This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
and zero-ETL support) as the source, and a Redshift datawarehouse as the target. The integration replicates data from the source database into the target datawarehouse. Additionally, you can choose the capacity, to limit the compute resources of the datawarehouse. For this post, set this to 8 RPUs.
About Redshift and some relevant features for the use case Amazon Redshift is a fully managed, petabyte-scale, massively parallel datawarehouse that offers simple operations and high performance. It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools.
With the launch of Amazon Redshift Serverless and the various provisioned instance deployment options , customers are looking for tools that help them determine the most optimal datawarehouse configuration to support their Amazon Redshift workloads. The following image shows the process flow.
Amazon Redshift is a popular cloud datawarehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
The extract, transform, and load (ETL) process has been a common pattern for moving data from an operational database to an analytics datawarehouse. ELT is where the extracted data is loaded as is into the target first and then transformed. ETL and ELT pipelines can be expensive to build and complex to manage.
It automatically provisions and intelligently scales datawarehouse compute capacity to deliver fast performance, and you pay only for what you use. Just load your data and start querying right away in the Amazon Redshift Query Editor or in your favorite business intelligence (BI) tool. Open the workgroup you want to monitor.
There are two broad approaches to analyzing operational data for these use cases: Analyze the data in-place in the operational database (e.g. With Aurora zero-ETL integration with Amazon Redshift, the integration replicates data from the source database into the target datawarehouse. or higher version) database.
Large-scale datawarehouse migration to the cloud is a complex and challenging endeavor that many organizations undertake to modernize their data infrastructure, enhance data management capabilities, and unlock new business opportunities. This makes sure the new data platform can meet current and future business goals.
Since Apache Iceberg is well supported by AWS data services and Cloudinary was already using Spark on Amazon EMR, they could integrate writing to Data Catalog and start an additional Spark cluster to handle data maintenance and compaction. A metadata or data file is considered orphan if it isn’t reachable by any valid snapshot.
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
Dafiti’s data infrastructure relies heavily on ETL and ELT processes, with approximately 2,500 unique processes run daily. Amazon Redshift at Dafiti Amazon Redshift is a fully managed datawarehouse service, and was adopted by Dafiti in 2017. TB of data. We started with 115 dc2.large
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud, providing up to five times better price-performance than any other cloud datawarehouse, with performance innovation out of the box at no additional cost to you. The following table summarizes these metrics.
Improved employee satisfaction: Providing business users access to data without having to contact analysts or IT can reduce friction, increase productivity, and facilitate faster results. The potential use cases for BI extend beyond the typical business performance metrics of improved sales and reduced costs.
Analysts can use SQL as a more powerful tool than Salesforce to model messy sales data. By applying complex logic, you can more seamlessly build data models and gain fast, more advanced analysis. To achieve this, first requires getting the data into a form that delivers insights. Daily snapshot of opportunities – a summary.
Amazon Redshift is a widely used, fully managed, petabyte-scale cloud datawarehouse. Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytics workloads. Take a snapshot of the source Redshift datawarehouse.
Can Amazon RDS for Db2 be used for running data warehousing workloads? Answer : Yes, Amazon RDS for Db2 can support analytics workloads, but it is not a datawarehouse. Amazon RDS At what level are snapshot-based backups taken? Also, you can take manual snapshots as needed.
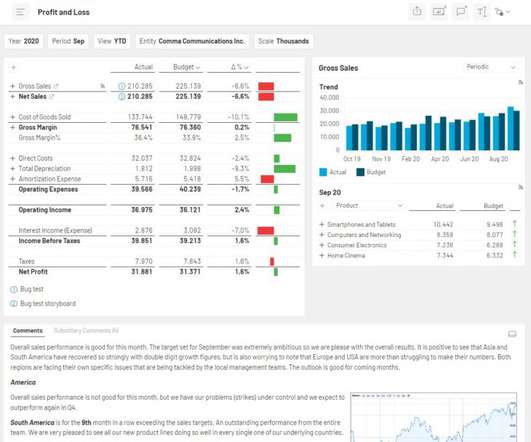
Dashboard reporting refers to putting the relevant business metrics and KPIs in one interface, presenting them visually, dynamic, and in real-time, in the dashboard formats. With the advent of modern dashboard reporting tools, you can conveniently visualize your data into dashboards and reports and extract insightful information from it.
It contains references to data that is used as sources and targets in AWS Glue ETL (extract, transform, and load) jobs, and stores information about the location, schema, and runtime metrics of your data. The Data Catalog organizes this information in the form of metadata tables and databases.
Stream processing, however, can enable the chatbot to access real-time data and adapt to changes in availability and price, providing the best guidance to the customer and enhancing the customer experience. When the model finds an anomaly or abnormal metric value, it should immediately produce an alert and notify the operator.
Take a snapshot of your customer database for the past 2 years and it may look like this: That is an average. For some of your campaigns this data might not be easily available in your web analytics tool (it is also quite likely you are doing all of this analysis in Excel). Optimizing acquisition channels with LTV. Look 'em up.
The destination can be an event-driven application for real-time dashboards, automatic decisions based on processed streaming data, real-time altering, and more. It can receive the events from an input Kinesis data stream and route the resulting stream to an output data stream.
Because DE is fully integrated with the Cloudera Shared Data Experience (SDX), every stakeholder across your business gains end-to-end operational visibility, with comprehensive security and governance throughout. For starters it lacks metrics around cpu, memory utilization that are easily correlated across the lifetime of the job.
For example, P&C insurance strives to understand its customers and households better through data, to provide better customer service and anticipate insurance needs, as well as accurately measure risks. Life insurance needs accurate data on consumer health, age and other metrics of risk.
Amazon Redshift is a fully managed and petabyte-scale cloud datawarehouse that is used by tens of thousands of customers to process exabytes of data every day to power their analytics workload. You can structure your data, measure business processes, and get valuable insights quickly can be done by using a dimensional model.
Performance metrics appear in charts and graphs. . In this blog, we walk through the Impala workloads analysis in iEDH, Cloudera’s own Enterprise DataWarehouse (EDW) implementation on CDH clusters. We compare the current run of a job to a baseline derived from performance metrics. Data Engineering jobs (optional).
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a data lake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale. Clustering data for better data colocation using z-ordering.
The Analytics specialty practice of AWS Professional Services (AWS ProServe) helps customers across the globe with modern data architecture implementations on the AWS Cloud. Table data storage mode – There are two options: Historical – This table in the data lake stores historical updates to records (always append).
Enterprise Performance Management (EPM) gives C-level executives and others throughout your organization a vivid, up-to-the-minute picture of key business metrics. Decision makers regularly have to wait for performance metrics that they should track on a daily basis. EPM reporting templates offer the perfect solution.
With CDSW, organizations can research and experiment faster, deploy models easily and with confidence, as well as rely on the wider Cloudera platform to reduce the risks and costs of data science projects. track model metrics, performance, and any model artifacts the user specifies. let the user document, test, and share the model.
With fast and fine-grained scaling in EMR Serverless, if a pipeline runs daily and needs to process 1 GB of data one day and 100 GB of data another day, EMR Serverless automatically scales to handle that load. Monitoring – EMR Serverless sends metrics to Amazon CloudWatch at the application and job level every 1 minute.
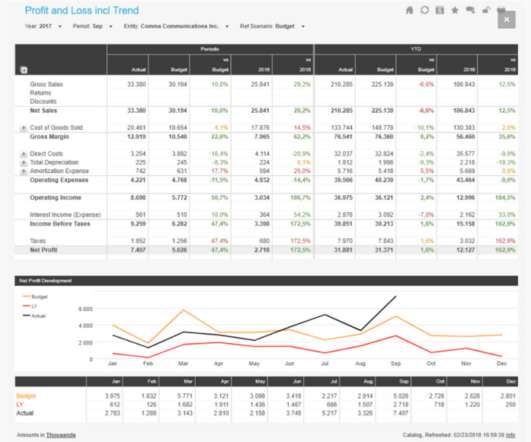
Financial Performance Dashboard The financial performance dashboard provides a comprehensive overview of key metrics related to your balance sheet, shedding light on the efficiency of your capital expenditure. While sales dashboards focus on future prospects, accounting primarily focuses on analyzing the same metrics retrospectively.
We chose DynamoDB as our metadata store, which provides the latest details to the consumers to query the data effectively. Every dataset in our system is uniquely identified by snapshot ID, which we can search from our metadata store. Clients access this data store with an API’s.
It has been well published since the State of DevOps 2019 DORA Metrics were published that with DevOps, companies can deploy software 208 times more often and 106 times faster, recover from incidents 2,604 times faster, and release 7 times fewer defects. Ricardo Serafim is a Senior AWS Data Lab Solutions Architect.
Amazon Redshift is a fully managed, petabyte scale cloud datawarehouse that enables you to analyze large datasets using standard SQL. Datawarehouse workloads are increasingly being used with mission-critical analytics applications that require the highest levels of resilience and availability.
Organizations across all industries have complex data processing requirements for their analytical use cases across different analytics systems, such as data lakes on AWS , datawarehouses ( Amazon Redshift ), search ( Amazon OpenSearch Service ), NoSQL ( Amazon DynamoDB ), machine learning ( Amazon SageMaker ), and more.
dbt is an open source, SQL-first templating engine that allows you to write repeatable and extensible data transforms in Python and SQL. dbt is predominantly used by datawarehouses (such as Amazon Redshift ) customers who are looking to keep their data transform logic separate from storage and engine.
They set up a couple of clusters and began processing queries at a much faster speed than anything they had experienced with Apache Hive, a distributed datawarehouse system, on their data lake. For traditional analytics, they are bringing data discipline to their use of Presto. It lands as raw data in HDFS.
BI leverages and synthesizes data from analytics, data mining, and visualization tools to deliver quick snapshots of business health to key stakeholders, and empower those people to make better choices. Why does the business want to leverage data intelligence? The business is migrating data to a cloud-datawarehouse.
Enterprise Performance Management (EPM) provides users throughout your company with vivid, up-to-the-minute details about the key metrics that drive your organization’s success. This creates an opportunity-cost when decision makers have to wait for the reports they’ll be using to track performance metrics.
All of that in-between work–the export, the consolidation, and the cleanup–means that analysts are stuck using a snapshot of the data. Executives need to know how the organization is performing relative to key metrics, and how certain external factors may impact revenue product demand, profitability, supply chain performance, and more.
You’ll learn how leading finance teams apply technology to the task of producing fast, accurate reports, eliminating tedious manual effort, giving managers visibility to real-time organizational metrics, and instilling confidence in stakeholders throughout the company. Challenge 1. ERP Complexity.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content