This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data lakes and datawarehouses are probably the two most widely used structures for storing data. DataWarehouses and Data Lakes in a Nutshell. A datawarehouse is used as a central storage space for large amounts of structured data coming from various sources. Key Differences.
You can learn how to query Delta Lake native tables through UniForm from different datawarehouses or engines such as Amazon Redshift as an example of expanding data access to more engines. Both Delta Lake and Iceberg metadata files reference the same data files.
This post was co-written with Dipankar Mazumdar, Staff Data Engineering Advocate with AWS Partner OneHouse. Data architecture has evolved significantly to handle growing data volumes and diverse workloads. The synchronization process in XTable works by translating table metadata using the existing APIs of these table formats.
Amazon Redshift is a fully managed, AI-powered cloud datawarehouse that delivers the best price-performance for your analytics workloads at any scale. It enables you to get insights faster without extensive knowledge of your organization’s complex database schema and metadata. Your data is not shared across accounts.
As part of the Talent Intelligence Platform Eightfold also exposes a data hub where each customer can access their Amazon Redshift-based datawarehouse and perform ad hoc queries as well as schedule queries for reporting and data export. Many customers have implemented Amazon Redshift to support multi-tenant applications.
BladeBridge offers a comprehensive suite of tools that automate much of the complex conversion work, allowing organizations to quickly and reliably transition their data analytics capabilities to the scalable Amazon Redshift datawarehouse. times better price performance than other cloud datawarehouses.
What enables you to use all those gigabytes and terabytes of data you’ve collected? Metadata is the pertinent, practical details about data assets: what they are, what to use them for, what to use them with. Without metadata, data is just a heap of numbers and letters collecting dust. Where does metadata come from?
The past decades of enterprise data platform architectures can be summarized in 69 words. First-generation – expensive, proprietary enterprise datawarehouse and business intelligence platforms maintained by a specialized team drowning in technical debt. The organizational concepts behind data mesh are summarized as follows.
One of the BI architecture components is data warehousing. Organizing, storing, cleaning, and extraction of the data must be carried by a central repository system, namely datawarehouse, that is considered as the fundamental component of business intelligence. What Is Data Warehousing And Business Intelligence?
Collaborate and build faster using familiar AWS tools for model development, generative AI, data processing, and SQL analytics with Amazon Q Developer , the most capable generative AI assistant for software development, helping you along the way. Having confidence in your data is key.
We also examine how centralized, hybrid and decentralized data architectures support scalable, trustworthy ecosystems. As data-centric AI, automated metadata management and privacy-aware data sharing mature, the opportunity to embed data quality into the enterprises core has never been more significant.
It’s costly and time-consuming to manage on-premises datawarehouses — and modern cloud data architectures can deliver business agility and innovation. However, CIOs declare that agility, innovation, security, adopting new capabilities, and time to value — never cost — are the top drivers for cloud data warehousing.
We realized we needed a datawarehouse to cater to all of these consumer requirements, so we evaluated Amazon Redshift. At the same time, we had to find a way to implement entitlements in our Amazon Redshift datawarehouse with the same set of tags that we had already defined in Lake Formation.
Once the province of the datawarehouse team, data management has increasingly become a C-suite priority, with data quality seen as key for both customer experience and business performance. But along with siloed data and compliance concerns , poor data quality is holding back enterprise AI projects.
It was not until the addition of open table formats— specifically Apache Hudi, Apache Iceberg and Delta Lake—that data lakes truly became capable of supporting multiple business intelligence (BI) projects as well as data science and even operational applications and, in doing so, began to evolve into data lakehouses.
The company said that IDMC for Financial Services has built-in metadata scanners that can help extract lineage, technical, business, operational, and usage metadata from over 50,000 systems (including datawarehouses and data lakes) and applications including business intelligence, data science, CRM, and ERP software.
Requests for IT resources for data and compute services can’t be delayed three to six months, which is how long the typical procurement cycle, machine configuration, and software installation takes. How self-service data warehousing frees IT resources. SDX is also the key to serve multiple workloads on the same data.
The data you’ve collected and saved over the years isn’t free. If storage costs are escalating in a particular area, you may have found a good source of dark data. Analyze your metadata. If you’ve yet to implement data governance, this is another great reason to get moving quickly. Data sense-making.
There’s not much value in holding on to raw data without putting it to good use, yet as the cost of storage continues to decrease, organizations find it useful to collect raw data for additional processing. The raw data can be fed into a database or datawarehouse. It’s a good idea to record metadata.
Solutions data architect: These individuals design and implement data solutions for specific business needs, including datawarehouses, data marts, and data lakes. Application data architect: The application data architect designs and implements data models for specific software applications.
With quality data at their disposal, organizations can form datawarehouses for the purposes of examining trends and establishing future-facing strategies. Industry-wide, the positive ROI on quality data is well understood. Business/Data Analyst: The business analyst is all about the “meat and potatoes” of the business.
As he put it, “We are describing our business process and we are trying to describe our data catalog. His team also is using the software to manage roadmaps in their main transformation programs. He added, “We have also linked it to our documentation repository, so we have a description of our data documents.” George H.,
But the data repository options that have been around for a while tend to fall short in their ability to serve as the foundation for big data analytics powered by AI. Traditional datawarehouses, for example, support datasets from multiple sources but require a consistent data structure.
When evolving such a partition definition, the data in the table prior to the change is unaffected, as is its metadata. Only data that is written to the table after the evolution is partitioned with the new definition, and the metadata for this new set of data is kept separately. SparkActions.get().expireSnapshots(iceTable).expireOlderThan(TimeUnit.DAYS.toMillis(7)).execute()
“The data catalog is critical because it’s where business manages its metadata,” said Venkat Rajaji, Senior Vice President of Product Management at Cloudera. There’s been a ton of innovation lately around the Iceberg REST catalog because the data turf war is over. But the metadata turf war is just getting started.”
Quick setup enables two default blueprints and creates the default environment profiles for the data lake and datawarehouse default blueprints. You will then publish the data assets from these data sources. Add an AWS Glue data source to publish the new AWS Glue table. Review and choose Create.
BI software helps companies do just that by shepherding the right data into analytical reports and visualizations so that users can make informed decisions. Stout, for instance, explains how Schellman addresses integrating its customer relationship management (CRM) and financial data. “A
All this data arrives by the terabyte, and a data management platform can help marketers make sense of it all. Marketing-focused or not, DMPs excel at negotiating with a wide array of databases, data lakes, or datawarehouses, ingesting their streams of data and then cleaning, sorting, and unifying the information therein.
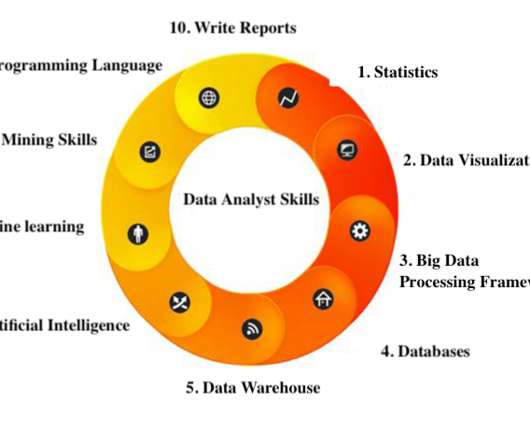
Berdasarkan pengalaman saya secara bertahun-tahun, saya merangkum sepuluh skill yang perlu dikuasai seorang data analyst senior dan memiliki kualifikasi. Software Pemvisualisasi Data: excel, python, software profesional lainnya. Framework Big Data Processing: Hadoop, storm, spark. Data Warehous: SSIS, SSAS.
But whatever their business goals, in order to turn their invisible data into a valuable asset, they need to understand what they have and to be able to efficiently find what they need. Enter metadata. It enables us to make sense of our data because it tells us what it is and how best to use it. Knowledge (metadata) layer.
Apache Iceberg is an open table format for very large analytic datasets, which captures metadata information on the state of datasets as they evolve and change over time. Iceberg has become very popular for its support for ACID transactions in data lakes and features like schema and partition evolution, time travel, and rollback.
ActionIQ is a leading composable customer data (CDP) platform designed for enterprise brands to grow faster and deliver meaningful experiences for their customers. This post will demonstrate how ActionIQ built a connector for Amazon Redshift to tap directly into your datawarehouse and deliver a secure, zero-copy CDP.
In 2013, Amazon Web Services revolutionized the data warehousing industry by launching Amazon Redshift , the first fully-managed, petabyte-scale, enterprise-grade cloud datawarehouse. Amazon Redshift made it simple and cost-effective to efficiently analyze large volumes of data using existing business intelligence tools.
To better understand and align data governance and enterprise architecture, let’s look at data at rest and data in motion and why they both have to be documented. Documenting data at rest involves looking at where data is stored, such as in databases, data lakes , datawarehouses and flat files.
Amazon Redshift is a widely used, fully managed, petabyte-scale cloud datawarehouse. Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytic workloads. This JSON file contains the migration metadata, namely the following: A list of Google BigQuery projects and datasets.
Data visualization is a concept that describes any effort to help people understand the significance of data by placing it in a visual context. Patterns, trends and correlations that may go unnoticed in text-based data can be more easily exposed and recognized with data visualization software.
With change log view, we can easily track insertions, updates, and deletions, giving us a complete picture of how our data has evolved. For our heater example, Icebergs change log view would allow us to effortlessly retrieve a timeline of all price changes, complete with timestamps and other relevant metadata, as shown in the following table.
First, many LLM use cases rely on enterprise knowledge that needs to be drawn from unstructured data such as documents, transcripts, and images, in addition to structured data from datawarehouses. Data enrichment In addition, additional metadata may need to be extracted from the objects.
This is done by mining complex data using BI software and tools , comparing data to competitors and industry trends, and creating visualizations that communicate findings to others in the organization. Real-time problem-solving exercises using Excel or other BI tools. More on BI: What is business intelligence?
Enterprises need to be able to easily and securely move AI workloads around, and in today’s world that can mean across cloud, as well as modern and legacy software and hardware systems. With watsonx.data , businesses can quickly connect to data, get trusted insights and reduce datawarehouse costs.
The construction of big data applications based on open source software has become increasingly uncomplicated since the advent of projects like Data on EKS , an open source project from AWS to provide blueprints for building data and machine learning (ML) applications on Amazon Elastic Kubernetes Service (Amazon EKS).
Previously we would have a very laborious datawarehouse or data mart initiative and it may take a very long time and have a large price tag. He added, “Most organizations are well-versed in software and application development. Bergh added, “ DataOps is part of the data fabric. DataOps is a complementary process.
Aruba offers networking hardware like access points, switches, routers, software, security devices, and Internet of Things (IoT) products. The data sources include 150+ files including 10-15 mandatory files per region ingested in various formats like xlxs, csv, and dat. The following diagram illustrates the solution architecture.
In response, Lenovo launched a new line of entry-level gaming laptops and desktops it now brands as Lenovo LOQ that caters to a new gamer’s first foray into gaming, says Girish Hoogar, global head of engineering for Lenovo’s cloud and software business in its Intelligent Devices Group.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content