This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This organism is the cornerstone of a companys competitive advantage, necessitating careful and responsible nurturing and management. To succeed in todays landscape, every company small, mid-sized or large must embrace a data-centric mindset. The choice of vendors should align with the broader cloud or on-premises strategy.
Now with Amazon Bedrock Knowledge Bases integration with structured data, you can use simple, natural language prompts to query complex financial datasets. From customer portals to internal dashboards and mobile apps, this API-driven approach makes enterprise-grade data analysis accessible to everyone in your organization.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud datawarehouses.
BladeBridge offers a comprehensive suite of tools that automate much of the complex conversion work, allowing organizations to quickly and reliably transition their data analytics capabilities to the scalable Amazon Redshift datawarehouse. times better price performance than other cloud datawarehouses.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze your data using standard SQL and your existing business intelligence (BI) tools. Data ingestion is the process of getting data to Amazon Redshift.
Unlocking the true value of data often gets impeded by siloed information. Traditional datamanagement—wherein each business unit ingests raw data in separate data lakes or warehouses—hinders visibility and cross-functional analysis.
Data lakes and datawarehouses are two of the most important data storage and management technologies in a modern data architecture. Data lakes store all of an organization’s data, regardless of its format or structure. Delta Lake doesn’t have a specific concept for incremental queries.
Amazon Redshift is a fully managed, AI-powered cloud datawarehouse that delivers the best price-performance for your analytics workloads at any scale. Refer to Easy analytics and cost-optimization with Amazon Redshift Serverless to get started. For this post, we use Redshift Serverless.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that you can use to analyze your data at scale. Reusing database sessions to simplify the connection management logic in your API implementation, reducing the complexity of the code and making it more straightforward to maintain and scale.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
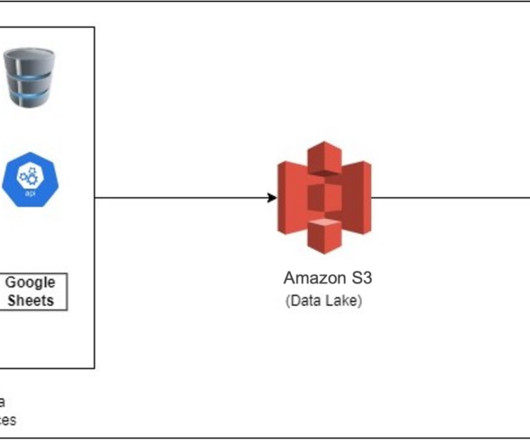
In this post, we show you how to establish the data ingestion pipeline between Google Analytics 4, Google Sheets, and an Amazon Redshift Serverless workgroup. It also helps you securely access your data in operational databases, data lakes, or third-party datasets with minimal movement or copying of data.
Amazon Redshift Serverless makes it simple to run and scale analytics without having to manage your datawarehouse infrastructure. You can define your own key and value for your resource tag, so that you can easily manage and filter your resources. Tags allows you to assign metadata to your AWS resources.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that lets you analyze your data at scale. Amazon Redshift Serverless lets you access and analyze data without the usual configurations of a provisioned datawarehouse. Choose a query to view it in Query profiler.
The landscape of big datamanagement has been transformed by the rising popularity of open table formats such as Apache Iceberg, Apache Hudi, and Linux Foundation Delta Lake. These formats, designed to address the limitations of traditional data storage systems, have become essential in modern data architectures.
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. Solution overview Amazon Redshift is an industry-leading cloud datawarehouse.
1) What Is Data Quality Management? 4) Data Quality Best Practices. 5) How Do You Measure Data Quality? 6) Data Quality Metrics Examples. 7) Data Quality Control: Use Case. 8) The Consequences Of Bad Data Quality. 9) 3 Sources Of Low-Quality Data. 10) Data Quality Solutions: Key Attributes.
This puts tremendous stress on the teams managingdatawarehouses, and they struggle to keep up with the demand for increasingly advanced analytic requests. To gather and clean data from all internal systems and gain the business insights needed to make smarter decisions, businesses need to invest in datawarehouse automation.
Ask questions in plain English to find the right datasets, automatically generate SQL queries, or create data pipelines without writing code. This innovation drives an important change: you’ll no longer have to copy or move data between data lake and datawarehouses.
Amazon SageMaker Lakehouse now supports attribute-based access control (ABAC) with AWS Lake Formation , using AWS Identity and Access Management (IAM) principals and session tags to simplify data access, grant creation, and maintenance.
Although traditional scaling primarily responds to query queue times, the new AI-driven scaling and optimization feature offers a more sophisticated approach by considering multiple factors including query complexity and data volume. Our findings serve as a reference point rather than a universal benchmark.
Below is our fourth post (4 of 5) on combining data mesh with DataOps to foster innovation while addressing the challenges of a decentralized architecture. We’ve covered the basic ideas behind data mesh and some of the difficulties that must be managed. The third set of domains are cached data sets (e.g.,
With Amazon Redshift, you can use standard SQL to query data across your datawarehouse, operational data stores, and data lake. Migrating a datawarehouse can be complex. You have to migrate terabytes or petabytes of data from your legacy system while not disrupting your production workload.
One-time and complex queries are two common scenarios in enterprise data analytics. Complex queries, on the other hand, refer to large-scale data processing and in-depth analysis based on petabyte-level datawarehouses in massive data scenarios. Here, data modeling uses dbt on Amazon Redshift.
Amazon DynamoDB is a fully managed NoSQL service that delivers single-digit millisecond performance at any scale. These types of queries are suited for a datawarehouse. Amazon Redshift is fully managed, scalable, cloud datawarehouse. It’s used by thousands of customers for mission-critical workloads.
“Without big data, you are blind and deaf and in the middle of a freeway.” – Geoffrey Moore, management consultant, and author. In a world dominated by data, it’s more important than ever for businesses to understand how to extract every drop of value from the raft of digital insights available at their fingertips.
To overcome these challenges, businesses need a solution that can provide near-real-time analytics on transactional data with services that don’t lead to latent processing and bloat from managing the pipeline. Solution overview The most common workloads, agnostic of industry, involve transactional data.
Tens of thousands of customers use Amazon Redshift for modern data analytics at scale, delivering up to three times better price-performance and seven times better throughput than other cloud datawarehouses. To maintain the right level of access, the company wants to restrict data visibility based on the users role and region.
Since software engineers manage to build ordinary software without experiencing as much pain as their counterparts in the ML department, it begs the question: should we just start treating ML projects as software engineering projects as usual, maybe educating ML practitioners about the existing best practices? Orchestration. Versioning.
In this post, we discuss how the Kaplan data engineering team implemented data integration from the Salesforce application to Amazon Redshift. Solution overview The high-level data flow starts with the source data stored in Amazon S3 and then integrated into Amazon Redshift using various AWS services.
This means you can refine your ETL jobs through natural follow-up questionsstarting with a basic data pipeline and progressively adding transformations, filters, and business logic through conversation. The DataFrame code generation now extends beyond AWS Glue DynamicFrame to support a broader range of data processing scenarios.
Interestingly, you can address many of them very effectively with a datawarehouse. The DataWarehouse Solution. Now consider an alternative that does not occur to most ERP system managers: A datawarehouse with data from your old ERP system that provides all the information you need for historical reference.
Amazon Redshift is the most widely used datawarehouse in the cloud, best suited for analyzing exabytes of data and running complex analytical queries. Amazon QuickSight is a fast business analytics service to build visualizations, perform ad hoc analysis, and quickly get business insights from your data.
As the world is gradually becoming more dependent on data, the services, tools and infrastructure are all the more important for businesses in every sector. Datamanagement has become a fundamental business concern, and especially for businesses that are going through a digital transformation. What is datamanagement?
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud that delivers powerful and secure insights on all your data with the best price-performance. With Amazon Redshift, you can analyze your data to derive holistic insights about your business and your customers.
Enterprise data is brought into data lakes and datawarehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. Choose Manage model access. Change the AWS Region to US West (Oregon).
Amazon Redshift features like streaming ingestion, Amazon Aurora zero-ETL integration , and data sharing with AWS Data Exchange enable near-real-time processing for trade reporting, risk management, and trade optimization. This will be your OLTP data store for transactional data. version cluster. version cluster.
Structured Query Language (SQL) is the most popular language utilized to create, access, manipulate, query, and manage databases. But before we do, let’s explore some interesting SQL facts: SQL assists in the structuring and management of information in a database, in addition to conducting searches for information using structures.
dbt is an open source, SQL-first templating engine that allows you to write repeatable and extensible data transforms in Python and SQL. dbt is predominantly used by datawarehouses (such as Amazon Redshift ) customers who are looking to keep their data transform logic separate from storage and engine.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud. With Amazon Redshift, you can analyze all your data to derive holistic insights about your business and your customers. Amazon Redshift now supports custom URLs or custom domain names for your datawarehouse.
Running a business can be tricky if you fail to implement the correct business management tools. Achieving your company’s target goals can, however, be difficult if you’re unable to access all the relevant and useful data your business has. What is big data used for? Is Google BigQuery the future of big data analytics?
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
Amazon Redshift has established itself as a highly scalable, fully managed cloud datawarehouse trusted by tens of thousands of customers for its superior price-performance and advanced data analytics capabilities. This allows you to maintain a comprehensive view of your data while optimizing for cost-efficiency.
Data architect role Data architects are senior visionaries who translate business requirements into technology requirements and define data standards and principles, often in support of data or digital transformations. Data architects are frequently part of a data science team and tasked with leading data system projects.
Amazon Redshift is a fast, petabyte-scale, cloud datawarehouse that tens of thousands of customers rely on to power their analytics workloads. With its massively parallel processing (MPP) architecture and columnar data storage, Amazon Redshift delivers high price-performance for complex analytical queries against large datasets.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content