This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Discretization is a fundamental preprocessing technique in data analysis and machinelearning, bridging the gap between continuous data and methods designed for discrete inputs. appeared first on Analytics Vidhya.
Introduction If I had to pick one platform that has single-handedly kept me up-to-date with the latest developments in data science and machinelearning – it would be GitHub.
Introduction The area of machinelearning (ML) is rapidly expanding and has applications across many different sectors. Keeping track of machinelearning experiments using MLflow and managing the trials required to construct them gets harder as they get more complicated.
Introduction Machinelearning has revolutionized the field of data analysis and predictive modelling. With the help of machinelearning libraries, developers and data scientists can easily implement complex algorithms and models without writing extensive code from scratch.
Today, banks realize that data science can significantly speed up these decisions with accurate and targeted predictive analytics. By leveraging the power of automated machinelearning, banks have the potential to make data-driven decisions for products, services, and operations. Brought to you by Data Robot.
Introduction Data science is a rapidly growing tech field that’s transforming business decision-making. These courses cover everything from basic programming to advanced machinelearning. To break into this field, you need the right skills. Fortunately, top institutions like Harvard and IBM offer free online courses.
Introduction Machinelearning (ML) is rapidly transforming various industries. Companies leverage machinelearning to analyze data, predict trends, and make informed decisions. Learning ML has become crucial for anyone interested in a data career. From healthcare to finance, its impact is profound.
Tensors efficiently handle multi-dimensional data, making such innovative projects possible. This article aims to provide readers with […] The post What is Tensor: Key Concepts, Properties, and Uses in MachineLearning appeared first on Analytics Vidhya.
Introduction Are you following the trend or genuinely interested in MachineLearning? Either way, you will need the right resources to TRUST, LEARN and SUCCEED. If you are unable to find the right MachineLearning resource in 2024? We are here to help.
Today, banks realize that data science can significantly speed up these decisions with accurate and targeted predictive analytics. By leveraging the power of automated machinelearning, banks have the potential to make data-driven decisions for products, services, and operations. Brought to you by Data Robot.
Handling missing data is one of the most common challenges in data analysis and machinelearning. Missing values can arise for various reasons, such as errors in data collection, manual omissions, or even the natural absence of information. appeared first on Analytics Vidhya.
Introduction Machinelearning is a rapidly growing field that is transforming industries across sectors. It enables computers to learn from data and make predictions or decisions without being explicitly programmed.
Machinelearning (ML) has become a cornerstone of modern technology, enabling businesses and researchers to make data-driven decisions with greater precision. However, with the vast number of ML models available, choosing the right one for your specific use case can be challenging.
Amid so many different machinelearning algorithms to choose from. This guide has been designed to help you navigate towards the right one for you, depending on your data and the problem to address.
In Data Robot's new ebook, Intelligent Process Automation: Boosting Bots with AI and MachineLearning, we cover important issues related to IPA, including: What is RPA? Brought to you by Data Robots. What is AI? What is IPA? Steps your organization can take to realize the value of IPA. Common IPA use cases.
Python’s versatility and readability have solidified its position as the go-to language for data science, machinelearning, and AI. From data manipulation […] The post Top 50 Python Libraries to Know in 2025 appeared first on Analytics Vidhya.
Data preprocessing remains crucial for machinelearning success, yet real-world datasets often contain errors. Data preprocessing using Cleanlab provides an efficient solution, leveraging its Python package to implement confident learning algorithms. appeared first on Analytics Vidhya.
Linear algebra is a cornerstone of many advanced mathematical concepts and is extensively used in data science, machinelearning, computer vision, and engineering. One of the fundamental concepts in linear algebra is eigenvectors, often paired with eigenvalues. But what exactly is an eigenvector, and why is it so important?
Today’s economy is under pressure from inflation, rising interest rates, and disruptions in the global supply chain. As a result, many organizations are seeking new ways to overcome challenges — to be agile and rapidly respond to constant change. We do not know what the future holds.
Introduction Many contemporary technologies, especially machinelearning, rely heavily on labeled data. The availability and caliber of labeled data strongly influence the […] The post What is Labeled Data? appeared first on Analytics Vidhya.
A key idea in data science and statistics is the Bernoulli distribution, named for the Swiss mathematician Jacob Bernoulli. It is crucial to probability theory and a foundational element for more intricate statistical models, ranging from machinelearning algorithms to customer behaviour prediction.
From customer service chatbots to marketing teams analyzing call center data, the majority of enterprises—about 90% according to recent data —have begun exploring AI. For companies investing in data science, realizing the return on these investments requires embedding AI deeply into business processes.
As you move through the crowd, you catch bits and pieces of two professionals discussing their work—one is a data scientist, who seems to be very passionate about the use of machinelearning in predicting illnesses, the other […] The post Data Science vs. Computer Science: A Comprehensive Guide appeared first on Analytics Vidhya.
Demand for data scientists is surging. With the number of available data science roles increasing by a staggering 650% since 2012, organizations are clearly looking for professionals who have the right combination of computer science, modeling, mathematics, and business skills. Collecting and accessing data from outside sources.
Introduction Data annotation plays a crucial role in the field of machinelearning, enabling the development of accurate and reliable models. In this article, we will explore the various aspects of data annotation, including its importance, types, tools, and techniques.
The normal distribution, also known as the Gaussian distribution, is one of the most widely used probability distributions in statistics and machinelearning. Understanding its core properties, mean and variance, is important for interpreting data and modelling real-world phenomena.
Introduction In the bustling world of machinelearning, categorical data is like the DNA of our datasets – essential yet complex. But how do we make this data comprehensible to our algorithms? Enter One Hot Encoding, the transformative process that turns categorical variables into a language that machines understand.
For all the tasks related to data science and machinelearning, the most important thing that defines how a model will perform depends on how good our data is. Python Pandas and SQL are among the powerful tools that can help in extracting and manipulating data efficiently.
The game-changing potential of artificial intelligence (AI) and machinelearning is well-documented. The new DataRobot whitepaper, Data Science Fails: Building AI You Can Trust, outlines eight important lessons that organizations must understand to follow best data science practices and ensure that AI is being implemented successfully.
A massive community with libraries for machinelearning, sleek app development, data analysis, cybersecurity, and more. This article is […] The post Top 40 Python Libraries for AI, ML and Data Science appeared first on Analytics Vidhya. Python’s superpower?
Data engineering plays a pivotal role in the vast data ecosystem by collecting, transforming, and delivering data essential for analytics, reporting, and machinelearning. Aspiring data engineers often seek real-world projects to gain hands-on experience and showcase their expertise.
Introduction Git is a powerful version control system that plays a crucial role in managing and tracking changes in code for data science projects. Whether you’re working on machinelearning models, data analysis scripts, or collaborative projects, understanding and utilizing Git commands is essential.
Many organizations are dipping their toes into machinelearning and artificial intelligence (AI). MachineLearning Operations (MLOps) allows organizations to alleviate many of the issues on the path to AI with ROI by providing a technological backbone for managing the machinelearning lifecycle through automation and scalability.
This research uses NASA jet engine simulation data to explore a novel method to predictive maintenance. We explore how machinelearning can assess the condition of these vital components […] The post CMAPSS Jet Engine Failure Classification Based On Sensor Data appeared first on Analytics Vidhya.
How can you ensure your machinelearning models get the high-quality data they need to thrive? In todays machinelearning landscape, handling data well is as important as building strong models.
Are you excited to explore the amazing field of data science? The top 10 Free Data Science eBooks are included below, and they cover a wide range of subjects from machinelearning and statistics to advanced themes. You’re in the proper location!
In the quest to reach the full potential of artificial intelligence (AI) and machinelearning (ML), there’s no substitute for readily accessible, high-quality data. If the data volume is insufficient, it’s impossible to build robust ML algorithms. If the data quality is poor, the generated outcomes will be useless.
As machinelearning models are put into production and used to make critical business decisions, the primary challenge becomes operation and management of multiple models.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. Together, these capabilities enable terminal operators to enhance efficiency and competitiveness in an industry that is increasingly data driven.
Introduction Python is the favorite language for most data engineers due to its adaptability and abundance of libraries for various tasks such as manipulation, machinelearning, and data visualization. This post looks at the top 9 Python libraries necessary for data engineers to have successful careers.
One of the points that I look at is whether and to what extent the software provider offers out-of-the-box external data useful for forecasting, planning, analysis and evaluation. Until recently, it was adequate for organizations to regard external data as a nice to have item, but that is no longer the case.
Introduction Incorporating Artificial Intelligence (AI) into Data Analytics has become a revolutionary force in the era of abundant data. It is transforming how businesses get insights from their data reservoirs.
You know you want to invest in artificial intelligence (AI) and machinelearning to take full advantage of the wealth of available data at your fingertips. But rapid change, vendor churn, hype and jargon make it increasingly difficult to choose an AI vendor.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























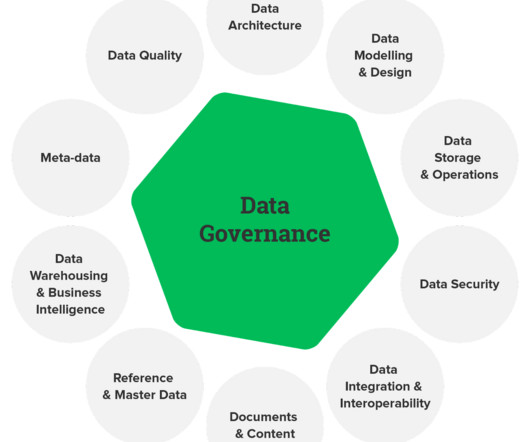
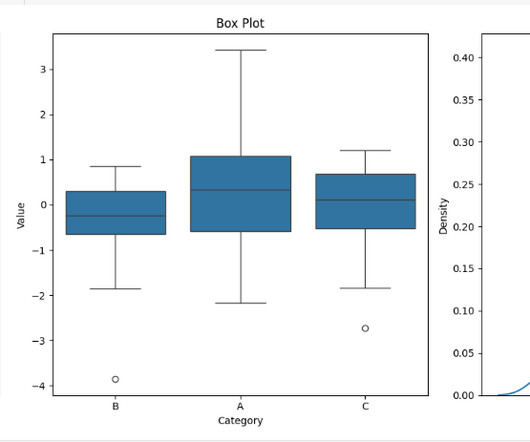




















Let's personalize your content