This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Now with Amazon Bedrock Knowledge Bases integration with structured data, you can use simple, natural language prompts to query complex financial datasets. From customer portals to internal dashboards and mobile apps, this API-driven approach makes enterprise-grade data analysis accessible to everyone in your organization.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud datawarehouses.
BladeBridge offers a comprehensive suite of tools that automate much of the complex conversion work, allowing organizations to quickly and reliably transition their data analytics capabilities to the scalable Amazon Redshift datawarehouse. times better price performance than other cloud datawarehouses.
Data lakes and datawarehouses are two of the most important data storage and management technologies in a modern data architecture. Data lakes store all of an organization’s data, regardless of its format or structure. Delta Lake doesn’t have a specific concept for incremental queries.
Unifying these necessitates additional data processing, requiring each business unit to provision and maintain a separate datawarehouse. This burdens business units focused solely on consuming the curated data for analysis and not concerned with data management tasks, cleansing, or comprehensive data processing.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze your data using standard SQL and your existing business intelligence (BI) tools. Data ingestion is the process of getting data to Amazon Redshift.
Amazon Redshift is a fully managed, AI-powered cloud datawarehouse that delivers the best price-performance for your analytics workloads at any scale. Refer to Easy analytics and cost-optimization with Amazon Redshift Serverless to get started. For this post, we use Redshift Serverless. Choose Run all on each notebook tab.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that lets you analyze your data at scale. Amazon Redshift Serverless lets you access and analyze data without the usual configurations of a provisioned datawarehouse. For more information, refer to Amazon Redshift clusters.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that you can use to analyze your data at scale. With Data API session reuse, you can use a single long-lived session at the start of the ETL pipeline and use that persistent context across all ETL phases.
You can learn how to query Delta Lake native tables through UniForm from different datawarehouses or engines such as Amazon Redshift as an example of expanding data access to more engines. Both Delta Lake and Iceberg metadata files reference the same data files. in Delta Lake public document. Appendix 1.
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. Solution overview Amazon Redshift is an industry-leading cloud datawarehouse.
This puts tremendous stress on the teams managing datawarehouses, and they struggle to keep up with the demand for increasingly advanced analytic requests. To gather and clean data from all internal systems and gain the business insights needed to make smarter decisions, businesses need to invest in datawarehouse automation.
Amazon AppFlow automatically encrypts data in motion, and allows you to restrict data from flowing over the public internet for SaaS applications that are integrated with AWS PrivateLink , reducing exposure to security threats. Refer to the Amazon Redshift Database Developer Guide for more details.
This post was co-written with Dipankar Mazumdar, Staff Data Engineering Advocate with AWS Partner OneHouse. Data architecture has evolved significantly to handle growing data volumes and diverse workloads. For more examples and references to other posts, refer to the following GitHub repository.
With Amazon Redshift, you can use standard SQL to query data across your datawarehouse, operational data stores, and data lake. Migrating a datawarehouse can be complex. You have to migrate terabytes or petabytes of data from your legacy system while not disrupting your production workload.
These types of queries are suited for a datawarehouse. The goal of a datawarehouse is to enable businesses to analyze their data fast; this is important because it means they are able to gain valuable insights in a timely manner. Amazon Redshift is fully managed, scalable, cloud datawarehouse.
Although traditional scaling primarily responds to query queue times, the new AI-driven scaling and optimization feature offers a more sophisticated approach by considering multiple factors including query complexity and data volume. Our findings serve as a reference point rather than a universal benchmark.
Amazon Redshift Serverless makes it simple to run and scale analytics without having to manage your datawarehouse infrastructure. For more details on tagging, refer to Tagging resources overview. For more tagging best practices, refer to Tagging AWS resources. Choose Save changes. About the Authors Sandeep Bajwa is a Sr.
One-time and complex queries are two common scenarios in enterprise data analytics. Complex queries, on the other hand, refer to large-scale data processing and in-depth analysis based on petabyte-level datawarehouses in massive data scenarios. Here, data modeling uses dbt on Amazon Redshift.
Each data source is updated on its own schedule, for example, daily, weekly or monthly. The DataKitchen Platform ingests data into a data lake and runs Recipes to create a datawarehouse leveraged by users and self-service data analysts. The third set of domains are cached data sets (e.g., Conclusion.
SageMaker still includes all the existing ML and AI capabilities you’ve come to know and love for data wrangling, human-in-the-loop data labeling with Amazon SageMaker Ground Truth , experiments, MLOps, Amazon SageMaker HyperPod managed distributed training, and more. The tools to transform your business are here.
The elasticity of Kinesis Data Streams enables you to scale the stream up or down, so you never lose data records before they expire. Analytical data storage The next service in this solution is Amazon Redshift, a fully managed, petabyte-scale datawarehouse service in the cloud.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud that delivers powerful and secure insights on all your data with the best price-performance. With Amazon Redshift, you can analyze your data to derive holistic insights about your business and your customers.
Amazon Redshift is the most widely used datawarehouse in the cloud, best suited for analyzing exabytes of data and running complex analytical queries. Amazon QuickSight is a fast business analytics service to build visualizations, perform ad hoc analysis, and quickly get business insights from your data.
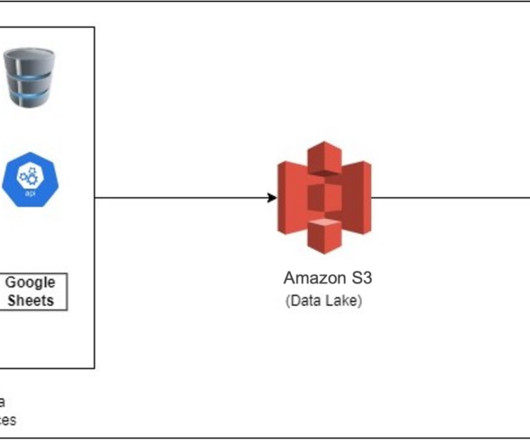
In this post, we discuss how the Kaplan data engineering team implemented data integration from the Salesforce application to Amazon Redshift. Solution overview The high-level data flow starts with the source data stored in Amazon S3 and then integrated into Amazon Redshift using various AWS services.
Business intelligence concepts refer to the usage of digital computing technologies in the form of datawarehouses, analytics and visualization with the aim of identifying and analyzing essential business-based data to generate new, actionable corporate insights. The datawarehouse. 1) The raw data.
Cloudera offers Apache Kudu to run in Real Time DataMart Clusters , and Apache Impala to run in Kubernetes in the Cloudera DataWarehouse form factor. What’s Next For complete setup guide refer to CDW documentation on this topic. To know more about Cloudera DataWarehouse please click here.
To succeed in todays landscape, every company small, mid-sized or large must embrace a data-centric mindset. This article proposes a methodology for organizations to implement a modern data management function that can be tailored to meet their unique needs.
SageMaker Lakehouse is a unified, open, and secure data lakehouse that now supports ABAC to provide unified access to general purpose Amazon S3 buckets, Amazon S3 Tables , Amazon Redshift datawarehouses, and data sources such as Amazon DynamoDB or PostgreSQL. For instructions, refer to Data analyst permissions.
Enterprise data is brought into data lakes and datawarehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on.
Amazon Redshift features like streaming ingestion, Amazon Aurora zero-ETL integration , and data sharing with AWS Data Exchange enable near-real-time processing for trade reporting, risk management, and trade optimization. This will be your OLTP data store for transactional data. version cluster. version cluster.
Dating back to the 1970s, the data warehousing market emerged when computer scientist Bill Inmon first coined the term ‘datawarehouse’. Created as on-premise servers, the early datawarehouses were built to perform on just a gigabyte scale. The post How Will The Cloud Impact Data Warehousing Technologies?
Tens of thousands of customers use Amazon Redshift for modern data analytics at scale, delivering up to three times better price-performance and seven times better throughput than other cloud datawarehouses. Refer to IAM Identity Center identity source tutorials for the IdP setup. IAM Identity Center enabled.
Here is an excerpt from one: “I use SQL daily, and this was a great reference towards using advanced SQL to get analytics insights. It’s something you should have on your desk for reference at all times and the best book on SQL if you want to step outside the box while fine-tuning your technical skills. Viescas, Douglas J.
You can now generate data integration jobs for various data sources and destinations, including Amazon Simple Storage Service (Amazon S3) data lakes with popular file formats like CSV, JSON, and Parquet, as well as modern table formats such as Apache Hudi , Delta , and Apache Iceberg.
but to reference concrete tooling used today in order to ground what could otherwise be a somewhat abstract exercise. Adapted from the book Effective Data Science Infrastructure. Data is at the core of any ML project, so data infrastructure is a foundational concern. Along the way, we’ll provide illustrative examples.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud. With Amazon Redshift, you can analyze all your data to derive holistic insights about your business and your customers. Amazon Redshift now supports custom URLs or custom domain names for your datawarehouse. Choose Create.
Amazon Redshift has established itself as a highly scalable, fully managed cloud datawarehouse trusted by tens of thousands of customers for its superior price-performance and advanced data analytics capabilities. This allows you to maintain a comprehensive view of your data while optimizing for cost-efficiency.
and zero-ETL support) as the source, and a Redshift datawarehouse as the target. The integration replicates data from the source database into the target datawarehouse. Refer to Connect to an Aurora PostgreSQL DB cluster for the options to connect to the PostgreSQL cluster. Choose Next.
New feature: Custom AWS service blueprints Previously, Amazon DataZone provided default blueprints that created AWS resources required for data lake, datawarehouse, and machine learning use cases. If you’re new to Amazon DataZone, refer to Getting started.
Before diving into whether or not Google BigQuery is the future of big data analytics, it’s vital to firstly understand what “big data analytics” actually means. Google BigQuery is a service (within the Google Cloud platform (GCP)) implemented to collect and analyze big data (also known as a datawarehouse).
Amazon Redshift is a fast, fully managed petabyte-scale cloud datawarehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Amazon Redshift also supports querying nested data with complex data types such as struct, array, and map.
In today’s data-driven business environment, organizations face the challenge of efficiently preparing and transforming large amounts of data for analytics and data science purposes. Businesses need to build datawarehouses and data lakes based on operational data.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content