This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Content includes reports, documents, articles, presentations, visualizations, video, and audio representations of the insights and knowledge that have been extracted from data. This is where SAP Datasphere (the next generation of SAP DataWarehouse Cloud) comes in.
There are countless examples of big data transforming many different industries. It can be used for something as visual as reducing traffic jams, to personalizing products and services, to improving the experience in multiplayer video games. We would like to talk about datavisualization and its role in the big data movement.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud datawarehouses.
BI architecture has emerged to meet those requirements, with data warehousing as the backbone of these processes. One of the BI architecture components is data warehousing. Each of that component has its own purpose that we will discuss in more detail while concentrating on data warehousing. Data integration.
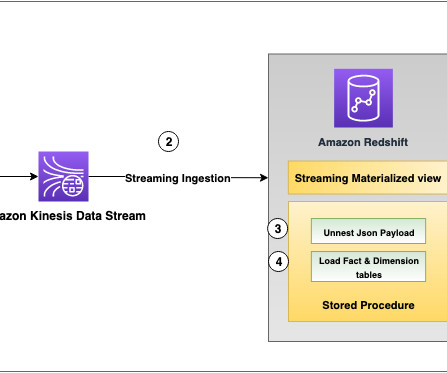
In addition to real-time analytics and visualization, the data needs to be shared for long-term data analytics and machine learning applications. From here, the metadata is published to Amazon DataZone by using AWS Glue Data Catalog. This process is shown in the following figure.
Cloud datawarehouses allow users to run analytic workloads with greater agility, better isolation and scale, and lower administrative overhead than ever before. The results demonstrate superior price performance of Cloudera DataWarehouse on the full set of 99 queries from the TPC-DS benchmark. Introduction.
Collaborate and build faster using familiar AWS tools for model development, generative AI, data processing, and SQL analytics with Amazon Q Developer , the most capable generative AI assistant for software development, helping you along the way. Having confidence in your data is key. The tools to transform your business are here.
Amazon Redshift Serverless makes it simple to run and scale analytics without having to manage your datawarehouse infrastructure. Tags allows you to assign metadata to your AWS resources. In Cost Explorer, you can visualize daily, monthly, and forecasted spend by combining an array of available filters.
These nodes can implement analytical platforms like data lake houses, datawarehouses, or data marts, all united by producing data products. The Institutional Data & AI platform adopts a federated approach to data while centralizing the metadata to facilitate simpler discovery and sharing of data products.
Amazon SageMaker Unified Studio brings together functionality and tools from the range of standalone studios, query editors, and visual tools available today in Amazon EMR , AWS Glue , Amazon Redshift , Amazon Bedrock , and the existing Amazon SageMaker Studio. With AWS Glue 5.0,
Data architect role Data architects are senior visionaries who translate business requirements into technology requirements and define data standards and principles, often in support of data or digital transformations. In some ways, the data architect is an advanced data engineer.
But although this might work for absorbing small data sources into a larger one, it soon becomes impractical. A better approach is to leave the data sources alone and bring summarized versions of each into a datawarehouse. This visual aspect is the key to the usefulness of any large and complex data landscape.
There are two primary reasons for this: Manual data discovery and manual data lineage. Money Loser #1: Manual Data Discovery. Metadata is at the heart of every report, dashboard, datawarehouse, visualization, and anything else the BI team produces. Money Loser #2: Manual Data Lineage.
There’s not much value in holding on to raw data without putting it to good use, yet as the cost of storage continues to decrease, organizations find it useful to collect raw data for additional processing. The raw data can be fed into a database or datawarehouse. It’s a good idea to record metadata.
Today’s customers have a growing need for a faster end to end data ingestion to meet the expected speed of insights and overall business demand. This ‘need for speed’ drives a rethink on building a more modern datawarehouse solution, one that balances speed with platform cost management, performance, and reliability.
QuickSight makes it straightforward for business users to visualizedata in interactive dashboards and reports. An AWS Glue crawler scans data on the S3 bucket and populates table metadata on the AWS Glue Data Catalog. Looking at the Skewness Job per Job visualization, there was spike on November 1, 2023.
We realized we needed a datawarehouse to cater to all of these consumer requirements, so we evaluated Amazon Redshift. At the same time, we had to find a way to implement entitlements in our Amazon Redshift datawarehouse with the same set of tags that we had already defined in Lake Formation.
Amazon Redshift is a fast, petabyte-scale, cloud datawarehouse that tens of thousands of customers rely on to power their analytics workloads. With its massively parallel processing (MPP) architecture and columnar data storage, Amazon Redshift delivers high price-performance for complex analytical queries against large datasets.
To address the issue of data quality, Amazon DataZone now integrates directly with AWS Glue Data Quality, allowing you to visualizedata quality scores for AWS Glue Data Catalog assets directly within the Amazon DataZone web portal. Amazon DataZone natively supports data sharing for Amazon Redshift data assets.
Organisations are looking at ways of simplifying data; for example, through simple rebranding efforts to disguise the complexity. However, SAP Datasphere goes much deeper deeper than a simple rebranding; it is the next generation of SAP DataWarehouse Cloud.
Business intelligence (BI) analysts transform data into insights that drive business value. This is done by mining complex data using BI software and tools , comparing data to competitors and industry trends, and creating visualizations that communicate findings to others in the organization.
BI software helps companies do just that by shepherding the right data into analytical reports and visualizations so that users can make informed decisions. To gain employee buy-in, Stout’s team builds BI dashboards to show them how they can easily connect to and interact with their data, as well as visualize it in a meaningful way.
In 2013, Amazon Web Services revolutionized the data warehousing industry by launching Amazon Redshift , the first fully-managed, petabyte-scale, enterprise-grade cloud datawarehouse. Amazon Redshift made it simple and cost-effective to efficiently analyze large volumes of data using existing business intelligence tools.
A data catalog benefits organizations in a myriad of ways. With the right data catalog tool, organizations can automate enterprise metadata management – including data cataloging, data mapping, data quality and code generation for faster time to value and greater accuracy for data movement and/or deployment projects.
Geolocation data is also stored, which will help map customer locations to latitudes and longitudes to better understand where these motors are located after being sold in a vehicle. ECC will use Cloudera Data Engineering (CDE) to address the above data challenges (see Fig. 2 ECC data enrichment pipeline.
With quality data at their disposal, organizations can form datawarehouses for the purposes of examining trends and establishing future-facing strategies. Industry-wide, the positive ROI on quality data is well understood. Business/Data Analyst: The business analyst is all about the “meat and potatoes” of the business.
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
This dynamic tool, powered by AWS and CARTO, provided robust visualizations of which regions and populations were interacting with our survey, enabling us to zoom in quickly and address gaps in coverage. Figure 1: Workflow illustrating data ingesting, transformation, and visualization using Redshift and CARTO.
Data in Place refers to the organized structuring and storage of data within a specific storage medium, be it a database, bucket store, files, or other storage platforms. In the contemporary data landscape, data teams commonly utilize datawarehouses or lakes to arrange their data into L1, L2, and L3 layers.
Understanding the benefits of data modeling is more important than ever. Data modeling is the process of creating a data model to communicate data requirements, documenting data structures and entity types. In this post: What Is a Data Model? Why Is Data Modeling Important? What Is a Data Model?
External data sharing gets strategic Data sharing between business partners is becoming far easier and much more cooperative, observes Mike Bechtel, chief futurist at business advisory firm Deloitte Consulting. The fabric, especially at the active metadata level, is important, Saibene notes.
While cloud-native, point-solution datawarehouse services may serve your immediate business needs, there are dangers to the corporation as a whole when you do your own IT this way. Cloudera DataWarehouse (CDW) is here to save the day! CDW is an integrated datawarehouse service within Cloudera Data Platform (CDP).
However, enterprise data generated from siloed sources combined with the lack of a data integration strategy creates challenges for provisioning the data for generative AI applications. Data discoverability Unlike structured data, which is managed in well-defined rows and columns, unstructured data is stored as objects.
Data engineers use Apache Iceberg because it’s fast, efficient, and reliable at any scale and keeps records of how datasets change over time. Apache Iceberg offers integrations with popular data processing frameworks such as Apache Spark, Apache Flink, Apache Hive, Presto, and more.
Amazon Redshift is a fully managed, scalable cloud datawarehouse that accelerates your time to insights with fast, easy, and secure analytics at scale. Tens of thousands of customers rely on Amazon Redshift to analyze exabytes of data and run complex analytical queries, making it the widely used cloud datawarehouse.
It seamlessly consolidates data from various data sources within AWS, including AWS Cost Explorer (and forecasting with Cost Explorer ), AWS Trusted Advisor , and AWS Compute Optimizer. They can use their own toolsets or rely on provided blueprints to ingest the data from source systems.
Well, that’s the problem – BI teams today tend to have to map out data lineage manually since they are usually dealing with multi-vendor environments. And if not impossible, then you can bet it’ll take the data analysts a LONG time to figure out. Data lineage visualization is an overview and a journey map of our data.
All this data arrives by the terabyte, and a data management platform can help marketers make sense of it all. Marketing-focused or not, DMPs excel at negotiating with a wide array of databases, data lakes, or datawarehouses, ingesting their streams of data and then cleaning, sorting, and unifying the information therein.
In fact, according in an IDC DataSphere study, IDC estimated that 10,628 exabytes (EB) of data was determined to be useful if analyzed, while only 5,063 exabytes (EB) of data (47.6%) was analyzed in 2022. New insights and relationships are found in this combination. All of this supports the use of AI.
You can’t do this easily without automated data lineage tools. Octopai’s metadata discovery and management suite provides visualization tools that empower you to see and report everything about sensitive customer data. Octopai's Automated Metadata Management Platform can make CCPA compliance a breeze.
Manajemen data: ETL (Extract, Transform, Load), pengelolaan data, management responsibility, metadata. Analisis big data: pembelajaran konsep data tidak terstruktur. Visualisasi data pada umumnya dihasilkan melalui dua jenis software: programing dan non-programing. DataWarehouse.
Finance teams often work with business intelligence (BI) tools to analyze data, identify trends, pinpoint discrepancies, and build informative, compelling reports for management. In addition, it can be very helpful to have a metadata layer in place that can help non-developers make sense of the information in the database.
As the first of its reasons why to migrate to Redshift , Amazon says, “Amazon Redshift is fully managed and simple to use, enabling you to deploy a new datawarehouse in minutes and load virtually any type of data from a range of cloud or on-premises data sources.”. Setting up the datawarehouse can take minutes.
This new native integration enhances our data lineage solution by providing seamless integration with one of the most powerful cloud-based datawarehouses, benefiting data teams and enabling support for a broader range of data lineage, discovery, and catalog.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content