology for data engineers to learn and master.
Introduction Google’s BigQuery is a powerful cloud-based datawarehouse that provides fast, flexible, and cost-effective data storage and analysis capabilities. BigQuery was created to analyse data […] The post Building a Machine Learning Model in BigQuery appeared first on Analytics Vidhya.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content