This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Few concepts in mathematics and information theory have profoundly impacted modern machine learning and artificial intelligence, such as the Kullback-Leibler (KL) divergence. This powerful metric, called relative entropy or information gain, has become indispensable in various fields, from statistical inference to deeplearning.
Many thanks to Addison-Wesley Professional for providing the permissions to excerpt “Natural Language Processing” from the book, DeepLearning Illustrated by Krohn , Beyleveld , and Bassens. The excerpt covers how to create word vectors and utilize them as an input into a deeplearning model. Introduction.
Pragmatically, machine learning is the part of AI that “works”: algorithms and techniques that you can implement now in real products. We won’t go into the mathematics or engineering of modern machine learning here. Machine learning adds uncertainty. Even if a product is feasible, that’s not the same as product-market fit.
2) “DeepLearning” by Ian Goodfellow, Yoshua Bengio and Aaron Courville. Best for: This best data science book is especially effective for those looking to enter the data-driven machine learning and deeplearning avenues of the field. “Machine Learning Yearning” by Andrew Ng.
If you’re using Python and deeplearning libraries, the CleverHans and Foolbox packages can also help you debug models and find adversarial examples. For model training and selection, we recommend considering fairness metrics when selecting hyperparameters and decision cutoff thresholds.
It’s the culmination of a decade of work on deeplearning AI. Deeplearning AI: A rising workhorse Deeplearning AI uses the same neural network architecture as generative AI, but can’t understand context, write poems or create drawings. You probably know that ChatGPT wasn’t built overnight.
R is a tool built by statisticians mainly for mathematics, statistics, research, and data analysis. Here, we will implement the XG-Boost algorithm, an algorithm that learns on the basis of training data (which we loaded earlier in both R and Python programming languages) with the help of probability and statistics.
Furthermore, as modeling techniques become increasingly sophisticated in data science, including deeplearning and predictive and generative models, companies and vendors must work diligently to prevent unintentional connections that could leak a person’s identity and expose them to third-party attacks.
They require a deep enough knowledge of dozens of ML techniques in order to choose the right approach for a given use case, a thorough understanding of everything required to execute on that use case, as well as a solid foundation in statistics fundamentals to ensure their choices and implementations are mathematically sound and appropriate.
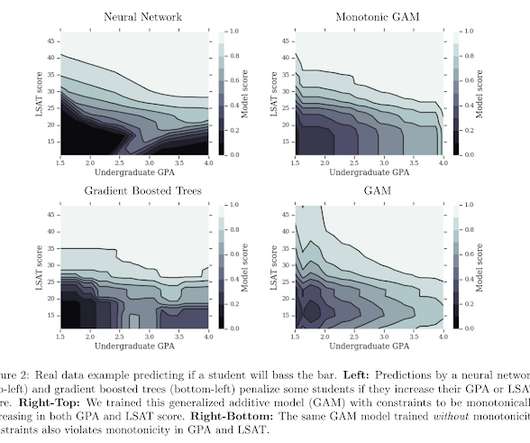
On the one hand, basic statistical models (e.g. On the other hand, sophisticated machine learning models are flexible in their form but not easy to control. More knots make the learned feature transformation smoother and more capable of approximating any monotonic function.
The flashpoint moment is that rather than being based on rules, statistics, and thresholds, now these systems are being imbued with the power of deeplearning and deep reinforcement learning brought about by neural networks,” Mattmann says. We use the same review process for any new enhancements.”
In contrast, the decision tree classifies observations based on attribute splits learned from the statistical properties of the training data. Machine Learning-based detection – using statisticallearning is another approach that is gaining popularity, mostly because it is less laborious. describe().
Areas making up the data science field include mining, statistics, data analytics, data modeling, machine learning modeling and programming. Ultimately, data science is used in defining new business problems that machine learning techniques and statistical analysis can then help solve.
Signal classification models are typically built using time series principles; traditionally used features that include central, windowed, lag, and lead statistics can do the job but sometimes there might be scenarios where we want to eke out more performance out of the data. Image courtesy towardsAI.
Companies with successful ML projects are often companies that already have an experimental culture in place as well as analytics that enable them to learn from data. Ensure that product managers work on projects that matter to the business and/or are aligned to strategic company metrics. That’s another pattern.
These methods provided the benefit of being supported by rich literature on the relevant statistical tests to confirm the model’s validity—if a validator wanted to confirm that the input predictors of a regression model were indeed relevant to the response, they need only to construct a hypothesis test to validate the input.
ML is a computer science, data science and artificial intelligence (AI) subset that enables systems to learn and improve from data without additional programming interventions. To deploy reinforcement learning, an agent takes actions in a specific environment to reach a predetermined goal.
Anomaly detection simply means defining “normal” patterns and metrics—based on business functions and goals—and identifying data points that fall outside of an operation’s normal behavior. Regression modeling is a statistical tool used to find the relationship between labeled data and variable data.
Data science is a field at the convergence of statistics, computer science and business. In this article, take a deep dive into data science and how Domino’s Enterprise MLOps platform allows you to scale data science in your business. In fact, deeplearning was first described theoretically in 1943.
What metrics are used to evaluate success? O’Reilly Media had an earlier survey about deeplearning tools which showed the top three frameworks to be TensorFlow (61% of all respondents), Keras (25%), and PyTorch (20%)—and note that Keras in this case is likely used as an abstraction layer atop TensorFlow.
Machine learning (ML), a subset of artificial intelligence (AI), is an important piece of data-driven innovation. Machine learning engineers take massive datasets and use statistical methods to create algorithms that are trained to find patterns and uncover key insights in data mining projects.
Anomaly Alerts KPI monitoring and Auto Insights allows business users to quickly establish KPIs and target metrics and identify the Key Influencers and variables for the target KPI.
Further, deeplearning methods are built on the foundation of signal processing. The likelihood function measures the goodness of fit of a statistical model to a sample of data for given values of the unknown parameters. The test set is used to evaluate model performance metrics.
The first step in building an AI solution is identifying the problem you want to solve, which includes defining the metrics that will demonstrate whether you’ve succeeded. It sounds simplistic to state that AI product managers should develop and ship products that improve metrics the business cares about. Agreeing on metrics.
First, 82% of the respondents are using supervised learning, and 67% are using deeplearning. Deeplearning is a set of algorithms that are common to almost all AI approaches, so this overlap isn’t surprising. 58% claimed to be using unsupervised learning. Techniques.
Some popular tool libraries and frameworks are: Scikit-Learn: used for machine learning and statistical modeling techniques including classification, regression, clustering and dimensionality reduction and predictive data analysis. PyTorch: used for deeplearning models, like natural language processing and computer vision.
He was saying this doesn’t belong just in statistics. It involved a lot of work with applied math, some depth in statistics and visualization, and also a lot of communication skills. and drop your deeplearning model resource footprint by 5-6 orders of magnitude and run it on devices that don’t even have batteries.
For example, in the case of more recent deeplearning work, a complete explanation might be possible: it might also entail an incomprehensible number of parameters. If your “performance” metrics are focused on predictive power, then you’ll probably end up with more complex models, and consequently less interpretable ones.
AI, Machine Learning, and Data. Healthy growth in artificial intelligence has continued: machine learning is up 14%, while AI is up 64%; data science is up 16%, and statistics is up 47%. While AI and machine learning are distinct concepts, there’s enough confusion about definitions that they’re frequently used interchangeably.
It does this by using statistics about the data together with the query to calculate a cost of executing the query for many different plans. Amazon Redshift has built-in autonomics to collect statistics called automatic analyze (or auto analyze). WHERE l_shipdate >= current_date - $1 AND.
Predictive analytics: Turning insight into foresight Predictive analytics uses historical data and statistical models or machine learning algorithms to answer the question, What is likely to happen? Measure key metrics before model deployment, then track improvements over time. Its a symptom of needing one. Avg deliver time 4.2
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content