This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction Do you think you can derive insights from raw data? Wouldn’t the process be much easier if the raw data were more organized and clean? Here’s when Data […]. The post What are Schemas in DataWarehouseModeling?
This article was published as a part of the Data Science Blogathon. Introduction Hello, data-enthusiast! In this article let’s discuss “DataModelling” right from the traditional and classical ways and aligning to today’s digital way, especially for analytics and advanced analytics.
This article was published as a part of the Data Science Blogathon. The post How a Delta Lake is Process with Azure Synapse Analytics appeared first on Analytics Vidhya.
Unifying these necessitates additional data processing, requiring each business unit to provision and maintain a separate datawarehouse. This burdens business units focused solely on consuming the curated data for analysis and not concerned with data management tasks, cleansing, or comprehensive data processing.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud datawarehouses.
Cloud datawarehouses allow users to run analytic workloads with greater agility, better isolation and scale, and lower administrative overhead than ever before. The results demonstrate superior price performance of Cloudera DataWarehouse on the full set of 99 queries from the TPC-DS benchmark. Introduction.
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. Data store – The data store used a custom datamodel that had been highly optimized to meet low-latency query response requirements.
Each data source is updated on its own schedule, for example, daily, weekly or monthly. The DataKitchen Platform ingests data into a data lake and runs Recipes to create a datawarehouse leveraged by users and self-service data analysts. The third set of domains are cached data sets (e.g.,
This article was published as a part of the Data Science Blogathon A data scientist’s ability to extract value from data is closely related to how well-developed a company’s data storage and processing infrastructure is.
They’re taking data they’ve historically used for analytics or business reporting and putting it to work in machine learning (ML) models and AI-powered applications. Amazon SageMaker Unified Studio (Preview) solves this challenge by providing an integrated authoring experience to use all your data and tools for analytics and AI.
Plug-and-play integration : A seamless, plug-and-play integration between data producers and consumers should facilitate rapid use of new data sets and enable quick proof of concepts, such as in the data science teams. From here, the metadata is published to Amazon DataZone by using AWS Glue Data Catalog.
This book is not available until January 2022, but considering all the hype around the data mesh, we expect it to be a best seller. In the book, author Zhamak Dehghani reveals that, despite the time, money, and effort poured into them, datawarehouses and data lakes fail when applied at the scale and speed of today’s organizations.
Some of these ‘structures’ may include putting all the information; for instance, a structure could be about cars, placing them into tables that consist of makes, models, year of manufacture, and color. With a MySQL dashboard builder , for example, you can connect all the data with a few clicks.
Users discuss how they are putting erwin’s datamodeling, enterprise architecture, business process modeling, and data intelligences solutions to work. IT Central Station members using erwin solutions are realizing the benefits of enterprise modeling and data intelligence. This is live and dynamic.”.
These strategies, such as investing in AI-powered cleansing tools and adopting federated governance models, not only address the current data quality challenges but also pave the way for improved decision-making, operational efficiency and customer satisfaction. When financial data is inconsistent, reporting becomes unreliable.
This evaluation, we feel, critically examines vendors capabilities to address key service needs, including data engineering, operational data integration, modern data architecture delivery, and enabling less-technical data integration across various deployment models. This graphic was published by Gartner, Inc.
Designing databases for datawarehouses or data marts is intrinsically much different than designing for traditional OLTP systems. Accordingly, datamodelers must embrace some new tricks when designing datawarehouses and data marts. Figure 1: Pricing for a 4 TB datawarehouse in AWS.
Enterprise datawarehouse platform owners face a number of common challenges. In this article, we look at seven challenges, explore the impacts to platform and business owners and highlight how a modern datawarehouse can address them. ETL jobs and staging of data often often require large amounts of resources.
In this regard, the enterprise data product catalog acts as a federated portal, facilitating cross-domain access and interoperability while maintaining alignment with governance principles. This model balances node or domain-level autonomy with enterprise-level oversight, creating a scalable and consistent framework across ANZ.
Today’s customers have a growing need for a faster end to end data ingestion to meet the expected speed of insights and overall business demand. This ‘need for speed’ drives a rethink on building a more modern datawarehouse solution, one that balances speed with platform cost management, performance, and reliability.
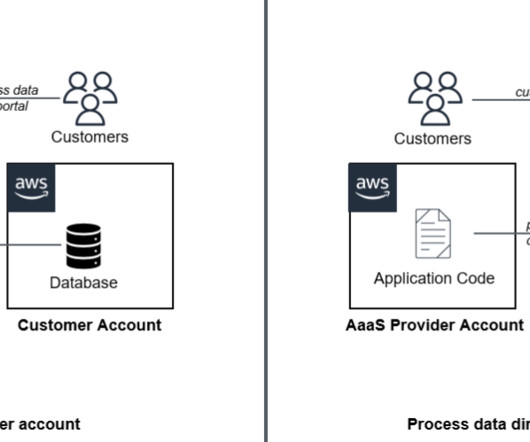
Analytics as a service (AaaS) is a business model that uses the cloud to deliver analytic capabilities on a subscription basis. This model provides organizations with a cost-effective, scalable, and flexible solution for building analytics. times better price-performance than other cloud datawarehouses.
Amazon Redshift is the most widely used datawarehouse in the cloud, best suited for analyzing exabytes of data and running complex analytical queries. Amazon QuickSight is a fast business analytics service to build visualizations, perform ad hoc analysis, and quickly get business insights from your data.
In this example, the Machine Learning (ML) model struggles to differentiate between a chihuahua and a muffin. Will the model correctly determine it is a muffin or get confused and think it is a chihuahua? The extent to which we can predict how the model will classify an image given a change input (e.g. Model Visibility.
Amazon Redshift is a fully managed and petabyte-scale cloud datawarehouse that is used by tens of thousands of customers to process exabytes of data every day to power their analytics workload. You can structure your data, measure business processes, and get valuable insights quickly can be done by using a dimensional model.
Macmillan Publishers is a global publishing company and one of the “Big Five” English language publishers. They published many perennial favorites including Kristin Hannah’s The Nightingale , Bill Martin’s Brown Bear, Brown Bear, what do you see?
Arming data science teams with the access and capabilities needed to establish a two-way flow of information is one critical challenge many organizations face when it comes to unlocking value from their modeling efforts. Domino integrates with Snowflake to solve this challenge by providing a modern approach to data.
How could Matthew serve all this data, together , in an easily consumable way, without losing focus on his core business: finding a cure for cancer. The Vision of a Discovery DataWarehouse. A Discovery DataWarehouse is cloud-agnostic. Access to valuable data should not be hindered by the technology.
dbt is an open source, SQL-first templating engine that allows you to write repeatable and extensible data transforms in Python and SQL. dbt is predominantly used by datawarehouses (such as Amazon Redshift ) customers who are looking to keep their data transform logic separate from storage and engine.
The answer is that generative AI leverages recent advances in foundation models. Unlike traditional ML, where each new use case requires a new model to be designed and built using specific data, foundation models are trained on large amounts of unlabeled data, which can then be adapted to new scenarios and business applications.
In-WarehouseData Prep provides builders with the advanced functionality they need to rapidly transform and optimize raw data creating materialized views on cloud datawarehouses. In-WarehouseData Prep supports both AWS Redshift and Snowflake datawarehouses. Additional capabilities.
After having rebuilt their datawarehouse, I decided to take a little bit more of a pointed role, and I joined Oracle as a database performance engineer. I spent eight years in the real-world performance group where I specialized in high visibility and high impact data warehousing competes and benchmarks. you name it.
Large-scale datawarehouse migration to the cloud is a complex and challenging endeavor that many organizations undertake to modernize their data infrastructure, enhance data management capabilities, and unlock new business opportunities. This makes sure the new data platform can meet current and future business goals.
Diagram 1: Overall architecture of the solution, using AWS Step Functions, Amazon Redshift and Amazon S3 The following AWS services were used to shape our new ETL architecture: Amazon Redshift A fully managed, petabyte-scale datawarehouse service in the cloud. The following Diagram 4 shows this workflow.
Amazon SageMaker Lakehouse provides an open data architecture that reduces data silos and unifies data across Amazon Simple Storage Service (Amazon S3) data lakes, Redshift datawarehouses, and third-party and federated data sources. With AWS Glue 5.0, AWS Glue 5.0 Finally, AWS Glue 5.0
There are two broad approaches to analyzing operational data for these use cases: Analyze the data in-place in the operational database (e.g. With Aurora zero-ETL integration with Amazon Redshift, the integration replicates data from the source database into the target datawarehouse.
Cloudera users can securely connect Rill to a source of event stream data, such as Cloudera DataFlow , modeldata into Rill’s cloud-based Druid service, and share live operational dashboards within minutes via Rill’s interactive metrics dashboard or any connected BI solution. Cloudera DataWarehouse). Apache Hive.
Data Mining Techniques and Data Visualization. Data Mining is an important research process. It hosts a data analysis competition. There are many open datasets that you can analyze and publish your results. Practical experience. Here are some good options for doing this. Use Kaggle. Qualification confirmation.
The extract, transform, and load (ETL) process has been a common pattern for moving data from an operational database to an analytics datawarehouse. ELT is where the extracted data is loaded as is into the target first and then transformed. ETL and ELT pipelines can be expensive to build and complex to manage.
An Amazon DataZone domain contains an associated business data catalog for search and discovery, a set of metadata definitions to decorate the data assets that are used for discovery purposes, and data projects with integrated analytics and ML tools for users and groups to consume and publishdata assets.
An integrated solution provides single sign-on access to data sources and datawarehouses.’. The integrated augmented analytics approach includes simple tenant management to deploy with a shared datamodel for single-tenant mode or an isolated datamodel for multi-tenant mode and software as a service (SaaS) applications.
Rokita believes the key to making that transition is to stop thinking of data warehousing and AI/ML as separate departments with their own distinct systems. The datawarehouse is about past data, and models are about future data.
As we have already said, the challenge for companies is to extract value from data, and to do so it is necessary to have the best visualization tools. Over time, it is true that artificial intelligence and deep learning models will be help process these massive amounts of data (in fact, this is already being done in some fields).
They enable transactions on top of data lakes and can simplify data storage, management, ingestion, and processing. These transactional data lakes combine features from both the data lake and the datawarehouse. Dimension-based models have been used extensively to build datawarehouses.
One of the key challenges in modern big data management is facilitating efficient data sharing and access control across multiple EMR clusters. Organizations have multiple Hive datawarehouses across EMR clusters, where the metadata gets generated. Test access using SageMaker Studio in the consumer account. Choose Grant.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content