This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction The following is an in-depth article explaining what data warehousing is as well as its types, characteristics, benefits, and disadvantages. What is a datawarehouse? A few of the topics which we will cover in the article are: 1.
This article was published as a part of the Data Science Blogathon. Introduction Organizations are turning to cloud-based technology for efficient data collecting, reporting, and analysis in today’s fast-changing business environment. Data and analytics have become critical for firms to remain competitive.
This article was published as a part of the Data Science Blogathon. Introduction The purpose of a datawarehouse is to combine multiple sources to generate different insights that help companies make better decisions and forecasting. It consists of historical and commutative data from single or multiple sources.
This article was published as a part of the Data Science Blogathon. Introduction Do you think you can derive insights from raw data? Wouldn’t the process be much easier if the raw data were more organized and clean? Here’s when Data […]. The post What are Schemas in DataWarehouse Modeling?
This article was published as a part of the Data Science Blogathon. Introduction Data from different sources are brought to a single location and then converted into a format that the datawarehouse can process and store. A boss may […]. A boss may […].
This article was published as a part of the Data Science Blogathon. Introduction Data is defined as information that has been organized in a meaningful way. Data collection is critical for businesses to make informed decisions, understand customers’ […]. The post Data Lake or DataWarehouse- Which is Better?
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Datawarehouse generalizes and mingles data in multidimensional space. The post How to Build a DataWarehouse Using PostgreSQL in Python? appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction The concept of data warehousing dates to the 1980s. DHW, short for DataWarehouse, was presented first by great IBM researchers Barry Devlin and Paul […]. The post DataWarehouse for the Beginners!
This article was published as a part of the Data Science Blogathon. Introduction on Snowflake Architecture This article helps to focus on an in-depth understanding of Snowflake architecture, how it stores and manages data, as well as its conceptual fragmentation concepts.
This article was published as a part of the Data Science Blogathon. Introduction to DataWarehouse In today’s data-driven age, a large amount of data gets generated daily from various sources such as emails, e-commerce websites, healthcare, supply chain and logistics, transaction processing systems, etc.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction A DataWarehouse is Built by combining data from multiple. The post A Brief Introduction to the Concept of DataWarehouse appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Different components in the Hadoop Framework Introduction Hadoop is. The post HIVE – A DATAWAREHOUSE IN HADOOP FRAMEWORK appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction on DataWarehouses During one of the technical webinars, it was highlighted where the transactional database was rendered no-operational bringing day to day operations to a standstill.
This article was published as a part of the Data Science Blogathon. Introduction to DataWarehouse SQL DataWarehouse is also a cloud-based datawarehouse that uses Massively Parallel Processing (MPP) to run complex queries across petabytes of data rapidly. Import big […].
This article was published as a part of the Data Science Blogathon. Introduction Amazon’s Redshift Database is a cloud-based large data warehousing solution. Companies may store petabytes of data in easy-to-access “clusters” that can be searched in parallel using the platform’s storage system.
This article was published as a part of the Data Science Blogathon. Introduction Hello, data-enthusiast! In this article let’s discuss “Data Modelling” right from the traditional and classical ways and aligning to today’s digital way, especially for analytics and advanced analytics.
This article was published as a part of the Data Science Blogathon. Introduction Have you ever wondered how big IT giants store and process huge amounts of data? storing the data […]. storing the data […].
This article was published as a part of the Data Science Blogathon. The post How a Delta Lake is Process with Azure Synapse Analytics appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction Big Query is a serverless enterprise datawarehouse service fully managed by Google. Big Query provides nearly real-time analytics of massive data.
This article was published as a part of the Data Science Blogathon. Businesses have adopted Snowflake as migration from on-premise enterprise datawarehouses (such as Teradata) or a more flexibly scalable and easier-to-manage alternative to […].
This article was published as a part of the Data Science Blogathon. Introduction Source – pexels.com Are you struggling to manage and analyze large amounts of data? Are you looking for a cost-effective and scalable solution for your datawarehouse needs? Look no further than AWS Redshift.
This article was published as a part of the Data Science Blogathon Introduction Google’s BigQuery is an enterprise-grade cloud-native datawarehouse. Since its inception, BigQuery has evolved into a more economical and fully managed datawarehouse that can run lightning-fast […].
This article was published as a part of the Data Science Blogathon. Introduction on ETL Pipeline ETL pipelines are a set of processes used to transfer data from one or more sources to a database, like a datawarehouse.
This article was published as a part of the Data Science Blogathon What is the need for Hive? The official description of Hive is- ‘Apache Hive datawarehouse software project built on top of Apache Hadoop for providing data query and analysis.
This article was published as a part of the Data Science Blogathon. Introduction Apache Hive is a datawarehouse system built on top of Hadoop which gives the user the flexibility to write complex MapReduce programs in form of SQL- like queries.
This article was published as a part of the Data Science Blogathon. Introduction Organizations with a separate transactional database and datawarehouse typically have many data engineering activities. For example, they extract, transform and load data from various sources into their datawarehouse.
This article was published as a part of the Data Science Blogathon Image 1 What is data mining? Data mining is the process of finding interesting patterns and knowledge from large amounts of data. This analysis […].
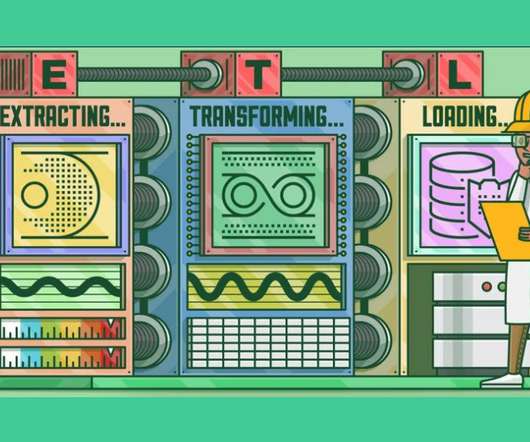
This article was published as a part of the Data Science Blogathon What is ETL? ETL is a process that extracts data from multiple source systems, changes it (through calculations, concatenations, and so on), and then puts it into the DataWarehouse system. ETL stands for Extract, Transform, and Load.
This article was published as a part of the Data Science Blogathon. Introduction Hive is a popular datawarehouse built on top of Hadoop that is used by companies like Walmart, Tiktok, and AT&T. It is an important technology for data engineers to learn and master.
This article was published as a part of the Data Science Blogathon. Introduction Apache SQOOP is a tool designed to aid in the large-scale export and import of data into HDFS from structured data repositories. Relational databases, enterprise datawarehouses, and NoSQL systems are all examples of data storage.
Unifying these necessitates additional data processing, requiring each business unit to provision and maintain a separate datawarehouse. This burdens business units focused solely on consuming the curated data for analysis and not concerned with data management tasks, cleansing, or comprehensive data processing.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Amazon Redshift is a datawarehouse service in the cloud. The post Understand All About Amazon Redshift! appeared first on Analytics Vidhya.
Did you know Cloudera customers, such as SMG and Geisinger , offloaded their legacy DW environment to Cloudera DataWarehouse (CDW) to take advantage of CDW’s modern architecture and best-in-class performance? The DataWarehouse on Cloudera Data Platform provides easy to use self-service and advanced analytics use cases at scale.
This article was published as a part of the Data Science Blogathon. Source: [link] Introduction If you are familiar with databases, or datawarehouses, you have probably heard the term “ETL.” As the amount of data at organizations grow, making use of that data in analytics to derive business insights grows as well.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud datawarehouses.
This article was published as a part of the Data Science Blogathon. Introduction Regarding data analytics, getting insights from a data mart instead of a datawarehouse or external data sources can save companies time and produce more targeted results. The idea of ??data
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. Data ingestion – Pentaho was used to ingest data sourced from multiple datapublishers into the data store.
Cloud datawarehouses allow users to run analytic workloads with greater agility, better isolation and scale, and lower administrative overhead than ever before. The results demonstrate superior price performance of Cloudera DataWarehouse on the full set of 99 queries from the TPC-DS benchmark. Introduction.
One of our key datawarehouse refreshes had failed. No new data. The refresh was long past its deadline, the projects key data engineer was on vacation, and I was playing backup. And they caught a major problem: the new records we received from one source were completely out of sync with our other data.
Introduction Publish and Subscribe is a messaging mechanism having one or a set of senders sending messages and one or a group of receivers receiving these messages. Publishers can publish […] The post Complete Guide to Pub/Sub in Redis appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction More often than not, developers run into issues of an application running on one machine versus not running on another. Dockers help prevent this by ensuring the application runs on any machine if it works on yours. Simply put, if your job as […].
This article was published as a part of the Data Science Blogathon. Introduction A key aspect of big data is data frames. However, Spark is more suited to handling scaled distributed data, whereas Pandas is not. Pandas and Spark are two of the most popular types. What […].
This article was published as a part of the Data Science Blogathon Introduction Data Science is a team sport, we have members adding value across the analytics/data science lifecycle so that it can drive the transformation by solving challenging business problems.
This article was published as a part of the Data Science Blogathon. Introduction Processing large amounts of raw data from various sources requires appropriate tools and solutions for effective data integration. Building an ETL pipeline using Apache […].
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content