This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Optimization aims to reduce training errors, and DeepLearning Optimization is concerned with finding a suitable model. Another goal of optimization in deeplearning is to minimize generalization errors. The post Introduction to Linear Model for Optimization appeared first on Analytics Vidhya.
Introduction Few concepts in mathematics and information theory have profoundly impacted modern machine learning and artificial intelligence, such as the Kullback-Leibler (KL) divergence. This powerful metric, called relative entropy or information gain, has become indispensable in various fields, from statistical inference to deeplearning.
Finding a deeplearningmodel to perform well is an exciting feat. But, might there be other -- less complex -- models that perform just as well for your application?
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction In Machine learning or DeepLearning, some of the models. The post How to transform features into Normal/Gaussian Distribution appeared first on Analytics Vidhya.
Many thanks to Addison-Wesley Professional for providing the permissions to excerpt “Natural Language Processing” from the book, DeepLearning Illustrated by Krohn , Beyleveld , and Bassens. The excerpt covers how to create word vectors and utilize them as an input into a deeplearningmodel.
Supervised learning is the most popular ML technique among mature AI adopters, while deeplearning is the most popular technique among organizations that are still evaluating AI. The logic in this case partakes of garbage-in, garbage out : data scientists and ML engineers need quality data to train their models.
Apply fair and private models, white-hat and forensic model debugging, and common sense to protect machine learningmodels from malicious actors. Like many others, I’ve known for some time that machine learningmodels themselves could pose security risks.
New tools are constantly being added to the deeplearning ecosystem. For example, there have been multiple promising tools created recently that have Python APIs, are built on top of TensorFlow or PyTorch , and encapsulate deeplearning best practices to allow data scientists to speed up research.
In this post, I demonstrate how deeplearning can be used to significantly improve upon earlier methods, with an emphasis on classifying short sequences as being human, viral, or bacterial. As I discovered, deeplearning is a powerful tool for short sequence classification and is likely to be useful in many other applications as well.
Introduction Long Short Term Memory (LSTM) is a type of deeplearning system that anticipates property leases. Rental markets are influenced by diverse factors, and LSTM’s ability to capture and remember […] The post A Deep Dive into LSTM Neural Network-based House Rent Prediction appeared first on Analytics Vidhya.
Not least is the broadening realization that ML models can fail. And that’s why model debugging, the art and science of understanding and fixing problems in ML models, is so critical to the future of ML. Because all ML models make mistakes, everyone who cares about ML should also care about model debugging. [1]
There has been a significant increase in our ability to build complex AI models for predictions, classifications, and various analytics tasks, and there’s an abundance of (fairly easy-to-use) tools that allow data scientists and analysts to provision complex models within days. Data integration and cleaning.
For a model-driven enterprise, having access to the appropriate tools can mean the difference between operating at a loss with a string of late projects lingering ahead of you or exceeding productivity and profitability forecasts. What Are Modeling Tools? Importance of Modeling Tools. Types of Modeling Tools.
These AI applications are essentially deep machine learningmodels that are trained on hundreds of gigabytes of text and that can provide detailed, grammatically correct, and “mostly accurate” text responses to user inputs (questions, requests, or queries, which are called prompts). Guess what? It isn’t.
You must detect when the model has become stale, and retrain it as necessary. Products based on deeplearning can be difficult (or even impossible) to develop; it’s a classic “high return versus high risk” situation, in which it is inherently difficult to calculate return on investment.
Relatively few respondents are using version control for data and models. Tools for versioning data and models are still immature, but they’re critical for making AI results reproducible and reliable. The biggest skills gaps were ML modelers and data scientists (52%), understanding business use cases (49%), and data engineering (42%).
This week on KDnuggets: Go from learning what large language models are to building and deploying LLM apps in 7 steps • Check this list of free books for learning Python, statistics, linear algebra, machine learning and deeplearning • And much, much more!
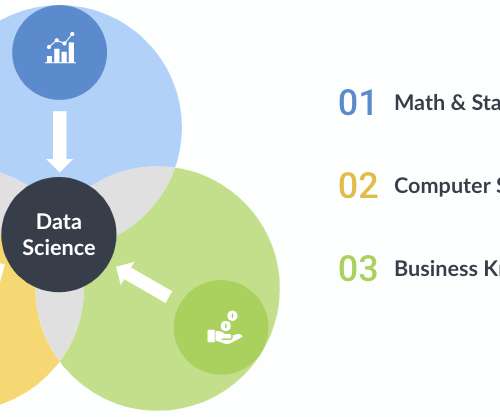
Data scientists use algorithms for creating data models. These data models predict outcomes of new data. Data science needs knowledge from a variety of fields including statistics, mathematics, programming, and transforming data. Mathematics, statistics, and programming are pillars of data science. Statistics.
To fully leverage the power of data science, scientists often need to obtain skills in databases, statistical programming tools, and data visualizations. It helps to automate and makes the usage of the R programming statistical language easier and much more effective. perfect for statistical computing and design.
Pragmatically, machine learning is the part of AI that “works”: algorithms and techniques that you can implement now in real products. We won’t go into the mathematics or engineering of modern machine learning here. Machine learning adds uncertainty. This shift requires a fundamental change in your software engineering practice.
The data science path you ultimately choose will depend on your skillset and interests, but each career path will require some level of programming, data visualization, statistics, and machine learning knowledge and skills. It culminates with a capstone project that requires creating a machine learningmodel.
The Machine Learning Department at Carnegie Mellon University was founded in 2006 and grew out of the Center for Automated Learning and Discovery (CALD), itself created in 1997 as an interdisciplinary group of researchers with interests in statistics and machine learning. University of California–Berkeley.
The chief aim of data analytics is to apply statistical analysis and technologies on data to find trends and solve problems. Data analytics draws from a range of disciplines — including computer programming, mathematics, and statistics — to perform analysis on data in an effort to describe, predict, and improve performance.
Responsibilities include building predictive modeling solutions that address both client and business needs, implementing analytical models alongside other relevant teams, and helping the organization make the transition from traditional software to AI infused software.
Generative AI and large language models (LLMs) like ChatGPT are only one aspect of AI. It’s the culmination of a decade of work on deeplearning AI. Model sizes: ~5 billion to >1 trillion parameters. Model sizes: ~Millions to billions of parameters. AI encompasses many things.
People tend to use these phrases almost interchangeably: Artificial Intelligence (AI), Machine Learning (ML) and DeepLearning. DeepLearning is a specific ML technique. Most DeepLearning methods involve artificial neural networks, modeling how our bran works.
Predictive analytics definition Predictive analytics is a category of data analytics aimed at making predictions about future outcomes based on historical data and analytics techniques such as statisticalmodeling and machine learning. Financial services: Develop credit risk models. from 2022 to 2028.
Predictive analytics, sometimes referred to as big data analytics, relies on aspects of data mining as well as algorithms to develop predictive models. These predictive models can be used by enterprise marketers to more effectively develop predictions of future user behaviors based on the sourced historical data. Objectives and Usage.
Imagine diving into the details of data analysis, predictive modeling, and ML. Envision yourself unraveling the insights and patterns for making informed decisions that shape the future. The concept of Data Science was first used at the start of the 21st century, making it a relatively new area of research and technology.
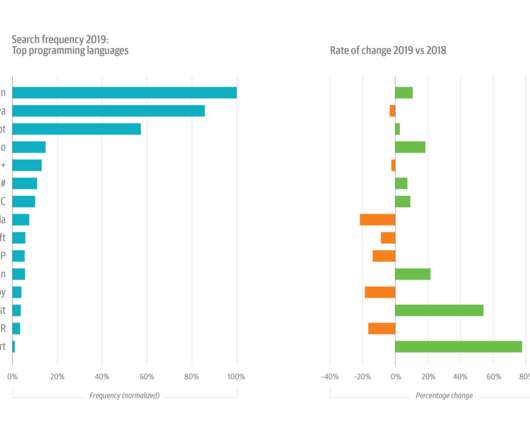
Usage specific to Python as a programming language grew by just 4% in 2019; by contrast, usage that had to do with Python and ML—be it in the context of AI, deeplearning, and natural language processing, or in combination with any of several popular ML/AI frameworks—grew by 9%.
Statistical methods for analyzing this two-dimensional data exist. This statistical test is correct because the data are (presumably) bivariate normal. When there are many variables the Curse of Dimensionality changes the behavior of data and standard statistical methods give the wrong answers. Data Has Properties.
Through a marriage of traditional statistics with fast-paced, code-first computer science doctrine and business acumen, data science teams can solve problems with more accuracy and precision than ever before, especially when combined with soft skills in creativity and communication. Math and Statistics Expertise.
When you hear about Data Science, Big Data, Analytics, Artificial Intelligence, Machine Learning, or DeepLearning, you may end up feeling a bit confused about what these terms mean. A foundational data analysis tool is Statistics , and everyone intuitively applies it daily. So, what do these terms really mean?
Models are the central output of data science, and they have tremendous power to transform companies, industries, and society. At the center of every machine learning or artificial intelligence application is the ML/AI model that is built with data, algorithms and code. The process of creating models is called modeling.
R is a tool built by statisticians mainly for mathematics, statistics, research, and data analysis. These support a wide array of uses, such as data analysis, manipulation, visualizations, and machine learning (ML) modeling. Some standard Python libraries are Pandas, Numpy, Scikit-Learn, SciPy, and Matplotlib.
This article reflects some of what Ive learned. The hype around large language models (LLMs) is undeniable. Think about it: LLMs like GPT-3 are incredibly complex deeplearningmodels trained on massive datasets. Even basic predictive modeling can be done with lightweight machine learning in Python or R.
With that being said, let’s have a closer look at how unsupervised machine learning is omnipresent in all industries. What Is Unsupervised Machine Learning? If you’ve ever come across deeplearning, you might have heard about two methods to teach machines: supervised and unsupervised. Unsupervised ML: The Basics.
The US Bureau of Labor Statistics (BLS) forecasts employment of data scientists will grow 35% from 2022 to 2032, with about 17,000 openings projected on average each year. You need experience in machine learning and predictive modeling techniques, including their use with big, distributed, and in-memory data sets.
Carnegie Mellon University The Machine Learning Department of the School of Computer Science at Carnegie Mellon University was founded in 2006 and grew out of the Center for Automated Learning and Discovery (CALD), itself created in 1997 as an interdisciplinary group of researchers with interests in statistics and machine learning.
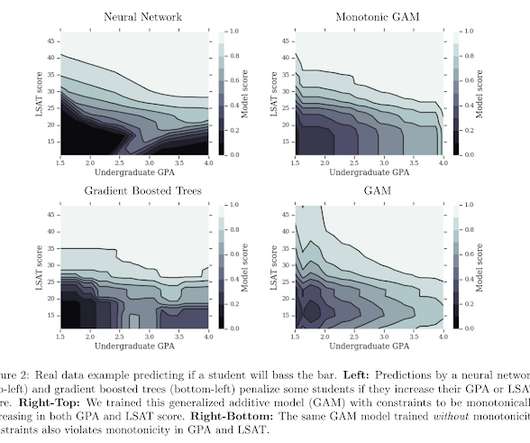
by TAMAN NARAYAN & SEN ZHAO A data scientist is often in possession of domain knowledge which she cannot easily apply to the structure of the model. On the one hand, basic statisticalmodels (e.g. On the other hand, sophisticated machine learningmodels are flexible in their form but not easy to control.
Thanks to pioneers like Andrew NG and Fei-Fei Li, GPUs have made headlines for performing particularly well with deeplearning techniques. Today, deeplearning and GPUs are practically synonymous. While deeplearning is an excellent use of the processing power of a graphics card, it is not the only use.
These data science tools are used for doing such things as accessing, cleaning and transforming data, exploratory analysis, creating models, monitoring models and embedding them in external systems. RStudio is an IDE for the R language used primarily for statistical analysis as well as data visualization.
My story seems to reflect that: From my first steps in sentiment analysis and topic modelling, through building recommender systems while dabbling in Kaggle competitions and deeplearning a few years ago, and to my present-day interest in causal inference. Moving forward in my PhD, I got into topic modelling.
Transformer models take applications such as language translation and chatbots to a new level. Innovations such as the self-attention mechanism and multi-head attention enable these models to better weigh the importance of various parts of the input, and to process those parts in parallel rather than sequentially.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content