This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article reflects some of what Ive learned. They promise to revolutionize how we interact with data, generating human-quality text, understanding natural language and transforming data in ways we never thought possible. Think about it: LLMs like GPT-3 are incredibly complex deeplearning models trained on massive datasets.
HoloClean decouples the task of data cleaning into error detection (such as recognizing that the location “cicago” is erroneous) and repairing erroneous data (such as changing “cicago” to “Chicago”), and formalizes the fact that “data cleaning is a statisticallearning and inference problem.”
Consider deeplearning, a specific form of machine learning that resurfaced in 2011/2012 due to record-setting models in speech and computer vision. Machine learning is not only appearing in more products and systems, but as we noted in a previous post , ML will also change how applications themselves get built in the future.
Many thanks to Addison-Wesley Professional for providing the permissions to excerpt “Natural Language Processing” from the book, DeepLearning Illustrated by Krohn , Beyleveld , and Bassens. The excerpt covers how to create word vectors and utilize them as an input into a deeplearning model. Introduction.
The good news is that researchers from academia recently managed to leverage that large body of work and combine it with the power of scalable statistical inference for data cleaning. business and quality rules, policies, statistical signals in the data, etc.).
To fully leverage the power of data science, scientists often need to obtain skills in databases, statistical programming tools, and data visualizations. It helps to automate and makes the usage of the R programming statistical language easier and much more effective. perfect for statistical computing and design.
The Bureau of Labor Statistics reports that there are over 105,000 data scientists in the United States. Machine Learning Engineer. As a machine learning engineer, you would create data funnels and deliver software solutions. Are you interested in a career in data science? This is the best time ever to pursue this career track.
The data science path you ultimately choose will depend on your skillset and interests, but each career path will require some level of programming, data visualization, statistics, and machine learning knowledge and skills. On-site courses are available in Munich. Remote courses are also available. Switchup rating: 5.0 (out
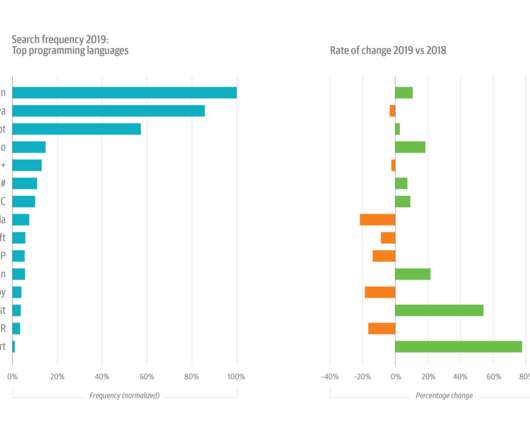
After several years of steady climbing—and after outstripping Java in 2017—Python-related interactions now comprise almost 10% of all usage. As statistics and related techniques become more important in software development, more programmers are encountering stats in programming classes.
The Machine Learning Department at Carnegie Mellon University was founded in 2006 and grew out of the Center for Automated Learning and Discovery (CALD), itself created in 1997 as an interdisciplinary group of researchers with interests in statistics and machine learning. University of California–Berkeley.
It’s a role that requires experience with natural language processing , coding languages, statistical models, and large language and generative AI models. Deeplearning is a subset of AI , and vital to the development of gen AI tools and resources in the enterprise.
People tend to use these phrases almost interchangeably: Artificial Intelligence (AI), Machine Learning (ML) and DeepLearning. DeepLearning is a specific ML technique. Most DeepLearning methods involve artificial neural networks, modeling how our bran works.
AI refers to the autonomous intelligent behavior of software or machines that have a human-like ability to make decisions and to improve over time by learning from experience. Currently, popular approaches include statistical methods, computational intelligence, and traditional symbolic AI. Voice-as-User Interface (VUI).
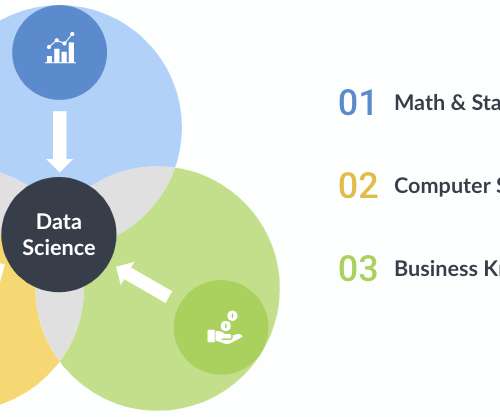
Through a marriage of traditional statistics with fast-paced, code-first computer science doctrine and business acumen, data science teams can solve problems with more accuracy and precision than ever before, especially when combined with soft skills in creativity and communication. Math and Statistics Expertise.
Statistical methods for analyzing this two-dimensional data exist. This statistical test is correct because the data are (presumably) bivariate normal. When there are many variables the Curse of Dimensionality changes the behavior of data and standard statistical methods give the wrong answers. Data Has Properties.
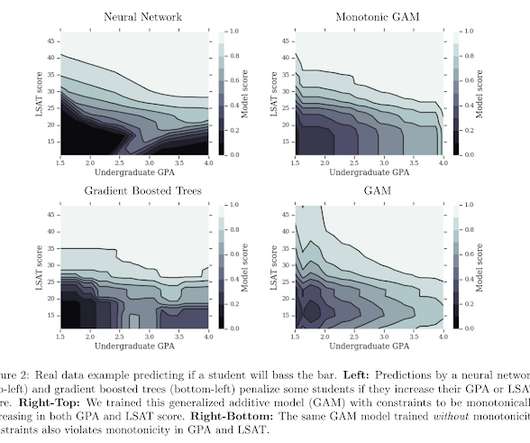
On the one hand, basic statistical models (e.g. On the other hand, sophisticated machine learning models are flexible in their form but not easy to control. The drawback of GAMs is that they do not allow feature interactions. linear regression, trees) can be too rigid in their functional forms.
Thanks to pioneers like Andrew NG and Fei-Fei Li, GPUs have made headlines for performing particularly well with deeplearning techniques. Today, deeplearning and GPUs are practically synonymous. While deeplearning is an excellent use of the processing power of a graphics card, it is not the only use.
Carnegie Mellon University The Machine Learning Department of the School of Computer Science at Carnegie Mellon University was founded in 2006 and grew out of the Center for Automated Learning and Discovery (CALD), itself created in 1997 as an interdisciplinary group of researchers with interests in statistics and machine learning.
From the statistics shown, this means that both AI and big data have the potential to affect how we work in the workplace. Above all, there needs to be a set methodology for data mining, collection, and structure within the organization before data is run through a deeplearning algorithm or machine learning.
Originally created for software development, Python is used in a variety of contexts, including deeplearning research and model deployment. RStudio is an IDE for the R language used primarily for statistical analysis as well as data visualization. Some common IDEs are RStudio and Jupyter Notebook.
It is obvious from the statistics that each customer, facing a bad customer service experience, does more than one step to hurt the business. For example, deeplearning can be used to understand speech and also respond with speech. Think about your bad service experience with a brand and the actions you took after that.
They require a deep enough knowledge of dozens of ML techniques in order to choose the right approach for a given use case, a thorough understanding of everything required to execute on that use case, as well as a solid foundation in statistics fundamentals to ensure their choices and implementations are mathematically sound and appropriate.
Ludwig is a tool that allows people to build data-based deeplearning models to make predictions. It allows secure and interactive SQL analytics at the petabyte scale. Sometimes a data project is most effective if people can interact with the data. Here are some open-source options to consider.
The compact design and touch-based interactivity seemed like a leap into the future. Generative AI represents a significant advancement in deeplearning and AI development, with some suggesting it’s a move towards developing “ strong AI.” Remember how cool it felt when you first held a smartphone in your hand?
When multiple independent but interactive agents are combined, each capable of perceiving the environment and taking actions, you get a multiagent system. Indicium has also built custom connectors for popular messaging platforms, so the agents can better interact with users. And, yes, enterprises are already deploying them.
Early iterations of the AI applications we interact with most today were built on traditional machine learning models. These models rely on learning algorithms that are developed and maintained by data scientists. Due to deeplearning and other advancements, the field of AI remains in a constant and fast-paced state of flux.
When it comes to data analysis, from database operations, data cleaning, data visualization , to machine learning, batch processing, script writing, model optimization, and deeplearning, all these functions can be implemented with Python, and different libraries are provided for you to choose. From Google.
An ML user with statistics training and some basic knowledge of how deeplearning neural networks operate can start with columns of revenue and annuity and generate additional features including mean, standard deviation, and kurtosis to enhance the model training data and thus improve prediction accuracy.
It includes only ML papers and related entities; this SPARQL query shows some statistics: papers tasks models datasets methods evaluations repos 376557 4267 24598 8322 2101 52519 153476 We can start with these repositories (most of them are on Github) and get all their topics. We can start with a connecting dataset like LinkedPapersWithCode.
ML is a computer science, data science and artificial intelligence (AI) subset that enables systems to learn and improve from data without additional programming interventions. A semi-supervised learning model might use unsupervised learning to identify data clusters and then use supervised learning to label the clusters.
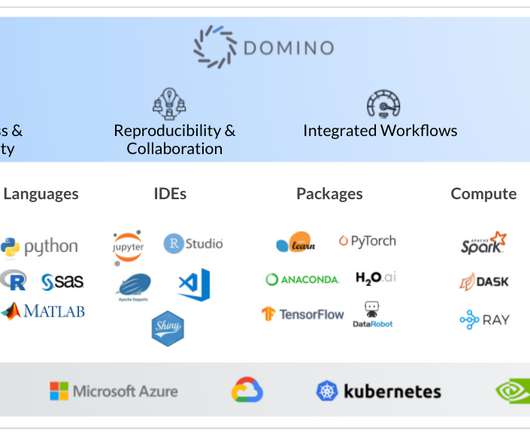
Data science is a field at the convergence of statistics, computer science and business. In this article, take a deep dive into data science and how Domino’s Enterprise MLOps platform allows you to scale data science in your business. In fact, deeplearning was first described theoretically in 1943.
LLMs like ChatGPT are trained on massive amounts of text data, allowing them to recognize patterns and statistical relationships within language. Building an in-house team with AI, deeplearning , machine learning (ML) and data science skills is a strategic move. The AGI research field is constantly evolving.
These methods provided the benefit of being supported by rich literature on the relevant statistical tests to confirm the model’s validity—if a validator wanted to confirm that the input predictors of a regression model were indeed relevant to the response, they need only to construct a hypothesis test to validate the input.
Vendors, service providers and analytics solution companies will package data products and design data management solutions to support business users in their interaction with suppliers, customers and stakeholders, and to inform and support customers and end users as they choose products and options.
This talk will describe how you can navigate all these challenges that you’re going to face and build a business where every product interaction benefits from your investment in machine learning. It used deeplearning to build an automated question answering system and a knowledge base based on that information.
This tradeoff between impact and development difficulty is particularly relevant for products based on deeplearning: breakthroughs often lead to unique, defensible, and highly lucrative products, but investing in products with a high chance of failure is an obvious risk. Prototypes and Data Product MVPs.
Some popular tool libraries and frameworks are: Scikit-Learn: used for machine learning and statistical modeling techniques including classification, regression, clustering and dimensionality reduction and predictive data analysis. PyTorch: used for deeplearning models, like natural language processing and computer vision.
He was saying this doesn’t belong just in statistics. It involved a lot of work with applied math, some depth in statistics and visualization, and also a lot of communication skills. and drop your deeplearning model resource footprint by 5-6 orders of magnitude and run it on devices that don’t even have batteries.
For example, in the case of more recent deeplearning work, a complete explanation might be possible: it might also entail an incomprehensible number of parameters. They also require advanced skills in statistics, experimental design, causal inference, and so on – more than most data science teams will have.
Here is a picture of The New York Times on its birthday in 1851, and for the vast majority of its lifespan this is pretty much what the user experience of interacting with The New York Times looks like. Editors can interact with this bot. You may wonder where would you put a data science group in The New York Times. We crowdsourced it.
We’ve explored usage across all publishing partners and learning modes, from live training courses and online events to interactive functionality provided by Katacoda and Jupyter notebooks. AI, Machine Learning, and Data. We’ve included search data in the graphs, although we have avoided using search data in our analysis.
The spectrum is broad, ranging from process automation using machine learning models to setting up chatbots and performing complex analyses using deeplearning methods. This should ensure that new AI processes interact smoothly with existing systems and applications.
Predictive analytics: Turning insight into foresight Predictive analytics uses historical data and statistical models or machine learning algorithms to answer the question, What is likely to happen? Its a symptom of needing one. This is where analytics begins to proactively impact decision-making.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content