This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Enterprise data is brought into data lakes and datawarehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. Table metadata is fetched from AWS Glue. The generated Athena SQL query is run.
We live in a data-rich, insights-rich, and content-rich world. Data collections are the ones and zeroes that encode the actionable insights (patterns, trends, relationships) that we seek to extract from our data through machinelearning and data science. Source: [link] I will finish with three quotes.
Data lakes and datawarehouses are probably the two most widely used structures for storing data. DataWarehouses and Data Lakes in a Nutshell. A datawarehouse is used as a central storage space for large amounts of structured data coming from various sources. Key Differences.
Amazon Redshift is a fully managed, AI-powered cloud datawarehouse that delivers the best price-performance for your analytics workloads at any scale. It enables you to get insights faster without extensive knowledge of your organization’s complex database schema and metadata. Your data is not shared across accounts.
The following requirements were essential to decide for adopting a modern data mesh architecture: Domain-oriented ownership and data-as-a-product : EUROGATE aims to: Enable scalable and straightforward data sharing across organizational boundaries. Eliminate centralized bottlenecks and complex data pipelines.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud datawarehouses.
This post was co-written with Dipankar Mazumdar, Staff Data Engineering Advocate with AWS Partner OneHouse. Data architecture has evolved significantly to handle growing data volumes and diverse workloads. In practice, OTFs are used in a broad range of analytical workloads, from business intelligence to machinelearning.
Now with Amazon Bedrock Knowledge Bases integration with structured data, you can use simple, natural language prompts to query complex financial datasets. From customer portals to internal dashboards and mobile apps, this API-driven approach makes enterprise-grade data analysis accessible to everyone in your organization. Choose Next.
Performance is one of the key, if not the most important deciding criterion, in choosing a Cloud DataWarehouse service. In today’s fast changing world, enterprises have to make data driven decisions quickly and for that they rely heavily on their datawarehouse service. . Cloudera DataWarehouse vs HDInsight.
Our customers are telling us that they are seeing their analytics and AI workloads increasingly converge around a lot of the same data, and this is changing how they are using analytics tools with their data. This innovation drives an important change: you’ll no longer have to copy or move data between data lake and datawarehouses.
In this blog post, we compare Cloudera DataWarehouse (CDW) on Cloudera Data Platform (CDP) using Apache Hive-LLAP to EMR 6.0 (also powered by Apache Hive-LLAP) on Amazon using the TPC-DS 2.9 Cloudera DataWarehouse vs EMR. Learn more about Cloudera DataWarehouse on CDP.
What enables you to use all those gigabytes and terabytes of data you’ve collected? Metadata is the pertinent, practical details about data assets: what they are, what to use them for, what to use them with. Without metadata, data is just a heap of numbers and letters collecting dust. Where does metadata come from?
Cloud datawarehouses allow users to run analytic workloads with greater agility, better isolation and scale, and lower administrative overhead than ever before. The results demonstrate superior price performance of Cloudera DataWarehouse on the full set of 99 queries from the TPC-DS benchmark. Introduction.
Making a decision on a cloud datawarehouse is a big deal. Modernizing your data warehousing experience with the cloud means moving from dedicated, on-premises hardware focused on traditional relational analytics on structured data to a modern platform.
First-generation – expensive, proprietary enterprise datawarehouse and business intelligence platforms maintained by a specialized team drowning in technical debt. Second-generation – gigantic, complex data lake maintained by a specialized team drowning in technical debt.
These nodes can implement analytical platforms like data lake houses, datawarehouses, or data marts, all united by producing data products. The Institutional Data & AI platform adopts a federated approach to data while centralizing the metadata to facilitate simpler discovery and sharing of data products.
Amazon Redshift Serverless makes it simple to run and scale analytics without having to manage your datawarehouse infrastructure. Tags allows you to assign metadata to your AWS resources. You can define your own key and value for your resource tag, so that you can easily manage and filter your resources.
In this example, the MachineLearning (ML) model struggles to differentiate between a chihuahua and a muffin. We will learn what it is, why it is important and how Cloudera MachineLearning (CML) is helping organisations tackle this challenge as part of the broader objective of achieving Ethical AI.
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
The new, industry-targeted data management platforms — Intelligent Data Management Cloud for Health and Life Sciences and the Intelligent Data Management Cloud for Financial Services — were announced at the company’s Informatica World conference Tuesday. Intelligent Data Management Cloud for Health and Life Sciences.
We also examine how centralized, hybrid and decentralized data architectures support scalable, trustworthy ecosystems. As data-centric AI, automated metadata management and privacy-aware data sharing mature, the opportunity to embed data quality into the enterprises core has never been more significant.
In this blog, we will share with you in detail how Cloudera integrates core compute engines including Apache Hive and Apache Impala in Cloudera DataWarehouse with Iceberg. In a bit more detail, Iceberg V1 added support for creating, updating, deleting and inserting data into tables.
Once the province of the datawarehouse team, data management has increasingly become a C-suite priority, with data quality seen as key for both customer experience and business performance. But along with siloed data and compliance concerns , poor data quality is holding back enterprise AI projects.
In 2013, Amazon Web Services revolutionized the data warehousing industry by launching Amazon Redshift , the first fully-managed, petabyte-scale, enterprise-grade cloud datawarehouse. Amazon Redshift made it simple and cost-effective to efficiently analyze large volumes of data using existing business intelligence tools.
Amazon SageMaker Introducing the next generation of Amazon SageMaker AWS announces the next generation of Amazon SageMaker, a unified platform for data, analytics, and AI. S3 Metadata is designed to automatically capture metadata from objects as they are uploaded into a bucket, and to make that metadata queryable in a read-only table.
Is your data going somewhere? No, we’re not talking about databases going AWOL or datawarehouses getting a little R&R at the beach. We’re talking about migrations from one system to another, or combining data from different systems into a single system or warehouse. Data Dictionaries.
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered cloud datawarehouse, delivering the best price-performance for your analytics workloads. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
How self-service data warehousing frees IT resources. Cloudera DataWarehouse (CDW) is a cloud service and an integral part of the newly released Cloudera Data Platform (CDP). Key features are: Highly scalable and performant open-source engines for BI and data warehousing workloads. Simplified provisioning.
Data engineers use Apache Iceberg because it’s fast, efficient, and reliable at any scale and keeps records of how datasets change over time. Apache Iceberg offers integrations with popular data processing frameworks such as Apache Spark, Apache Flink, Apache Hive, Presto, and more.
This amalgamation empowers vendors with authority over a diverse range of workloads by virtue of owning the data. This authority extends across realms such as business intelligence, data engineering, and machinelearning thus limiting the tools and capabilities that can be used. Here is where it can get complicated.
ActionIQ is a leading composable customer data (CDP) platform designed for enterprise brands to grow faster and deliver meaningful experiences for their customers. This post will demonstrate how ActionIQ built a connector for Amazon Redshift to tap directly into your datawarehouse and deliver a secure, zero-copy CDP.
Data architect Armando Vázquez identifies eight common types of data architects: Enterprise data architect: These data architects oversee an organization’s overall data architecture, defining data architecture strategy and designing and implementing architectures.
But the data repository options that have been around for a while tend to fall short in their ability to serve as the foundation for big data analytics powered by AI. Traditional datawarehouses, for example, support datasets from multiple sources but require a consistent data structure.
We are proud to announce the general availability of Cloudera Altus DataWarehouse , the only cloud data warehousing service that brings the warehouse to the data. Modern data warehousing for the cloud. Modern data warehousing for the cloud. Using Cloudera Altus for your cloud datawarehouse.
After some impressive advances over the past decade, largely thanks to the techniques of MachineLearning (ML) and Deep Learning , the technology seems to have taken a sudden leap forward. With watsonx.data , businesses can quickly connect to data, get trusted insights and reduce datawarehouse costs.
Cloudera customers run some of the biggest data lakes on earth. These lakes power mission critical large scale data analytics, business intelligence (BI), and machinelearning use cases, including enterprise datawarehouses. On datawarehouses and data lakes.
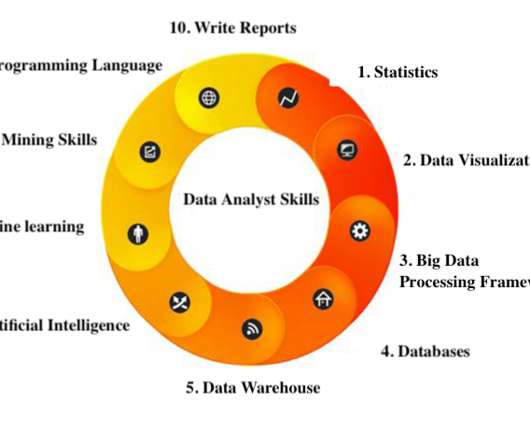
Software Pemvisualisasi Data: excel, python, software profesional lainnya. Framework Big Data Processing: Hadoop, storm, spark. Data Warehous: SSIS, SSAS. Machinelearning. Skill Data Mining: Matlab, R, Python. Seperti yang Anda ketahui, statistik adalah dasar analisis data. DataWarehouse.
The need for an end-to-end strategy for data management and data governance at every step of the journey—from ingesting, storing, and querying data to analyzing, visualizing, and running artificial intelligence (AI) and machinelearning (ML) models—continues to be of paramount importance for enterprises.
In other words, using metadata about data science work to generate code. In this case, code gets generated for data preparation, where so much of the “time and labor” in data science work is concentrated. Doesn’t this seem like a worthy goal for machinelearning—to make the machineslearn to work more effectively?
Human Curation + MachineLearning. The way Herschel, Fry, and Zimmerman talked about AI in many respects reflects our vision for machinelearningdata catalogs. What’s more, Zaidi and Gartner believe that this vision of a machine-learning-enabled data catalog creates real value for enterprises.
Cloudera customers run some of the biggest data lakes on earth. These lakes power mission critical large scale data analytics, business intelligence (BI), and machinelearning use cases, including enterprise datawarehouses. On datawarehouses and data lakes.
Source systems Aruba’s source repository includes data from three different operating regions in AMER, EMEA, and APJ, along with one worldwide (WW) data pipeline from varied sources like SAP S/4 HANA, Salesforce, Enterprise DataWarehouse (EDW), Enterprise Analytics Platform (EAP) SharePoint, and more.
Organizations have multiple Hive datawarehouses across EMR clusters, where the metadata gets generated. To address this challenge, organizations can deploy a data mesh using AWS Lake Formation that connects the multiple EMR clusters. An entity can act both as a producer of data assets and as a consumer of data assets.
SageMaker Lakehouse is a unified, open, and secure data lakehouse that now supports ABAC to provide unified access to general purpose Amazon S3 buckets, Amazon S3 Tables , Amazon Redshift datawarehouses, and data sources such as Amazon DynamoDB or PostgreSQL.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content