This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We gave you a curated list of our top 15 data analytics books , top 18 data visualization books , top 16 SQL books – and, as promised, we’re going to tell you all about the world’s best books on data science. 2) “DeepLearning” by Ian Goodfellow, Yoshua Bengio and Aaron Courville. click for book source**.
Many thanks to Addison-Wesley Professional for providing the permissions to excerpt “Natural Language Processing” from the book, DeepLearning Illustrated by Krohn , Beyleveld , and Bassens. The excerpt covers how to create word vectors and utilize them as an input into a deeplearning model. Introduction.
Image recognition is one of the most relevant areas of machine learning. Deeplearning makes the process efficient. However, not everyone has deeplearning skills or budget resources to spend on GPUs before demonstrating any value to the business. Who Can Benefit from the Visual Data? DataRobot Visual AI.
A playbook for this is to run multiple experiments in parallel and create ‘MVPs’ (fail/learn fast), as well as incorporate feedback mechanisms to enable an improvement loop, and scaling the ones that show the fastest path to ROI. What advances do you see in Visual Analytics in the next five years?
DataOps needs a directed graph-based workflow that contains all the data access, integration, model and visualization steps in the data analytic production process. A complete DataOps program will have a unified, system-wide view of process metrics using a common data store. Meta-Orchestration .
If you’re using Python and deeplearning libraries, the CleverHans and Foolbox packages can also help you debug models and find adversarial examples. For model training and selection, we recommend considering fairness metrics when selecting hyperparameters and decision cutoff thresholds.
Deeplearning enthusiasts are increasingly putting NVIDIA’s GTC at the top of their gotta-be-there conference list. Three of them were particularly compelling and inspired a new point of view on transfer learning that I feel is important for analytical practitioners and leaders to understand. DeepLearning Trends from GTC21.
It’s quite popular for its visualizations: charts, graphs, pictures, and various plots. These visualizations are useful for helping people visualize and understand trends , outliers, and patterns in data. These support a wide array of uses, such as data analysis, manipulation, visualizations, and machine learning (ML) modeling.
When we convert the single channel audio signal time series into an energy spectrogram, it allows us to run state of the art deeplearning architectures on the image. . DataRobot’s Visual AI models in autopilot built a model with an improved 1 percent better performance without any additional parameter tuning.
In our previous post , we talked about how red AI means adding computational power to “buy” more accurate models in machine learning , and especially in deeplearning. We covered different ways of measuring model efficiency and showed ways to visualize this and select models based on it. Conclusion.
The work of a machine learning model developer is highly complex. They need strong data exploration and visualization skills, as well as sufficient data engineering chops to fix the gaps they find in their initial study. Here’s a preview of what you can leverage with one click in CML: DeepLearning for Anomaly Detection.
There are a lot of image annotation techniques that can make the process more efficient with deeplearning. This he’s just one of the many ways that artificial intelligence has significantly improved outcomes that rely on visual media. Consistency and agreement Establish an agreement metric (e.g.,
Next let’s use the displaCy library to visualize the parse tree for that sentence: In [4]: from spacy import displacy?? The displaCy library provides an excellent way to visualize named entities: In [15]: displacy.render(doc, style="ent"). lemma – a root form of the word. part of speech. for a, b in pairs:?.
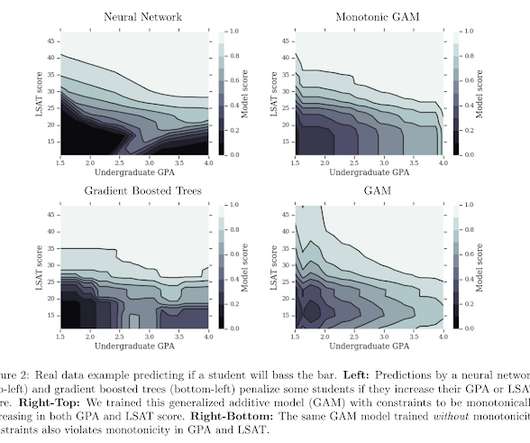
More knots make the learned feature transformation smoother and more capable of approximating any monotonic function. As a result, selecting knots according to the quantiles of the input data (or even linearly across the domain), and then steadily increasing their number as long as the metrics improve works well in practice.
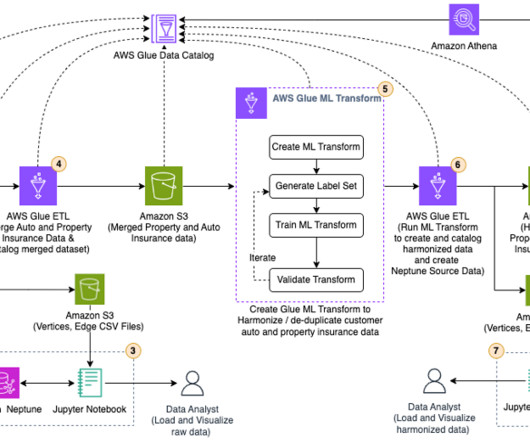
We use Amazon Neptune to visualize the customer data before and after the merge and harmonization. We use Neptune to visualize the customer data before and after the merge and harmonization to see how the transform FindMacthes can bring all related customer data together to get a complete customer 360 view.
The flashpoint moment is that rather than being based on rules, statistics, and thresholds, now these systems are being imbued with the power of deeplearning and deep reinforcement learning brought about by neural networks,” Mattmann says. Adding smarter AI also adds risk, of course.
Top Machine Learning and Data Science Methods Used at Work – The practice of data science requires the use algorithms and data science methods to help data professionals extract insights and value from data. Looking ahead to 2018, data professionals are most interested in learningdeeplearning (41%).
Clustering result on vectors from TF-IDF (2D visualization from UMAP) BERT sentence embedding I then tried using sentence embedding models (BERT) to embed reviews into a vector space where the vectors capture the contextual meaning of sentences. Let’s do a quick deep dive into the model design.
A “comic book” in this context is a story told visually through a series of images, and optionally (though often) in conjunction with written language, e.g., in speech bubbles or as captions. Deeplearning models are data hungry, and state-of-the-art systems like DALL·E 2 are trained with massive data sets of images scraped from the internet.
Data literacy is the ability to understand data science and AI applications critically using basic data visualization, communication, and reasoning skills. rule-based AI , machine learning , deeplearning , etc.) What Is Data Literacy?
Companies with successful ML projects are often companies that already have an experimental culture in place as well as analytics that enable them to learn from data. Ensure that product managers work on projects that matter to the business and/or are aligned to strategic company metrics. That’s another pattern.
Other challenges include communicating results to non-technical stakeholders, ensuring data security, enabling efficient collaboration between data scientists and data engineers, and determining appropriate key performance indicator (KPI) metrics. Python is the most common programming language used in machine learning.
The latter is particularly restricting, as it violates the prerequisite of many deeplearning methods for image classification?—?a They start with different strategies to transform 3-D into 2-D, followed by distinct machine learning approaches. One being the 3-D nature of our images. a large number of training images.
The most common unsupervised learning method is cluster analysis, which uses clustering algorithms to categorize data points according to value similarity (as in customer segmentation or anomaly detection ). To deploy reinforcement learning, an agent takes actions in a specific environment to reach a predetermined goal.
However, with the widespread adoption of modern ML techniques, including gradient-boosted decision trees (GBDTs) and deeplearning algorithms , many traditional validation techniques become difficult or impossible to apply.
Anomaly detection simply means defining “normal” patterns and metrics—based on business functions and goals—and identifying data points that fall outside of an operation’s normal behavior. Unsupervised learning Unsupervised learning techniques do not require labeled data and can handle more complex data sets.
Because our dataset contains image data, DataRobot used models that contain deeplearning based image featurizers. Typically this means finding out how many predictions have been made, how many requests have been made to the deployment, and other performance-related metrics. Activation Maps.
What metrics are used to evaluate success? O’Reilly Media had an earlier survey about deeplearning tools which showed the top three frameworks to be TensorFlow (61% of all respondents), Keras (25%), and PyTorch (20%)—and note that Keras in this case is likely used as an abstraction layer atop TensorFlow.
Machine learning algorithms like Naïve Bayes and support vector machines (SVM), and deeplearning models like convolutional neural networks (CNN) are frequently used for text classification. If necessary, make adjustments to the preprocessing, representation and/or modeling steps to improve the results.
Anomaly Alerts KPI monitoring and Auto Insights allows business users to quickly establish KPIs and target metrics and identify the Key Influencers and variables for the target KPI.
An interview with Pranshuk Kathed, machine and deeplearning enthusiast. For simple reporting projects, I might spend 8 hours getting the right data and then just a couple of hours producing the needed visualizations. What are the metrics that business wants to see and why it is valuable? Were you prepared for that?
MLOps is the next evolution of data analysis and deeplearning. Simply put, MLOps uses machine learning to make machine learning more efficient. Generative AI is a type of deep-learning model that takes raw data, processes it and “learns” to generate probable outputs.
CNNs have been widely considered state-of-the-art tools for computer vision since 2012, when AlexNet won the ImageNet Large Scale Visual Recognition Challenge (ILSVRC). Keras is an open source deeplearning API that was written in Python and runs on top of Tensorflow, so it’s a little more user-friendly and high-level than Tensorflow.
Communication cannot be emphasized enough, for it is this trait that ensures results are effectively translated from the white board to impact on business metrics. In fact, deeplearning was first described theoretically in 1943. None of these techniques are new.
Visualize Glassdoor reviews from your dream companies Yanxia Li built CompanySnapshot, a tool to help individuals visualize Glassdoor employee reviews, reducing the time needed to thoroughly review a company’s Glassdoor profile. xPea allows users to discover these and other surprising matches as they search for their dream jobs.
DataRobot also processes nearly every type of data , such as satellite and street imagery of real estate properties using DataRobot Visual AI , the latitude and longitude of properties and nearby city’s points of interest using DataRobot Location AI , tweets, and reviews with geotagged locations using DataRobot Text AI.
First, 82% of the respondents are using supervised learning, and 67% are using deeplearning. Deeplearning is a set of algorithms that are common to almost all AI approaches, so this overlap isn’t surprising. 58% claimed to be using unsupervised learning. Techniques.
The interest in interpretation of machine learning has been rapidly accelerating in the last decade. This can be attributed to the popularity that machine learning algorithms, and more specifically deeplearning, has been gaining in various domains. Methods for explaining DeepLearning.
On the other hand, as Lipton emphasized, while the tooling produces interesting visualizations, visualizations do not imply interpretation. ML model interpretability and data visualization. From my experiences leading data teams, when a business is facing difficult challenges, data visualizations can help or hurt.
This article provides an excerpt “Deep Reinforcement Learning” from the book, DeepLearning Illustrated by Krohn , Beyleveld , and Bassens. The article includes an overview of reinforcement learning theory with focus on the deep Q-learning. metrics simultaneously.
He also really informed a lot of the early thinking about data visualization. It involved a lot of work with applied math, some depth in statistics and visualization, and also a lot of communication skills. They’d like to do something more efficient when they’re training a lot of deeplearning models.
These are your standard reports and dashboard visualizations of historical data showing sales last quarter, NPS trends, operational thoughts or marketing campaign performance. Todays self-service platforms enable business users to slice and dice data, create visualizations and build basic predictive models.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content