This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction In this article, we are going to talk about datastreaming with apache spark in Python with codes. We will also talk about how to persist our streamingdata into MongoDB.We
This article was published as a part of the Data Science Blogathon. Introduction When we mention BigData, one of the types of data usually talked about is the StreamingData. StreamingData is generated continuously, by multiple data sources say, sensors, server logs, stock prices, etc.
Introduction Companies can access a large pool of data in the modern business environment, and using this data in real-time may produce insightful results that can spur corporate success. Real-time dashboards such as GCP provide strong data visualization and actionable information for decision-makers.
This guide introduces datastreaming from a data science perspective. Well explain what it is, why it matters, and how to use tools like Apache Kafka, Apache Flink, and PyFlink to build real-time pipelines.
In this guide, we’ll walk through how streaming real-time intent data can supercharge your ABM strategy, including: How streaming real-time intent works The benefits of real-time intent in your ABM strategy How you can box out the competition Learn how capturing buyers’ search behavior in real time can shorten your sales cycle.
In this post, we show how to use Amazon Kinesis DataStreams to buffer and aggregate real-time streamingdata for delivery into Amazon OpenSearch Service domains and collections using Amazon OpenSearch Ingestion. This decoupling provides advantages over traditional architectures.
Overview Streamingdata is a thriving concept in the machine learning space Learn how to use a machine learning model (such as logistic regression). The post How to use a Machine Learning Model to Make Predictions on StreamingData using PySpark appeared first on Analytics Vidhya.
Introduction Welcome to our comprehensive data analysis blog that delves deep into the world of Netflix. As one of the leading streaming platforms globally, Netflix has revolutionized how we consume entertainment. With its vast library of movies and TV shows, it offers an abundance of choices for viewers around the world.
Overview Learn about viewing data as streams of immutable events in contrast to mutable containers Understand how Apache Kafka captures real-time data through event. The post Apache Kafka: A Metaphorical Introduction to Event Streaming for Data Scientists and Data Engineers appeared first on Analytics Vidhya.
A recent Calabrio research study of more than 1,000 C-Suite executives has revealed leaders are missing a key datastream – voice of the customer data. Download the report to learn how executives can find and use VoC data to make more informed business decisions.
Confluent Platform is a streaming platform built by the original creators of Apache Kafka. It enables organizations to organize and manage streamingdata from various sources. Confluent launched its IPO in June this year and raised $828 million to further expand its business.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction This article is in continuation with Part 1 where we discussed Data. The post Image Classification with Tensorflow: Data Augmentation on StreamingData (Part 2) appeared first on Analytics Vidhya.
Enterprises worldwide are harboring massive amounts of data. Although data has always accumulated naturally, the result of ever-growing consumer and business activity, data growth is expanding exponentially, opening opportunities for organizations to monetize unprecedented amounts of information.
Amazon Kinesis Data Analytics for SQL is a datastream processing engine that helps you run your own SQL code against streaming sources to perform time series analytics, feed real-time dashboards, and create real-time metrics. Apache Flink is a distributed open source engine for processing datastreams.
While data platforms, artificial intelligence (AI), machine learning (ML), and programming platforms have evolved to leverage big data and streamingdata, the front-end user experience has not kept up. Traditional Business Intelligence (BI) aren’t built for modern data platforms and don’t work on modern architectures.
Introduction We are aware of the massive amounts of data being produced each day. This humungous data has lots of insights and hidden trends. The post Analysing Streaming Tweets with Python and PostgreSQL appeared first on Analytics Vidhya.
In modern data architectures, Apache Iceberg has emerged as a popular table format for data lakes, offering key features including ACID transactions and concurrent write support. Consider a common scenario: A streaming pipeline continuously writes data to an Iceberg table while scheduled maintenance jobs perform compaction operations.
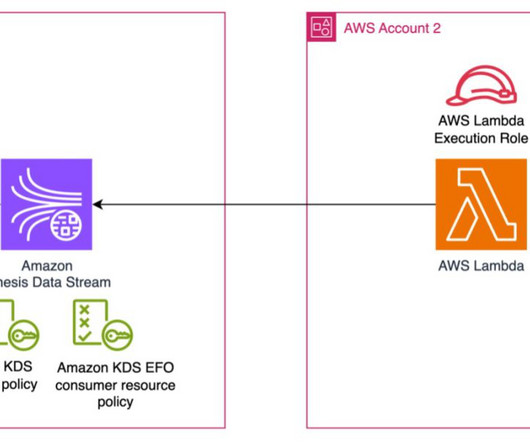
In a streaming architecture, you may have event producers, stream storage, and event consumers in a single account or spread across different accounts depending on your business and IT requirements. Amazon Kinesis DataStreams enables real-time processing of streamingdata at scale.
Amazon Kinesis DataStreams is used by many customers to capture, process, and store datastreams at any scale. This level of unparalleled scale is enabled by dividing each datastream into multiple shards. Each shard in a stream has a 1 Mbps or 1,000 records per second write throughput limit.
Leading brands and local businesses alike are tapping into varied business and consumer data to power their products and meet consumers’ ever-evolving needs. But companies need to remember that a product can only be as good as the data that powers it. The criteria you should use to vet available data sources.
Apache Spark is a powerful big data engine used for large-scale data analytics. You can use Apache Spark to process streamingdata from a variety of streaming sources, including Amazon Kinesis DataStreams for use cases like clickstream analysis, fraud detection, and more.
Introduction Data is fuel for the IT industry and the Data Science Project in today’s online world. IT industries rely heavily on real-time insights derived from streamingdata sources. Handling and processing the streamingdata is the hardest work for Data Analysis.
We’re living in the age of real-time data and insights, driven by low-latency datastreaming applications. The volume of time-sensitive data produced is increasing rapidly, with different formats of data being introduced across new businesses and customer use cases.
Amazon Kinesis DataStreams is a serverless datastreaming service that makes it straightforward to capture and store streamingdata at any scale. By abstracting away these concerns, KCL allows developers to focus on what matters most—implementing their core business logic for processing streamingdata.
Speaker: Azmat Tanauli, Senior Director of Product Strategy at Birst
How much potential revenue is hidden in your data? In a recent Economist survey of 476 senior executives worldwide, 60% are already generating revenue from their data, and a whopping 83% have used data to make existing products or services more profitable.
This article was published as a part of the Data Science Blogathon. Introduction to Apache Flume Apache Flume is a data ingestion mechanism for gathering, aggregating, and transmitting huge amounts of streamingdata from diverse sources, such as log files, events, and so on, to a centralized data storage.
Learn a modern approach to stream real-time data in Jupyter Notebook. This guide covers dynamic visualizations, a Python for quant finance use case, and Bollinger Bands analysis with live data.
Introduction Starting with the fundamentals: What is a datastream, also referred to as an event stream or streamingdata? At its heart, a datastream is a conceptual framework representing a dataset that is perpetually open-ended and expanding.
This article was published as a part of the Data Science Blogathon. Introduction Amazon Kinesis is one of the best-managed services that scale particularly flexibly, especially for processing real-time data at a massive site.
Speaker: Javier Ramírez, Senior AWS Developer Advocate, AWS
You have lots of data, and you are probably thinking of using the cloud to analyze it. But how will you move data into the cloud? How will you validate and prepare the data? What about streamingdata? Can data scientists discover and use the data? Is your data secure? In which format?
Financial services customers are using data from different sources that originate at different frequencies, which includes real time, batch, and archived datasets. Additionally, they need streaming architectures to handle growing trade volumes, market volatility, and regulatory demands. version cluster. version cluster.
This article was published as a part of the Data Science Blogathon. Introduction Data acclimates to countless shapes and sizes to complete its journey from a source to a destination. Be it a streaming job or a batch job, ETL and ELT are irreplaceable.
I was recently asked to identify key modern data architecture trends. Data architectures have changed significantly to accommodate larger volumes of data as well as new types of data such as streaming and unstructured data. Here are some of the trends I see continuing to impact data architectures.
Towards the end of 2022, AWS announced the general availability of real-time streaming ingestion to Amazon Redshift for Amazon Kinesis DataStreams and Amazon Managed Streaming for Apache Kafka (Amazon MSK) , eliminating the need to stage streamingdata in Amazon Simple Storage Service (Amazon S3) before ingesting it into Amazon Redshift.
This article was published as a part of the Data Science Blogathon. Introduction We, as a learner, are in the stage of analyzing the data mostly in the CSV format. Still, we need to understand that at the enterprise level, most of the work is done in real-time, where we need skills to stream live data. […].
Introduction Apache Kafka is a framework for dealing with many real-time datastreams in a way that is spread out. It was made on LinkedIn and shared with the public in 2011.
Amazon Redshift Serverless is a fully managed, scalable cloud data warehouse that accelerates your time to insights with fast, simple, and secure analytics at scale. Amazon Redshift data sharing allows you to share data within and across organizations, AWS Regions, and even third-party providers, without moving or copying the data.
This article was published as a part of the Data Science Blogathon. Introduction Artificial intelligence (AI) is the most dynamic stream in the world. Humans have always been curious about their abilities to predict, understand, act, and make decisions.
Databricks is a data engineering and analytics cloud platform built on top of Apache Spark that processes and transforms huge volumes of data and offers data exploration capabilities through machine learning models. The platform supports streamingdata, SQL queries, graph processing and machine learning.
Whether we are analyzing IoT datastreams, managing scheduled events, processing document uploads, responding to database changes, etc. Azure functions allow developers […] The post How to Develop Serverless Code Using Azure Functions?
Introduction Apache Flume is a tool/service/data ingestion mechanism for gathering, aggregating, and delivering huge amounts of streamingdata from diverse sources, such as log files, events, and so on, to centralized data storage. Flume is a tool that is very dependable, distributed, and customizable.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction One of the major problem everyone face when they first. The post Setting up Real-time Structured Streaming with Spark and Kafka on Windows OS appeared first on Analytics Vidhya.
Data warehousing, business intelligence, data analytics, and AI services are all coming together under one roof at Amazon Web Services. It combines SQL analytics, data processing, AI development, datastreaming, business intelligence, and search analytics.
This article was published as a part of the Data Science Blogathon. Introduction on Apache Flume Apache Flume is a platform for aggregating, collecting, and transporting massive volumes of log data quickly and effectively. Its design is simple, based on streamingdata flows, and written in the Java programming […].
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content