This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As adoption has grown, some enterprises found that the theoretical advantages of data processing in the cloud can be more challenging to deliver in practice, with constant monitoring and manual intervention required to optimize resources and realize potential savings.
BladeBridge offers a comprehensive suite of tools that automate much of the complex conversion work, allowing organizations to quickly and reliably transition their data analytics capabilities to the scalable Amazon Redshift datawarehouse. times better price performance than other cloud datawarehouses.
This is both frustrating for companies that would prefer making ML an ordinary, fuss-free value-generating function like software engineering, as well as exciting for vendors who see the opportunity to create buzz around a new category of enterprise software. All ML projects are software projects.
Amazon Redshift is a fast, fully managed cloud datawarehouse that makes it cost-effective to analyze your data using standard SQL and business intelligence tools. One such optimization for reducing query runtime is to precompute query results in the form of a materialized view. Enrico holds a M.Sc.
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. Data store – The data store used a custom data model that had been highly optimized to meet low-latency query response requirements.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. or a later version) database.
The current scaling approach of Amazon Redshift Serverless increases your compute capacity based on the query queue time and scales down when the queuing reduces on the datawarehouse. In this post, we describe how Redshift Serverless utilizes the new AI-driven scaling and optimization capabilities to address common use cases.
Beyond breaking down silos, modern data architectures need to provide interfaces that make it easy for users to consume data using tools fit for their jobs. Data must be able to freely move to and from datawarehouses, data lakes, and data marts, and interfaces must make it easy for users to consume that data.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze your data using standard SQL and your existing business intelligence (BI) tools. Data ingestion is the process of getting data to Amazon Redshift.
Amazon Redshift is a fully managed, AI-powered cloud datawarehouse that delivers the best price-performance for your analytics workloads at any scale. Refer to Easy analytics and cost-optimization with Amazon Redshift Serverless to get started. For this post, we use Redshift Serverless. Choose Run all on each notebook tab.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that you can use to analyze your data at scale. Maintaining reusable database sessions to help optimize the use of database connections, preventing the API server from exhausting the available connections and improving overall system scalability.
RightData – A self-service suite of applications that help you achieve Data Quality Assurance, Data Integrity Audit and Continuous Data Quality Control with automated validation and reconciliation capabilities. QuerySurge – Continuously detect data issues in your delivery pipelines. Data breaks. Azure DevOps.
Plus, knowing the best way to learn SQL is beneficial even for those who don’t deal directly with a database: Business Intelligence software , such as datapine, offers intuitive drag-and-drop interfaces, allowing for superior data querying without any SQL knowledge. 18) “The DataWarehouse Toolkit” By Ralph Kimball and Margy Ross.
Important considerations for preview As you begin using automated Spark upgrades during the preview period, there are several important aspects to consider for optimal usage of the service: Service scope and limitations – The preview release focuses on PySpark code upgrades from AWS Glue versions 2.0 to version 4.0.
Although organizations spend millions of dollars on collecting and analyzing data with various data analysis tools , it seems like most people have trouble actually using that data in actionable, profitable ways. Your Chance: Want to perform advanced data analysis with a few clicks? 3) Where will your data come from?
In this post, we show you how to establish the data ingestion pipeline between Google Analytics 4, Google Sheets, and an Amazon Redshift Serverless workgroup. It also helps you securely access your data in operational databases, data lakes, or third-party datasets with minimal movement or copying of data.
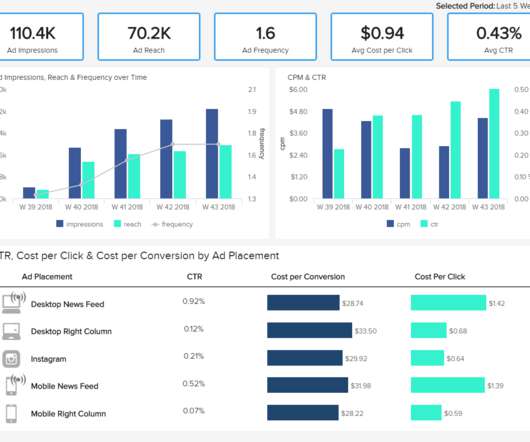
Likes, comments, shares, reach, CTR, conversions – all have become extremely significant to optimize and manage regularly in order to grow in our competitive digital environment. You need to know how the audience responds, whether you need further adjustments, and how to gather accurate, real-time data. We offer a 14-day trial.
1) Benefits Of Business Intelligence Software. a) Data Connectors Features. For a few years now, Business Intelligence (BI) has helped companies to collect, analyze, monitor, and present their data in an efficient way to extract actionable insights that will ensure sustainable growth. Benefits Of Business Intelligence Software.
Complex queries, on the other hand, refer to large-scale data processing and in-depth analysis based on petabyte-level datawarehouses in massive data scenarios. AWS Glue crawler crawls data lake information from Amazon S3, generating a Data Catalog to support dbt on Amazon Athena data modeling.
Aruba offers networking hardware like access points, switches, routers, software, security devices, and Internet of Things (IoT) products. The data sources include 150+ files including 10-15 mandatory files per region ingested in various formats like xlxs, csv, and dat. The following diagram illustrates the solution architecture.
In today’s world, datawarehouses are a critical component of any organization’s technology ecosystem. The rise of cloud has allowed datawarehouses to provide new capabilities such as cost-effective data storage at petabyte scale, highly scalable compute and storage, pay-as-you-go pricing and fully managed service delivery.
times better price-performance than other cloud datawarehouses on real-world workloads using advanced techniques like concurrency scaling to support hundreds of concurrent users, enhanced string encoding for faster query performance, and Amazon Redshift Serverless performance enhancements. Amazon Redshift delivers up to 4.9
In 2013, Amazon Web Services revolutionized the data warehousing industry by launching Amazon Redshift , the first fully-managed, petabyte-scale, enterprise-grade cloud datawarehouse. Amazon Redshift made it simple and cost-effective to efficiently analyze large volumes of data using existing business intelligence tools.
In this post, we look at three key challenges that customers face with growing data and how a modern datawarehouse and analytics system like Amazon Redshift can meet these challenges across industries and segments. This performance innovation allows Nasdaq to have a multi-use data lake between teams.
To do so, Presto and Spark need to readily work with existing and modern datawarehouse infrastructures. Now, let’s chat about why datawarehouseoptimization is a key value of a data lakehouse strategy. The rise of cloud object storage has driven the cost of data storage down.
A DSS leverages a combination of raw data, documents, personal knowledge, and/or business models to help users make decisions. The data sources used by a DSS could include relational data sources, cubes, datawarehouses, electronic health records (EHRs), revenue projections, sales projections, and more.
Try our professional reporting software for 14 days, completely free! Ad hoc reporting, also known as one-time ad hoc reports, helps its users to answer critical business questions immediately by creating an autonomous report, without the need to wait for standard analysis with the help of real-time data and dynamic dashboards.
Until then though, they don’t necessarily want to spend the time and resources necessary to create a schema to house this data in a traditional datawarehouse. Instead, businesses are increasingly turning to data lakes to store massive amounts of unstructured data. The rise of datawarehouses and data lakes.
Snowflake provides the right balance between the cloud and data warehousing, especially when datawarehouses like Teradata and Oracle are becoming too expensive for their users. It is also easy to get started with Snowflake as the typical complexity of datawarehouses like Teradata and Oracle are hidden from the users. .
Armed with BI-based prowess, these organizations are a testament to the benefits of using online data analysis to enhance your organization’s processes and strategies. These past BI issues may discourage them to adopt enterprise-wide BI software. SMEs are discouraged by the prohibitive costs of acquiring the right software.
But the data repository options that have been around for a while tend to fall short in their ability to serve as the foundation for big data analytics powered by AI. Traditional datawarehouses, for example, support datasets from multiple sources but require a consistent data structure.
Data visualization is a concept that describes any effort to help people understand the significance of data by placing it in a visual context. Patterns, trends and correlations that may go unnoticed in text-based data can be more easily exposed and recognized with data visualization software.
In this day and age, we’re all constantly hearing the terms “big data”, “data scientist”, and “in-memory analytics” being thrown around. Almost all the major software companies are continuously making use of the leading Business Intelligence (BI) and Data discovery tools available in the market to take their brand forward.
Among the many reasons that a majority of large enterprises have adopted Cloudera DataWarehouse as their modern analytic platform of choice is the incredible ecosystem of partners that have emerged over recent years. We are tracking very interesting development in areas like security, catalogs, data masking and more.
Trade quality and optimization – In order to monitor and optimize trade quality, you need to continually evaluate market characteristics such as volume, direction, market depth, fill rate, and other benchmarks related to the completion of trades. This will be your OLTP data store for transactional data. version cluster.
So Seriously … You Should Automate Your Data Vault. Data Vault is a methodology for architecting and managing datawarehouses in complex data environments where new data types and structures are constantly introduced. By Danny Sandwell.
Amazon Redshift , the most widely used cloud datawarehouse, has evolved significantly to meet the performance requirements of the most demanding workloads. This post covers one such new feature—the multidimensional data layout sort key. Refer to Working with automatic table optimization for more details on ATO.
The external data catalog can be AWS Glue Data Catalog, the data catalog that comes with Amazon Athena, or your own Apache Hive metastore. To get the best performance on data lake queries with Redshift, you can use AWS Glue Data Catalog’s column statistics feature to collect statistics on Data Lake tables.
Amazon Redshift Serverless is a fully managed, scalable cloud datawarehouse that accelerates your time to insights with fast, simple, and secure analytics at scale. Amazon Redshift data sharing allows you to share data within and across organizations, AWS Regions, and even third-party providers, without moving or copying the data.
Why worry about costs with cloud-native data warehousing? Have you been burned by the unexpected costs of a cloud datawarehouse? If not, before adopting a cloud datawarehouse, consider the true costs of a cloud-native datawarehouse. These costs impede the adoption of cloud-native datawarehouses.
Solutions data architect: These individuals design and implement data solutions for specific business needs, including datawarehouses, data marts, and data lakes. Application data architect: The application data architect designs and implements data models for specific software applications.
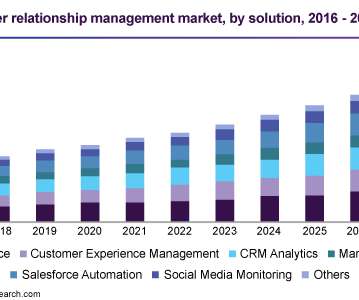
Therefore, CRM software comes into the picture to help enterprises achieve their business targets. These software tools rely on sophisticated big data algorithms and allow companies to boost their sales, business productivity and customer retention. This tool will help you to sync and store data from multiple sources quickly.
Diagram 1: Overall architecture of the solution, using AWS Step Functions, Amazon Redshift and Amazon S3 The following AWS services were used to shape our new ETL architecture: Amazon Redshift A fully managed, petabyte-scale datawarehouse service in the cloud. Our infrastructure was defined as code using the AWS CDK.
In-WarehouseData Prep provides builders with the advanced functionality they need to rapidly transform and optimize raw data creating materialized views on cloud datawarehouses. In-WarehouseData Prep supports both AWS Redshift and Snowflake datawarehouses. Sisense AI Trends.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content