This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud datawarehouses.
Amazon Redshift is a fully managed, AI-powered cloud datawarehouse that delivers the best price-performance for your analytics workloads at any scale. Refer to Easy analytics and cost-optimization with Amazon Redshift Serverless to get started. To test this, let’s ask Amazon Q to “delete data from web_sales table.”
We need robust versioning for data, models, code, and preferably even the internal state of applications—think Git on steroids to answer inevitable questions: What changed? The applications must be integrated to the surrounding business systems so ideas can be tested and validated in the real world in a controlled manner.
Although traditional scaling primarily responds to query queue times, the new AI-driven scaling and optimization feature offers a more sophisticated approach by considering multiple factors including query complexity and data volume. The following screenshots show the elapsed time breakdown for each test.
This post was co-written with Dipankar Mazumdar, Staff Data Engineering Advocate with AWS Partner OneHouse. Data architecture has evolved significantly to handle growing data volumes and diverse workloads. For more examples and references to other posts, refer to the following GitHub repository. create_hudi_s3.py
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. Solution overview Amazon Redshift is an industry-leading cloud datawarehouse.
Each data source is updated on its own schedule, for example, daily, weekly or monthly. The DataKitchen Platform ingests data into a data lake and runs Recipes to create a datawarehouse leveraged by users and self-service data analysts. The third set of domains are cached data sets (e.g.,
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that lets you analyze your data at scale. Amazon Redshift Serverless lets you access and analyze data without the usual configurations of a provisioned datawarehouse. For more information, refer to Amazon Redshift clusters.
This puts tremendous stress on the teams managing datawarehouses, and they struggle to keep up with the demand for increasingly advanced analytic requests. To gather and clean data from all internal systems and gain the business insights needed to make smarter decisions, businesses need to invest in datawarehouse automation.
With the launch of Amazon Redshift Serverless and the various provisioned instance deployment options , customers are looking for tools that help them determine the most optimal datawarehouse configuration to support their Amazon Redshift workloads. The following image shows the process flow.
Many organizations take weeks to procure and prep data sets. A DataOps Engineer can make testdata available on demand. If we can provide shortcuts to members of the data team, we can help improve their productivity. . We have data profiling tools that we run to compare versions of datasets.
With Amazon Redshift, you can use standard SQL to query data across your datawarehouse, operational data stores, and data lake. Migrating a datawarehouse can be complex. You have to migrate terabytes or petabytes of data from your legacy system while not disrupting your production workload.
Amazon Redshift is a widely used, fully managed, petabyte-scale cloud datawarehouse. Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytics workloads. Amazon Redshift RA3 with managed storage is the newest instance type for Provisioned clusters.
Business intelligence concepts refer to the usage of digital computing technologies in the form of datawarehouses, analytics and visualization with the aim of identifying and analyzing essential business-based data to generate new, actionable corporate insights. The datawarehouse. 1) The raw data.
You can now generate data integration jobs for various data sources and destinations, including Amazon Simple Storage Service (Amazon S3) data lakes with popular file formats like CSV, JSON, and Parquet, as well as modern table formats such as Apache Hudi , Delta , and Apache Iceberg.
Amazon Redshift is the most widely used datawarehouse in the cloud, best suited for analyzing exabytes of data and running complex analytical queries. Amazon QuickSight is a fast business analytics service to build visualizations, perform ad hoc analysis, and quickly get business insights from your data.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud that delivers powerful and secure insights on all your data with the best price-performance. With Amazon Redshift, you can analyze your data to derive holistic insights about your business and your customers.
If we understand the data better and derive better insights, it enables us to offer better products and services at greater speed. We have modernized most of our datawarehouses, we have put in new tools and capabilities, and that’s great, because now we’re at this next inflection point of technology with gen AI.
Enterprise data is brought into data lakes and datawarehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. A question arises on what level of details we need to include in the table metadata.
dbt (DataBuildTool) offers this mechanism by introducing a well-structured framework for data analysis, transformation and orchestration. It also applies general software engineering principles like integrating with git repositories, setting up DRYer code, adding functional test cases, and including external libraries.
Amazon Redshift is a fast, petabyte-scale, cloud datawarehouse that tens of thousands of customers rely on to power their analytics workloads. With its massively parallel processing (MPP) architecture and columnar data storage, Amazon Redshift delivers high price-performance for complex analytical queries against large datasets.
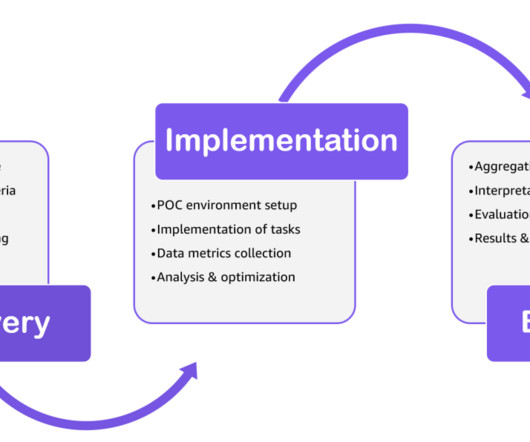
What is Data in Place? Data in Place refers to the organized structuring and storage of data within a specific storage medium, be it a database, bucket store, files, or other storage platforms. This focus on evaluation and testing should be relentless and critical in the ‘last mile’ of the Data Journey.
Data architect Armando Vázquez identifies eight common types of data architects: Enterprise data architect: These data architects oversee an organization’s overall data architecture, defining data architecture strategy and designing and implementing architectures.
times better price-performance than other cloud datawarehouses on real-world workloads using advanced techniques like concurrency scaling to support hundreds of concurrent users, enhanced string encoding for faster query performance, and Amazon Redshift Serverless performance enhancements. Amazon Redshift delivers up to 4.9
As part of the Talent Intelligence Platform Eightfold also exposes a data hub where each customer can access their Amazon Redshift-based datawarehouse and perform ad hoc queries as well as schedule queries for reporting and data export. Many customers have implemented Amazon Redshift to support multi-tenant applications.
Large-scale datawarehouse migration to the cloud is a complex and challenging endeavor that many organizations undertake to modernize their data infrastructure, enhance data management capabilities, and unlock new business opportunities. This makes sure the new data platform can meet current and future business goals.
A point of data entry in a given pipeline. Examples of an origin include storage systems like data lakes, datawarehouses and data sources that include IoT devices, transaction processing applications, APIs or social media. The final point to which the data has to be eventually transferred is a destination.
Tens of thousands of customers run business-critical workloads on Amazon Redshift , AWS’s fast, petabyte-scale cloud datawarehouse delivering the best price-performance. With Amazon Redshift, you can query data across your datawarehouse, operational data stores, and data lake using standard SQL.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing ETL (extract, transform, and load), business intelligence (BI), and reporting tools.
We live in a data-producing world, and as companies want to become data driven, there is the need to analyze more and more data. These analyses are often done using datawarehouses. Status quo before migration Here at OLX Group, Amazon Redshift has been our choice for datawarehouse for over 5 years.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud. You can start with just a few hundred gigabytes of data and scale to a petabyte or more. This enables you to use your data to acquire new insights for your business and customers. For additional details, refer to Automated snapshots.
Statements from countless interviews with our customers reveal that the datawarehouse is seen as a “black box” by many and understood by few business users. Therefore, it is not clear why the costly and apparently flexibility-inhibiting datawarehouse is needed at all. The limiting factor is rather the data landscape.
Amazon Redshift is a popular cloud datawarehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
Today, customers are embarking on data modernization programs by migrating on-premises datawarehouses and data lakes to the AWS Cloud to take advantage of the scale and advanced analytical capabilities of the cloud. In the following sections, we showcase how to configure an AWS Glue Data Quality job for comparison.
Tens of thousands of customers use Amazon Redshift for modern data analytics at scale, delivering up to three times better price-performance and seven times better throughput than other cloud datawarehouses. Refer to IAM Identity Center identity source tutorials for the IdP setup. IAM Identity Center enabled.
Reporting being part of an effective DQM, we will also go through some data quality metrics examples you can use to assess your efforts in the matter. But first, let’s define what data quality actually is. What is the definition of data quality? Why Do You Need Data Quality Management?
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. Complete the implementation tasks such as data ingestion and performance testing.
Load generic address data to Amazon Redshift Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud. Redshift Serverless makes it straightforward to run analytics workloads of any size without having to manage datawarehouse infrastructure.
Amazon Redshift is a widely used, fully managed, petabyte-scale cloud datawarehouse. Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytic workloads. For more information, refer to Migrate Google BigQuery to Amazon Redshift using AWS Schema Conversion tool (SCT).
This post is co-authored by Vijay Gopalakrishnan, Director of Product, Salesforce Data Cloud. In today’s data-driven business landscape, organizations collect a wealth of data across various touch points and unify it in a central datawarehouse or a data lake to deliver business insights.
Amazon Redshift is a fast, fully managed, petabyte-scale datawarehouse that provides the flexibility to use provisioned or serverless compute for your analytical workloads. You can get faster insights without spending valuable time managing your datawarehouse. Fault tolerance is built in.
In 2013, Amazon Web Services revolutionized the data warehousing industry by launching Amazon Redshift , the first fully-managed, petabyte-scale, enterprise-grade cloud datawarehouse. Amazon Redshift made it simple and cost-effective to efficiently analyze large volumes of data using existing business intelligence tools.
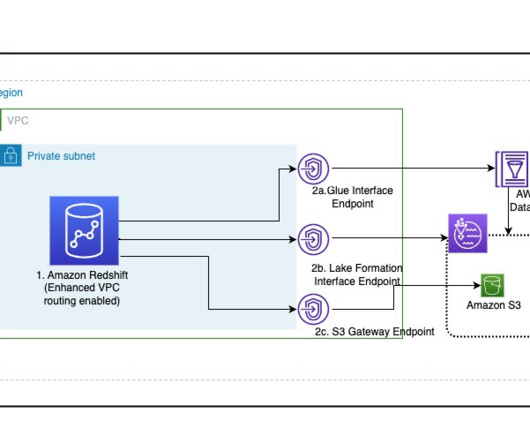
Many customers are extending their datawarehouse capabilities to their data lake with Amazon Redshift. They are looking to further enhance their security posture where they can enforce access policies on their data lakes based on Amazon Simple Storage Service (Amazon S3).
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content