This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
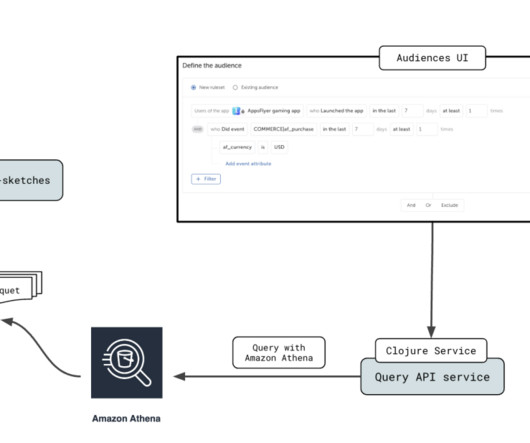
Enterprise data is brought into data lakes and datawarehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. Table metadata is fetched from AWS Glue. The generated Athena SQL query is run.
This post was co-written with Dipankar Mazumdar, Staff Data Engineering Advocate with AWS Partner OneHouse. Data architecture has evolved significantly to handle growing data volumes and diverse workloads. The synchronization process in XTable works by translating table metadata using the existing APIs of these table formats.
Amazon Redshift is a fully managed, AI-powered cloud datawarehouse that delivers the best price-performance for your analytics workloads at any scale. It enables you to get insights faster without extensive knowledge of your organization’s complex database schema and metadata. Your data is not shared across accounts.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud datawarehouses.
As part of the Talent Intelligence Platform Eightfold also exposes a data hub where each customer can access their Amazon Redshift-based datawarehouse and perform ad hoc queries as well as schedule queries for reporting and data export. Many customers have implemented Amazon Redshift to support multi-tenant applications.
Metadata management is key to wringing all the value possible from data assets. However, most organizations don’t use all the data at their disposal to reach deeper conclusions about how to drive revenue, achieve regulatory compliance or accomplish other strategic objectives. What Is Metadata? Harvest data.
In this blog post, we compare Cloudera DataWarehouse (CDW) on Cloudera Data Platform (CDP) using Apache Hive-LLAP to EMR 6.0 (also powered by Apache Hive-LLAP) on Amazon using the TPC-DS 2.9 CDW runs the TPC-DS benchmark test suite more than 3x faster than EMR – 3 hours vs 11 hours (see Figure 1).
Organization’s cannot hope to make the most out of a data-driven strategy, without at least some degree of metadata-driven automation. The volume and variety of data has snowballed, and so has its velocity. As such, traditional – and mostly manual – processes associated with data management and data governance have broken down.
Making a decision on a cloud datawarehouse is a big deal. Modernizing your data warehousing experience with the cloud means moving from dedicated, on-premises hardware focused on traditional relational analytics on structured data to a modern platform.
Cloud datawarehouses allow users to run analytic workloads with greater agility, better isolation and scale, and lower administrative overhead than ever before. The results demonstrate superior price performance of Cloudera DataWarehouse on the full set of 99 queries from the TPC-DS benchmark. Introduction. higher cost.
Amazon Redshift is a fast, petabyte-scale, cloud datawarehouse that tens of thousands of customers rely on to power their analytics workloads. With its massively parallel processing (MPP) architecture and columnar data storage, Amazon Redshift delivers high price-performance for complex analytical queries against large datasets.
The past decades of enterprise data platform architectures can be summarized in 69 words. First-generation – expensive, proprietary enterprise datawarehouse and business intelligence platforms maintained by a specialized team drowning in technical debt. The organizational concepts behind data mesh are summarized as follows.
Amazon SageMaker Lakehouse provides an open data architecture that reduces data silos and unifies data across Amazon Simple Storage Service (Amazon S3) data lakes, Redshift datawarehouses, and third-party and federated data sources. With AWS Glue 5.0, AWS Glue 5.0 Finally, AWS Glue 5.0
Cloudera Contributors: Ayush Saxena, Tamas Mate, Simhadri Govindappa Since we announced the general availability of Apache Iceberg in Cloudera Data Platform (CDP), we are excited to see customers testing their analytic workloads on Iceberg. We will publish follow up blogs for other data services.
Once the province of the datawarehouse team, data management has increasingly become a C-suite priority, with data quality seen as key for both customer experience and business performance. But along with siloed data and compliance concerns , poor data quality is holding back enterprise AI projects.
Many of the tests to check performance and volumes of data scanned have used Athena because it provides a simple to use, fully serverless, cost effective, interface without the need to setup infrastructure. When evolving such a partition definition, the data in the table prior to the change is unaffected, as is its metadata.
Data in Place refers to the organized structuring and storage of data within a specific storage medium, be it a database, bucket store, files, or other storage platforms. In the contemporary data landscape, data teams commonly utilize datawarehouses or lakes to arrange their data into L1, L2, and L3 layers.
ActionIQ is a leading composable customer data (CDP) platform designed for enterprise brands to grow faster and deliver meaningful experiences for their customers. This post will demonstrate how ActionIQ built a connector for Amazon Redshift to tap directly into your datawarehouse and deliver a secure, zero-copy CDP.
Apache Iceberg is an open table format for very large analytic datasets, which captures metadata information on the state of datasets as they evolve and change over time. Iceberg has become very popular for its support for ACID transactions in data lakes and features like schema and partition evolution, time travel, and rollback.
Data architect Armando Vázquez identifies eight common types of data architects: Enterprise data architect: These data architects oversee an organization’s overall data architecture, defining data architecture strategy and designing and implementing architectures.
Organizations have multiple Hive datawarehouses across EMR clusters, where the metadata gets generated. To address this challenge, organizations can deploy a data mesh using AWS Lake Formation that connects the multiple EMR clusters. Test access using Athena queries in the consumer account.
In 2013, Amazon Web Services revolutionized the data warehousing industry by launching Amazon Redshift , the first fully-managed, petabyte-scale, enterprise-grade cloud datawarehouse. Amazon Redshift made it simple and cost-effective to efficiently analyze large volumes of data using existing business intelligence tools.
It also makes it easier for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization to discover, use, and collaborate to derive data-driven insights. The producer also needs to manage and publish the data asset so it’s discoverable throughout the organization.
Many customers run big data workloads such as extract, transform, and load (ETL) on Apache Hive to create a datawarehouse on Hadoop. We split the solution into two primary components: generating Spark job metadata and running the SQL on Amazon EMR. The script generates a metadata JSON file for each step.
Source systems Aruba’s source repository includes data from three different operating regions in AMER, EMEA, and APJ, along with one worldwide (WW) data pipeline from varied sources like SAP S/4 HANA, Salesforce, Enterprise DataWarehouse (EDW), Enterprise Analytics Platform (EAP) SharePoint, and more.
Amazon Redshift is a popular cloud datawarehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
Amazon Redshift , the most widely used cloud datawarehouse, has evolved significantly to meet the performance requirements of the most demanding workloads. This post covers one such new feature—the multidimensional data layout sort key. Milind Oke is a DataWarehouse Specialist Solutions Architect based out of New York.
This is done by mining complex data using BI software and tools , comparing data to competitors and industry trends, and creating visualizations that communicate findings to others in the organization.
Cloudera and Accenture demonstrate strength in their relationship with an accelerator called the Smart Data Transition Toolkit for migration of legacy datawarehouses into Cloudera Data Platform. Accenture’s Smart Data Transition Toolkit . Are you looking for your datawarehouse to support the hybrid multi-cloud?
A data catalog benefits organizations in a myriad of ways. With the right data catalog tool, organizations can automate enterprise metadata management – including data cataloging, data mapping, data quality and code generation for faster time to value and greater accuracy for data movement and/or deployment projects.
With quality data at their disposal, organizations can form datawarehouses for the purposes of examining trends and establishing future-facing strategies. Industry-wide, the positive ROI on quality data is well understood. 2 – Data profiling. Data profiling is an essential process in the DQM lifecycle.
Additionally, we discuss the thorough testing, monitoring, and rollout process that resulted in a successful transition to the new Athena architecture. million) that it loaded from the AWS Glue Data Catalog (for more information about using Athena with AWS Glue, see Integration with AWS Glue ).
Amazon Redshift is a popular cloud datawarehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
Performance was tested on a Redshift serverless datawarehouse with 128 RPU. In our testing, the dataset was stored in Amazon S3 in Parquet format and AWS Glue Data Catalog was used to manage external databases and tables. He works on the intersection of data lakes and datawarehouses.
In the modern data stack, dbt is a key tool to make data ready for analysis. Data analysts and engineers use dbt to transform, test, and document data in the cloud datawarehouse. Yet every dbt transformation contains vital metadata that is not captured – until now. Conclusion.
It seamlessly consolidates data from various data sources within AWS, including AWS Cost Explorer (and forecasting with Cost Explorer ), AWS Trusted Advisor , and AWS Compute Optimizer. Data providers and consumers are the two fundamental users of a CDH dataset.
Today, customers are embarking on data modernization programs by migrating on-premises datawarehouses and data lakes to the AWS Cloud to take advantage of the scale and advanced analytical capabilities of the cloud. In addition, you can select Add new columns to indicate data quality errors.
All this data arrives by the terabyte, and a data management platform can help marketers make sense of it all. Marketing-focused or not, DMPs excel at negotiating with a wide array of databases, data lakes, or datawarehouses, ingesting their streams of data and then cleaning, sorting, and unifying the information therein.
This post is co-authored by Vijay Gopalakrishnan, Director of Product, Salesforce Data Cloud. In today’s data-driven business landscape, organizations collect a wealth of data across various touch points and unify it in a central datawarehouse or a data lake to deliver business insights.
We live in a data-producing world, and as companies want to become data driven, there is the need to analyze more and more data. These analyses are often done using datawarehouses. Status quo before migration Here at OLX Group, Amazon Redshift has been our choice for datawarehouse for over 5 years.
With in-place table migration, you can rapidly convert to Iceberg tables since there is no need to regenerate data files. Only metadata will be regenerated. Newly generated metadata will then point to source data files as illustrated in the diagram below. . Data quality using table rollback. Metadata management .
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud. You can start with just a few hundred gigabytes of data and scale to a petabyte or more. This enables you to use your data to acquire new insights for your business and customers. Document the entire disaster recovery process.
As the queries finish running, an UNLOAD operation is invoked from the Redshift datawarehouse to the S3 bucket in Account A. The policies attached to the Amazon MWAA role have full access and must only be used for testing purposes in a secure test environment. Test the connection, then save your settings.
At the data pipeline level, scientists use Apigee, Airflow, NiFi, and Kafka. At the datawarehouse level, scientists use Redshift. As you go up the stack, different data analytics come into play, such as DataIQ. “And some things [Regeneron’s scientists] can only try out in the Google cloud.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content